 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtlas-Alignment: Making Interpretability Transferable Across Language Models
Oct 31, 2025Interpretability is crucial for building safe, reliable, and controllable language models, yet existing interpretability pipelines remain costly and difficult to scale. Interpreting a new model typically requires costly training of model-specific sparse autoencoders, manual or semi-automated labeling of SAE components, and their subsequent validation. We introduce Atlas-Alignment, a framework for transferring interpretability across language models by aligning unknown latent spaces to a Concept Atlas - a labeled, human-interpretable latent space - using only shared inputs and lightweight representational alignment techniques. Once aligned, this enables two key capabilities in previously opaque models: (1) semantic feature search and retrieval, and (2) steering generation along human-interpretable atlas concepts. Through quantitative and qualitative evaluations, we show that simple representational alignment methods enable robust semantic retrieval and steerable generation without the need for labeled concept data. Atlas-Alignment thus amortizes the cost of explainable AI and mechanistic interpretability: by investing in one high-quality Concept Atlas, we can make many new models transparent and controllable at minimal marginal cost.
LieSolver: A PDE-constrained solver for IBVPs using Lie symmetries
Oct 29, 2025We introduce a method for efficiently solving initial-boundary value problems (IBVPs) that uses Lie symmetries to enforce the associated partial differential equation (PDE) exactly by construction. By leveraging symmetry transformations, the model inherently incorporates the physical laws and learns solutions from initial and boundary data. As a result, the loss directly measures the model's accuracy, leading to improved convergence. Moreover, for well-posed IBVPs, our method enables rigorous error estimation. The approach yields compact models, facilitating an efficient optimization. We implement LieSolver and demonstrate its application to linear homogeneous PDEs with a range of initial conditions, showing that it is faster and more accurate than physics-informed neural networks (PINNs). Overall, our method improves both computational efficiency and the reliability of predictions for PDE-constrained problems.
Attribution-guided Pruning for Compression, Circuit Discovery, and Targeted Correction in LLMs
Jun 16, 2025Large Language Models (LLMs) are central to many contemporary AI applications, yet their extensive parameter counts pose significant challenges for deployment in memory- and compute-constrained environments. Recent works in eXplainable AI (XAI), particularly on attribution methods, suggest that interpretability can also enable model compression by identifying and removing components irrelevant to inference. In this paper, we leverage Layer-wise Relevance Propagation (LRP) to perform attribution-guided pruning of LLMs. While LRP has shown promise in structured pruning for vision models, we extend it to unstructured pruning in LLMs and demonstrate that it can substantially reduce model size with minimal performance loss. Our method is especially effective in extracting task-relevant subgraphs -- so-called ``circuits'' -- which can represent core functions (e.g., indirect object identification). Building on this, we introduce a technique for model correction, by selectively removing circuits responsible for spurious behaviors (e.g., toxic outputs). All in all, we gather these techniques as a uniform holistic framework and showcase its effectiveness and limitations through extensive experiments for compression, circuit discovery and model correction on Llama and OPT models, highlighting its potential for improving both model efficiency and safety. Our code is publicly available at https://github.com/erfanhatefi/SparC3.
Deep Learning-based Multi Project InP Wafer Simulation for Unsupervised Surface Defect Detection
Jun 12, 2025Quality management in semiconductor manufacturing often relies on template matching with known golden standards. For Indium-Phosphide (InP) multi-project wafer manufacturing, low production scale and high design variability lead to such golden standards being typically unavailable. Defect detection, in turn, is manual and labor-intensive. This work addresses this challenge by proposing a methodology to generate a synthetic golden standard using Deep Neural Networks, trained to simulate photo-realistic InP wafer images from CAD data. We evaluate various training objectives and assess the quality of the simulated images on both synthetic data and InP wafer photographs. Our deep-learning-based method outperforms a baseline decision-tree-based approach, enabling the use of a 'simulated golden die' from CAD plans in any user-defined region of a wafer for more efficient defect detection. We apply our method to a template matching procedure, to demonstrate its practical utility in surface defect detection.
Relevance-driven Input Dropout: an Explanation-guided Regularization Technique
May 27, 2025Overfitting is a well-known issue extending even to state-of-the-art (SOTA) Machine Learning (ML) models, resulting in reduced generalization, and a significant train-test performance gap. Mitigation measures include a combination of dropout, data augmentation, weight decay, and other regularization techniques. Among the various data augmentation strategies, occlusion is a prominent technique that typically focuses on randomly masking regions of the input during training. Most of the existing literature emphasizes randomness in selecting and modifying the input features instead of regions that strongly influence model decisions. We propose Relevance-driven Input Dropout (RelDrop), a novel data augmentation method which selectively occludes the most relevant regions of the input, nudging the model to use other important features in the prediction process, thus improving model generalization through informed regularization. We further conduct qualitative and quantitative analyses to study how Relevance-driven Input Dropout (RelDrop) affects model decision-making. Through a series of experiments on benchmark datasets, we demonstrate that our approach improves robustness towards occlusion, results in models utilizing more features within the region of interest, and boosts inference time generalization performance. Our code is available at https://github.com/Shreyas-Gururaj/LRP_Relevance_Dropout.
From What to How: Attributing CLIP's Latent Components Reveals Unexpected Semantic Reliance
May 26, 2025



Transformer-based CLIP models are widely used for text-image probing and feature extraction, making it relevant to understand the internal mechanisms behind their predictions. While recent works show that Sparse Autoencoders (SAEs) yield interpretable latent components, they focus on what these encode and miss how they drive predictions. We introduce a scalable framework that reveals what latent components activate for, how they align with expected semantics, and how important they are to predictions. To achieve this, we adapt attribution patching for instance-wise component attributions in CLIP and highlight key faithfulness limitations of the widely used Logit Lens technique. By combining attributions with semantic alignment scores, we can automatically uncover reliance on components that encode semantically unexpected or spurious concepts. Applied across multiple CLIP variants, our method uncovers hundreds of surprising components linked to polysemous words, compound nouns, visual typography and dataset artifacts. While text embeddings remain prone to semantic ambiguity, they are more robust to spurious correlations compared to linear classifiers trained on image embeddings. A case study on skin lesion detection highlights how such classifiers can amplify hidden shortcuts, underscoring the need for holistic, mechanistic interpretability. We provide code at https://github.com/maxdreyer/attributing-clip.
The Atlas of In-Context Learning: How Attention Heads Shape In-Context Retrieval Augmentation
May 21, 2025Large language models are able to exploit in-context learning to access external knowledge beyond their training data through retrieval-augmentation. While promising, its inner workings remain unclear. In this work, we shed light on the mechanism of in-context retrieval augmentation for question answering by viewing a prompt as a composition of informational components. We propose an attribution-based method to identify specialized attention heads, revealing in-context heads that comprehend instructions and retrieve relevant contextual information, and parametric heads that store entities' relational knowledge. To better understand their roles, we extract function vectors and modify their attention weights to show how they can influence the answer generation process. Finally, we leverage the gained insights to trace the sources of knowledge used during inference, paving the way towards more safe and transparent language models.
Prisma: An Open Source Toolkit for Mechanistic Interpretability in Vision and Video
Apr 28, 2025Robust tooling and publicly available pre-trained models have helped drive recent advances in mechanistic interpretability for language models. However, similar progress in vision mechanistic interpretability has been hindered by the lack of accessible frameworks and pre-trained weights. We present Prisma (Access the codebase here: https://github.com/Prisma-Multimodal/ViT-Prisma), an open-source framework designed to accelerate vision mechanistic interpretability research, providing a unified toolkit for accessing 75+ vision and video transformers; support for sparse autoencoder (SAE), transcoder, and crosscoder training; a suite of 80+ pre-trained SAE weights; activation caching, circuit analysis tools, and visualization tools; and educational resources. Our analysis reveals surprising findings, including that effective vision SAEs can exhibit substantially lower sparsity patterns than language SAEs, and that in some instances, SAE reconstructions can decrease model loss. Prisma enables new research directions for understanding vision model internals while lowering barriers to entry in this emerging field.
ASIDE: Architectural Separation of Instructions and Data in Language Models
Mar 13, 2025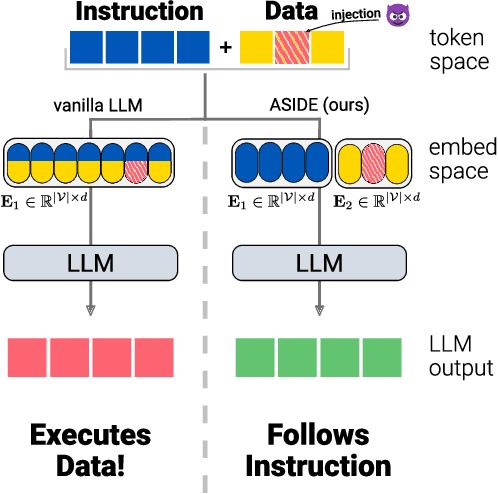
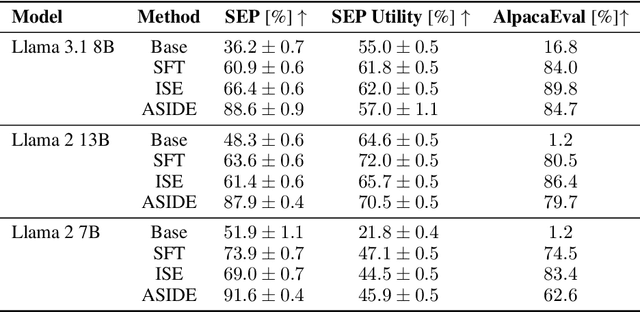
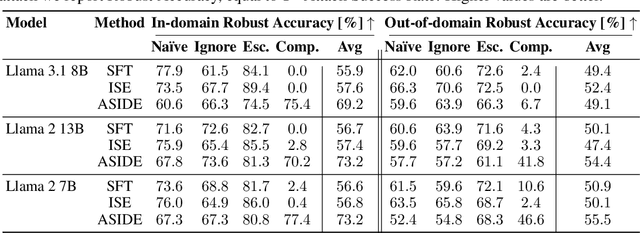
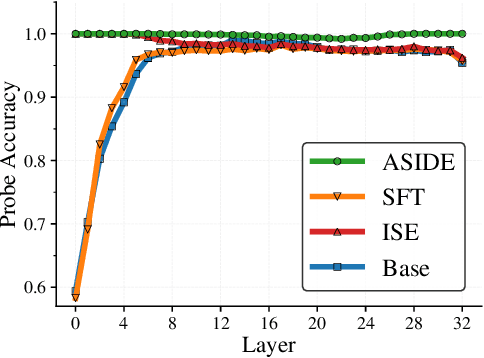
Despite their remarkable performance, large language models lack elementary safety features, and this makes them susceptible to numerous malicious attacks. In particular, previous work has identified the absence of an intrinsic separation between instructions and data as a root cause for the success of prompt injection attacks. In this work, we propose an architectural change, ASIDE, that allows the model to clearly separate between instructions and data by using separate embeddings for them. Instead of training the embeddings from scratch, we propose a method to convert an existing model to ASIDE form by using two copies of the original model's embeddings layer, and applying an orthogonal rotation to one of them. We demonstrate the effectiveness of our method by showing (1) highly increased instruction-data separation scores without a loss in model capabilities and (2) competitive results on prompt injection benchmarks, even without dedicated safety training. Additionally, we study the working mechanism behind our method through an analysis of model representations.
Post-Hoc Concept Disentanglement: From Correlated to Isolated Concept Representations
Mar 07, 2025Concept Activation Vectors (CAVs) are widely used to model human-understandable concepts as directions within the latent space of neural networks. They are trained by identifying directions from the activations of concept samples to those of non-concept samples. However, this method often produces similar, non-orthogonal directions for correlated concepts, such as "beard" and "necktie" within the CelebA dataset, which frequently co-occur in images of men. This entanglement complicates the interpretation of concepts in isolation and can lead to undesired effects in CAV applications, such as activation steering. To address this issue, we introduce a post-hoc concept disentanglement method that employs a non-orthogonality loss, facilitating the identification of orthogonal concept directions while preserving directional correctness. We evaluate our approach with real-world and controlled correlated concepts in CelebA and a synthetic FunnyBirds dataset with VGG16 and ResNet18 architectures. We further demonstrate the superiority of orthogonalized concept representations in activation steering tasks, allowing (1) the insertion of isolated concepts into input images through generative models and (2) the removal of concepts for effective shortcut suppression with reduced impact on correlated concepts in comparison to baseline CAVs.