 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Hoc Concept Disentanglement: From Correlated to Isolated Concept Representations
Mar 07, 2025



Concept Activation Vectors (CAVs) are widely used to model human-understandable concepts as directions within the latent space of neural networks. They are trained by identifying directions from the activations of concept samples to those of non-concept samples. However, this method often produces similar, non-orthogonal directions for correlated concepts, such as "beard" and "necktie" within the CelebA dataset, which frequently co-occur in images of men. This entanglement complicates the interpretation of concepts in isolation and can lead to undesired effects in CAV applications, such as activation steering. To address this issue, we introduce a post-hoc concept disentanglement method that employs a non-orthogonality loss, facilitating the identification of orthogonal concept directions while preserving directional correctness. We evaluate our approach with real-world and controlled correlated concepts in CelebA and a synthetic FunnyBirds dataset with VGG16 and ResNet18 architectures. We further demonstrate the superiority of orthogonalized concept representations in activation steering tasks, allowing (1) the insertion of isolated concepts into input images through generative models and (2) the removal of concepts for effective shortcut suppression with reduced impact on correlated concepts in comparison to baseline CAVs.
Ensuring Medical AI Safety: Explainable AI-Driven Detection and Mitigation of Spurious Model Behavior and Associated Data
Jan 23, 2025



Deep neural networks are increasingly employed in high-stakes medical applications, despite their tendency for shortcut learning in the presence of spurious correlations, which can have potentially fatal consequences in practice. Detecting and mitigating shortcut behavior is a challenging task that often requires significant labeling efforts from domain experts. To alleviate this problem, we introduce a semi-automated framework for the identification of spurious behavior from both data and model perspective by leveraging insights from eXplainable Artificial Intelligence (XAI). This allows the retrieval of spurious data points and the detection of model circuits that encode the associated prediction rules. Moreover, we demonstrate how these shortcut encodings can be used for XAI-based sample- and pixel-level data annotation, providing valuable information for bias mitigation methods to unlearn the undesired shortcut behavior. We show the applicability of our framework using four medical datasets across two modalities, featuring controlled and real-world spurious correlations caused by data artifacts. We successfully identify and mitigate these biases in VGG16, ResNet50, and contemporary Vision Transformer models, ultimately increasing their robustness and applicability for real-world medical tasks.
Synthetic Generation of Dermatoscopic Images with GAN and Closed-Form Factorization
Oct 07, 2024



In the realm of dermatological diagnoses, where the analysis of dermatoscopic and microscopic skin lesion images is pivotal for the accurate and early detection of various medical conditions, the costs associated with creating diverse and high-quality annotated datasets have hampered the accuracy and generalizability of machine learning models. We propose an innovative unsupervised augmentation solution that harnesses Generative Adversarial Network (GAN) based models and associated techniques over their latent space to generate controlled semiautomatically-discovered semantic variations in dermatoscopic images. We created synthetic images to incorporate the semantic variations and augmented the training data with these images. With this approach, we were able to increase the performance of machine learning models and set a new benchmark amongst non-ensemble based models in skin lesion classification on the HAM10000 dataset; and used the observed analytics and generated models for detailed studies on model explainability, affirming the effectiveness of our solution.
Explainable concept mappings of MRI: Revealing the mechanisms underlying deep learning-based brain disease classification
Apr 16, 2024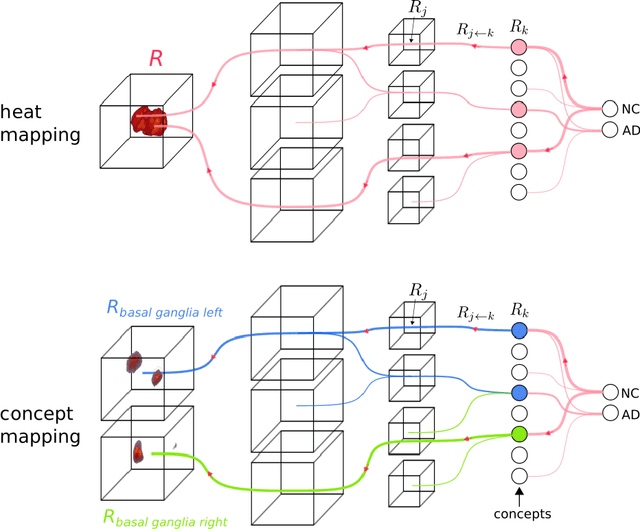
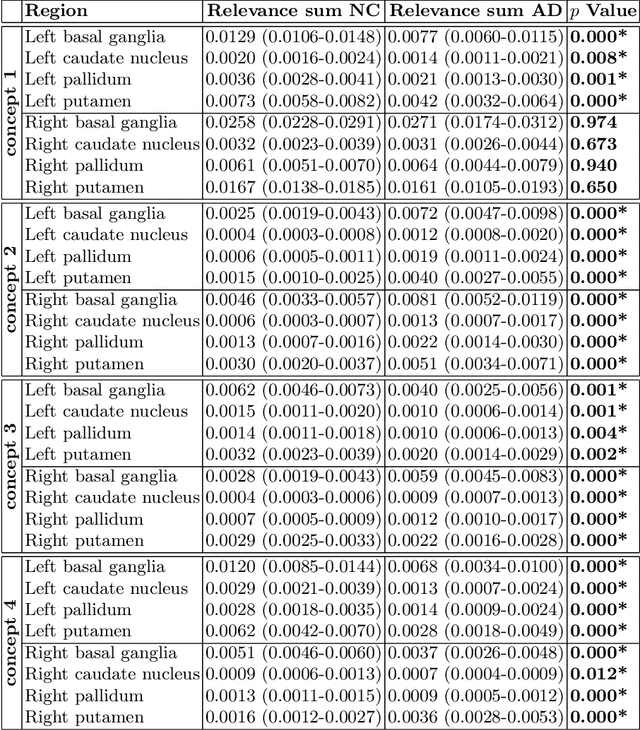
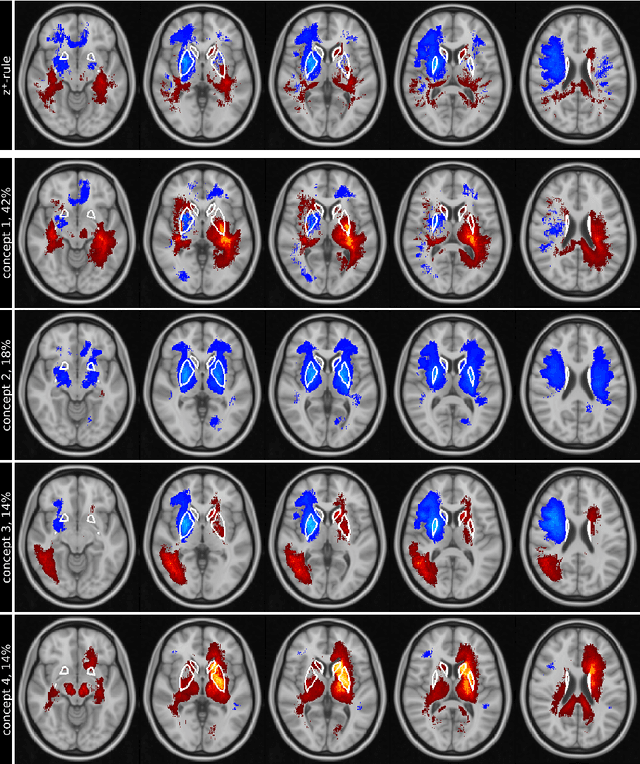
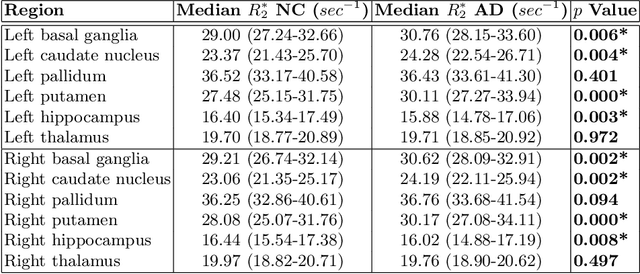
Motivation. While recent studies show high accuracy in the classification of Alzheimer's disease using deep neural networks, the underlying learned concepts have not been investigated. Goals. To systematically identify changes in brain regions through concepts learned by the deep neural network for model validation. Approach. Using quantitative R2* maps we separated Alzheimer's patients (n=117) from normal controls (n=219) by using a convolutional neural network and systematically investigated the learned concepts using Concept Relevance Propagation and compared these results to a conventional region of interest-based analysis. Results. In line with established histological findings and the region of interest-based analyses, highly relevant concepts were primarily found in and adjacent to the basal ganglia. Impact. The identification of concepts learned by deep neural networks for disease classification enables validation of the models and could potentially improve reliability.
Reactive Model Correction: Mitigating Harm to Task-Relevant Features via Conditional Bias Suppression
Apr 15, 2024



Deep Neural Networks are prone to learning and relying on spurious correlations in the training data, which, for high-risk applications, can have fatal consequences. Various approaches to suppress model reliance on harmful features have been proposed that can be applied post-hoc without additional training. Whereas those methods can be applied with efficiency, they also tend to harm model performance by globally shifting the distribution of latent features. To mitigate unintended overcorrection of model behavior, we propose a reactive approach conditioned on model-derived knowledge and eXplainable Artificial Intelligence (XAI) insights. While the reactive approach can be applied to many post-hoc methods, we demonstrate the incorporation of reactivity in particular for P-ClArC (Projective Class Artifact Compensation), introducing a new method called R-ClArC (Reactive Class Artifact Compensation). Through rigorous experiments in controlled settings (FunnyBirds) and with a real-world dataset (ISIC2019), we show that introducing reactivity can minimize the detrimental effect of the applied correction while simultaneously ensuring low reliance on spurious features.
From Hope to Safety: Unlearning Biases of Deep Models by Enforcing the Right Reasons in Latent Space
Aug 18, 2023Deep Neural Networks are prone to learning spurious correlations embedded in the training data, leading to potentially biased predictions. This poses risks when deploying these models for high-stake decision-making, such as in medical applications. Current methods for post-hoc model correction either require input-level annotations, which are only possible for spatially localized biases, or augment the latent feature space, thereby hoping to enforce the right reasons. We present a novel method ensuring the right reasons on the concept level by reducing the model's sensitivity towards biases through the gradient. When modeling biases via Concept Activation Vectors, we highlight the importance of choosing robust directions, as traditional regression-based approaches such as Support Vector Machines tend to result in diverging directions. We effectively mitigate biases in controlled and real-world settings on the ISIC, Bone Age, ImageNet and CelebA datasets using VGG, ResNet and EfficientNet architectures.
Reveal to Revise: An Explainable AI Life Cycle for Iterative Bias Correction of Deep Models
Mar 27, 2023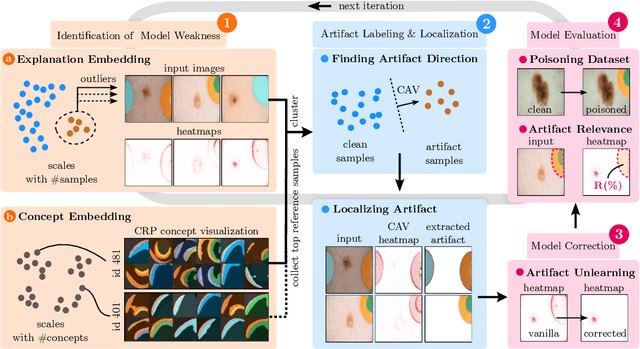
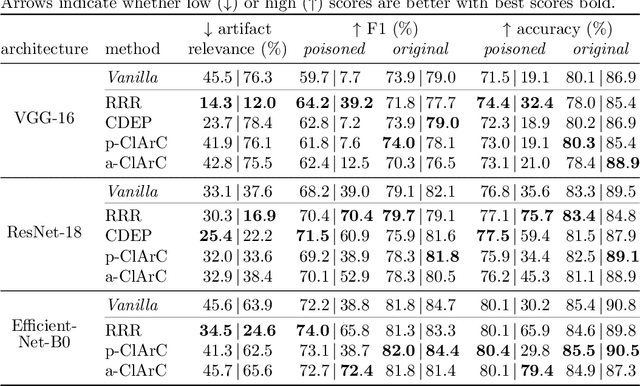
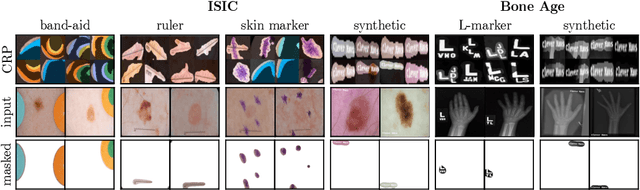
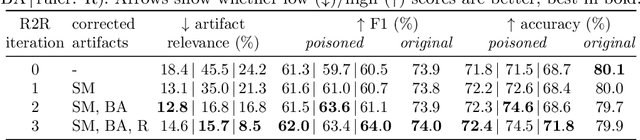
State-of-the-art machine learning models often learn spurious correlations embedded in the training data. This poses risks when deploying these models for high-stake decision-making, such as in medical applications like skin cancer detection. To tackle this problem, we propose Reveal to Revise (R2R), a framework entailing the entire eXplainable Artificial Intelligence (XAI) life cycle, enabling practitioners to iteratively identify, mitigate, and (re-)evaluate spurious model behavior with a minimal amount of human interaction. In the first step (1), R2R reveals model weaknesses by finding outliers in attributions or through inspection of latent concepts learned by the model. Secondly (2), the responsible artifacts are detected and spatially localized in the input data, which is then leveraged to (3) revise the model behavior. Concretely, we apply the methods of RRR, CDEP and ClArC for model correction, and (4) (re-)evaluate the model's performance and remaining sensitivity towards the artifact. Using two medical benchmark datasets for Melanoma detection and bone age estimation, we apply our R2R framework to VGG, ResNet and EfficientNet architectures and thereby reveal and correct real dataset-intrinsic artifacts, as well as synthetic variants in a controlled setting. Completing the XAI life cycle, we demonstrate multiple R2R iterations to mitigate different biases. Code is available on https://github.com/maxdreyer/Reveal2Revise.
Optimizing Explanations by Network Canonization and Hyperparameter Search
Nov 30, 2022Explainable AI (XAI) is slowly becoming a key component for many AI applications. Rule-based and modified backpropagation XAI approaches however often face challenges when being applied to modern model architectures including innovative layer building blocks, which is caused by two reasons. Firstly, the high flexibility of rule-based XAI methods leads to numerous potential parameterizations. Secondly, many XAI methods break the implementation-invariance axiom because they struggle with certain model components, e.g., BatchNorm layers. The latter can be addressed with model canonization, which is the process of re-structuring the model to disregard problematic components without changing the underlying function. While model canonization is straightforward for simple architectures (e.g., VGG, ResNet), it can be challenging for more complex and highly interconnected models (e.g., DenseNet). Moreover, there is only little quantifiable evidence that model canonization is beneficial for XAI. In this work, we propose canonizations for currently relevant model blocks applicable to popular deep neural network architectures,including VGG, ResNet, EfficientNet, DenseNets, as well as Relation Networks. We further suggest a XAI evaluation framework with which we quantify and compare the effect sof model canonization for various XAI methods in image classification tasks on the Pascal-VOC and ILSVRC2017 datasets, as well as for Visual Question Answering using CLEVR-XAI. Moreover, addressing the former issue outlined above, we demonstrate how our evaluation framework can be applied to perform hyperparameter search for XAI methods to optimize the quality of explanations.
PatClArC: Using Pattern Concept Activation Vectors for Noise-Robust Model Debugging
Feb 07, 2022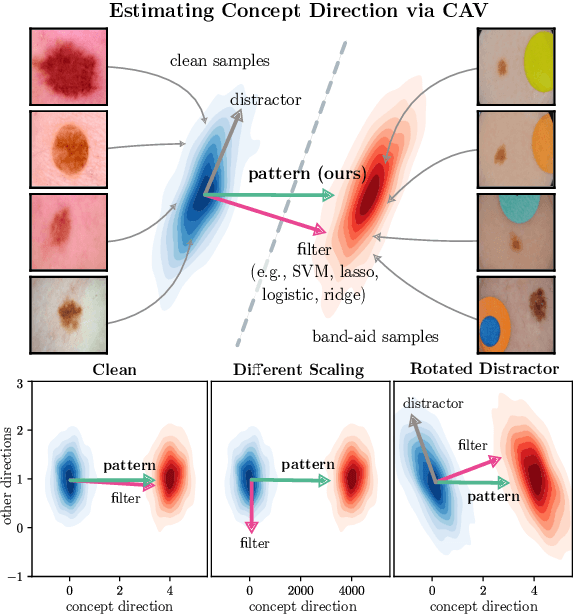
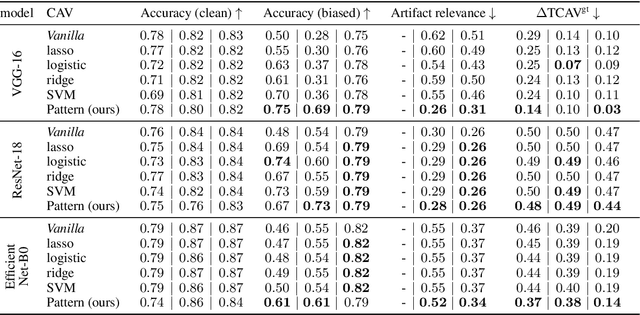
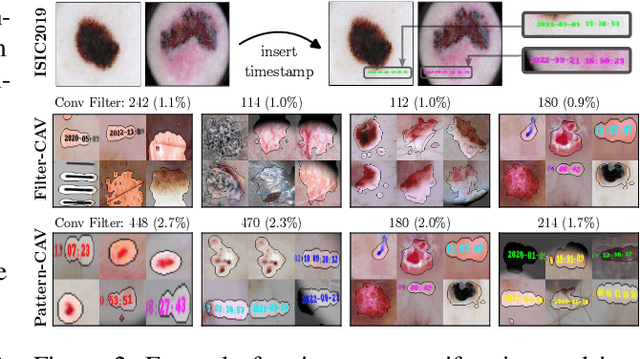

State-of-the-art machine learning models are commonly (pre-)trained on large benchmark datasets. These often contain biases, artifacts, or errors that have remained unnoticed in the data collection process and therefore fail in representing the real world truthfully. This can cause models trained on these datasets to learn undesired behavior based upon spurious correlations, e.g., the existence of a copyright tag in an image. Concept Activation Vectors (CAV) have been proposed as a tool to model known concepts in latent space and have been used for concept sensitivity testing and model correction. Specifically, class artifact compensation (ClArC) corrects models using CAVs to represent data artifacts in feature space linearly. Modeling CAVs with filters of linear models, however, causes a significant influence of the noise portion within the data, as recent work proposes the unsuitability of linear model filters to find the signal direction in the input, which can be avoided by instead using patterns. In this paper we propose Pattern Concept Activation Vectors (PCAV) for noise-robust concept representations in latent space. We demonstrate that pattern-based artifact modeling has beneficial effects on the application of CAVs as a means to remove influence of confounding features from models via the ClArC framework.
Multimodal Prototypical Networks for Few-shot Learning
Nov 17, 2020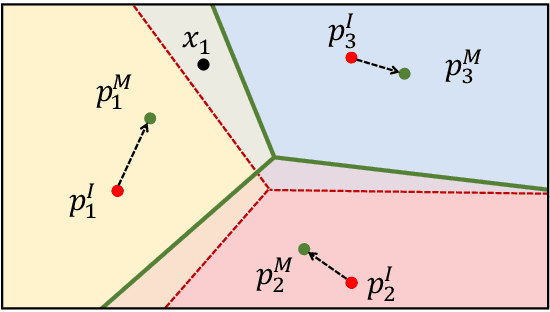
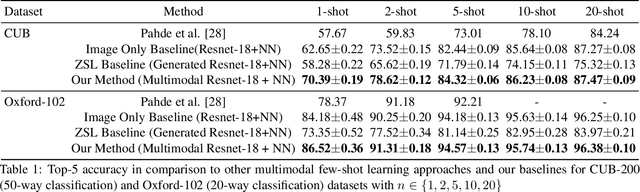
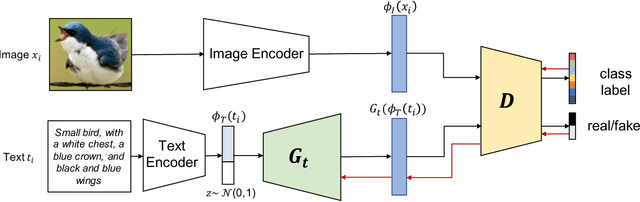
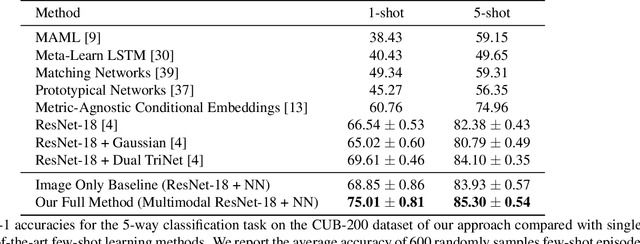
Although providing exceptional results for many computer vision tasks, state-of-the-art deep learning algorithms catastrophically struggle in low data scenarios. However, if data in additional modalities exist (e.g. text) this can compensate for the lack of data and improve the classification results. To overcome this data scarcity, we design a cross-modal feature generation framework capable of enriching the low populated embedding space in few-shot scenarios, leveraging data from the auxiliary modality. Specifically, we train a generative model that maps text data into the visual feature space to obtain more reliable prototypes. This allows to exploit data from additional modalities (e.g. text) during training while the ultimate task at test time remains classification with exclusively visual data. We show that in such cases nearest neighbor classification is a viable approach and outperform state-of-the-art single-modal and multimodal few-shot learning methods on the CUB-200 and Oxford-102 datasets.