 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Shortcuts in Graph Neural Controlled Differential Equations
Oct 25, 2024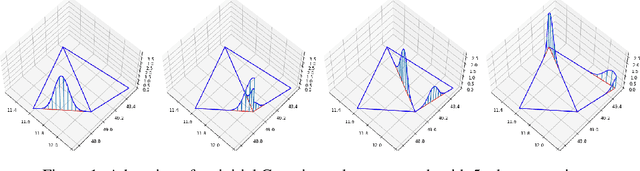


We incorporate prior graph topology information into a Neural Controlled Differential Equation (NCDE) to predict the future states of a dynamical system defined on a graph. The informed NCDE infers the future dynamics at the vertices of simulated advection data on graph edges with a known causal graph, observed only at vertices during training. We investigate different positions in the model architecture to inform the NCDE with graph information and identify an outer position between hidden state and control as theoretically and empirically favorable. Our such informed NCDE requires fewer parameters to reach a lower Mean Absolute Error (MAE) compared to previous methods that do not incorporate additional graph topology information.
Generative Fractional Diffusion Models
Oct 26, 2023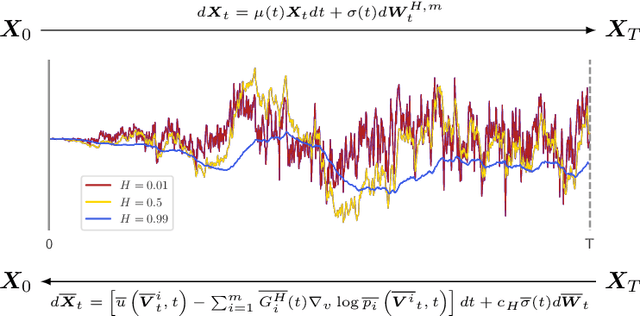

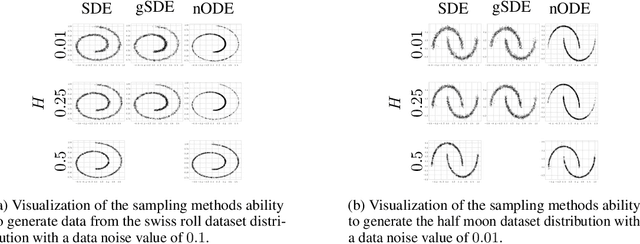

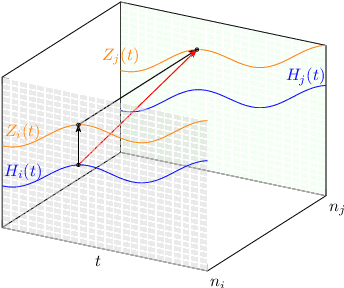
We generalize the continuous time framework for score-based generative models from an underlying Brownian motion (BM) to an approximation of fractional Brownian motion (FBM). We derive a continuous reparameterization trick and the reverse time model by representing FBM as a stochastic integral over a family of Ornstein-Uhlenbeck processes to define generative fractional diffusion models (GFDM) with driving noise converging to a non-Markovian process of infinite quadratic variation. The Hurst index $H\in(0,1)$ of FBM enables control of the roughness of the distribution transforming path. To the best of our knowledge, this is the first attempt to build a generative model upon a stochastic process with infinite quadratic variation.
DiffInfinite: Large Mask-Image Synthesis via Parallel Random Patch Diffusion in Histopathology
Jun 23, 2023



We present DiffInfinite, a hierarchical diffusion model that generates arbitrarily large histological images while preserving long-range correlation structural information. Our approach first generates synthetic segmentation masks, subsequently used as conditions for the high-fidelity generative diffusion process. The proposed sampling method can be scaled up to any desired image size while only requiring small patches for fast training. Moreover, it can be parallelized more efficiently than previous large-content generation methods while avoiding tiling artefacts. The training leverages classifier-free guidance to augment a small, sparsely annotated dataset with unlabelled data. Our method alleviates unique challenges in histopathological imaging practice: large-scale information, costly manual annotation, and protective data handling. The biological plausibility of DiffInfinite data is validated in a survey by ten experienced pathologists as well as a downstream segmentation task. Furthermore, the model scores strongly on anti-copying metrics which is beneficial for the protection of patient data.
Data Models for Dataset Drift Controls in Machine Learning With Images
Nov 04, 2022



Camera images are ubiquitous in machine learning research. They also play a central role in the delivery of important services spanning medicine and environmental surveying. However, the application of machine learning models in these domains has been limited because of robustness concerns. A primary failure mode are performance drops due to differences between the training and deployment data. While there are methods to prospectively validate the robustness of machine learning models to such dataset drifts, existing approaches do not account for explicit models of the primary object of interest: the data. This makes it difficult to create physically faithful drift test cases or to provide specifications of data models that should be avoided when deploying a machine learning model. In this study, we demonstrate how these shortcomings can be overcome by pairing machine learning robustness validation with physical optics. We examine the role raw sensor data and differentiable data models can play in controlling performance risks related to image dataset drift. The findings are distilled into three applications. First, drift synthesis enables the controlled generation of physically faithful drift test cases. The experiments presented here show that the average decrease in model performance is ten to four times less severe than under post-hoc augmentation testing. Second, the gradient connection between task and data models allows for drift forensics that can be used to specify performance-sensitive data models which should be avoided during deployment of a machine learning model. Third, drift adjustment opens up the possibility for processing adjustments in the face of drift. This can lead to speed up and stabilization of classifier training at a margin of up to 20% in validation accuracy. A guide to access the open code and datasets is available at https://github.com/aiaudit-org/raw2logit.