 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabular Foundation Model for Generative Modelling
May 10, 2026Generative modelling is a demanding test of foundation models, because it requires robust, holistic representation learning for a given data modality, rather than optimisation for a supervised prediction target alone. While recent work on tabular foundation models has achieved remarkable progress in predictive modelling, generative tabular foundation models remain underexplored. Existing tabular foundation generators, in particular, have not yet consistently matched strong dataset-specific generators in synthetic data quality. A key reason is their misalignment with the distinctive causal structural prior of heterogeneous tabular data. In this paper, we address this gap by introducing a novel tabular foundation model, \textbf{TabFORGE}, built on pretrained \textbf{Tab}ular \textbf{FO}undational \textbf{R}epresentations for \textbf{GE}neration. TabFORGE is designed to utilise the implicitly learned causal information underlying diverse tabular datasets in a unified latent space induced by a pretrained causality-aware feature encoder. It further decouples latent modelling from decoding through a two-stage design: we first pretrain a score-based diffusion transformer, and then pretrain a denoising-aligned decoder using the denoised latent embeddings. This design elegantly mitigates the distribution shifts in latent embeddings that typically arise between training and inference. We evaluate TabFORGE comprehensively against 22 benchmark methods on 45 real-world datasets. Our results show that TabFORGE effectively learns and leverages generalisable tabular representations, enabling efficient generation of high-quality synthetic tabular data, particularly with strong structural fidelity.
The Headless Firm: How AI Reshapes Enterprise Boundaries
Feb 24, 2026The boundary of the firm is determined by coordination cost. We argue that agentic AI induces a structural change in how coordination costs scale: in prior modular systems, integration cost grew with interaction topology (O(n^2) in the number of components); in protocol-mediated agentic systems, integration cost collapses to O(n) while verification scales with task throughput rather than interaction count. This shift selects for a specific organizational equilibrium -- the Headless Firm -- structured as an hourglass: a personalized generative interface at the top, a standardized protocol waist in the middle, and a competitive market of micro-specialized execution agents at the bottom. We formalize this claim as a coordination cost model with two falsifiable empirical predictions: (1) the marginal cost of adding an execution provider should be approximately constant in a mature hourglass ecosystem; (2) the ratio of total coordination cost to task throughput should remain stable as ecosystem size grows. We derive conditions for hourglass stability versus re-centralization and analyze implications for firm size distributions, labor markets, and software economics. The analysis predicts a domain-conditional Great Unbundling: in high knowledge-velocity domains, firm size distributions shift mass from large integrated incumbents toward micro-specialized agents and thin protocol orchestrators.
SALT-KG: A Benchmark for Semantics-Aware Learning on Enterprise Tables
Jan 12, 2026Building upon the SALT benchmark for relational prediction (Klein et al., 2024), we introduce SALT-KG, a benchmark for semantics-aware learning on enterprise tables. SALT-KG extends SALT by linking its multi-table transactional data with a structured Operational Business Knowledge represented in a Metadata Knowledge Graph (OBKG) that captures field-level descriptions, relational dependencies, and business object types. This extension enables evaluation of models that jointly reason over tabular evidence and contextual semantics, an increasingly critical capability for foundation models on structured data. Empirical analysis reveals that while metadata-derived features yield modest improvements in classical prediction metrics, these metadata features consistently highlight gaps in the ability of models to leverage semantics in relational context. By reframing tabular prediction as semantics-conditioned reasoning, SALT-KG establishes a benchmark to advance tabular foundation models grounded in declarative knowledge, providing the first empirical step toward semantically linked tables in structured data at enterprise scale.
Foundation Models for Tabular Data within Systemic Contexts Need Grounding
May 26, 2025Current research on tabular foundation models often overlooks the complexities of large-scale, real-world data by treating tables as isolated entities and assuming information completeness, thereby neglecting the vital operational context. To address this, we introduce the concept of Semantically Linked Tables (SLT), recognizing that tables are inherently connected to both declarative and procedural operational knowledge. We propose Foundation Models for Semantically Linked Tables (FMSLT), which integrate these components to ground tabular data within its true operational context. This comprehensive representation unlocks the full potential of machine learning for complex, interconnected tabular data across diverse domains. Realizing FMSLTs requires access to operational knowledge that is often unavailable in public datasets, highlighting the need for close collaboration between domain experts and researchers. Our work exposes the limitations of current tabular foundation models and proposes a new direction centered on FMSLTs, aiming to advance robust, context-aware models for structured data.
SALT: Sales Autocompletion Linked Business Tables Dataset
Jan 06, 2025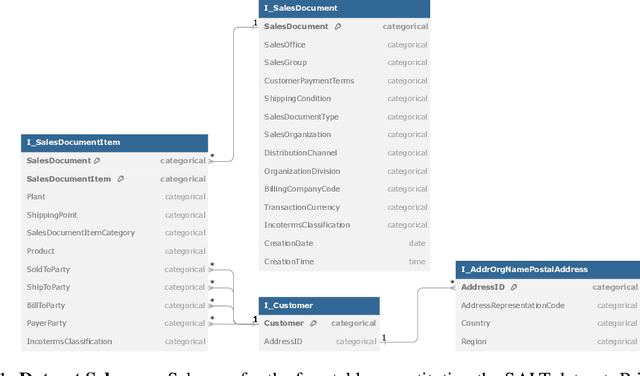

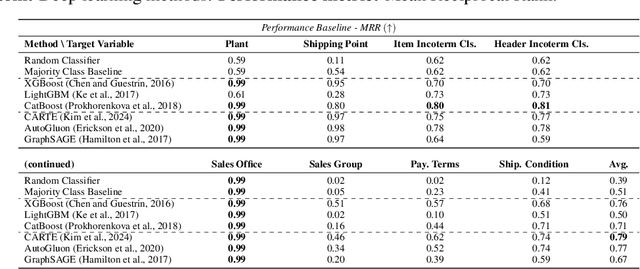
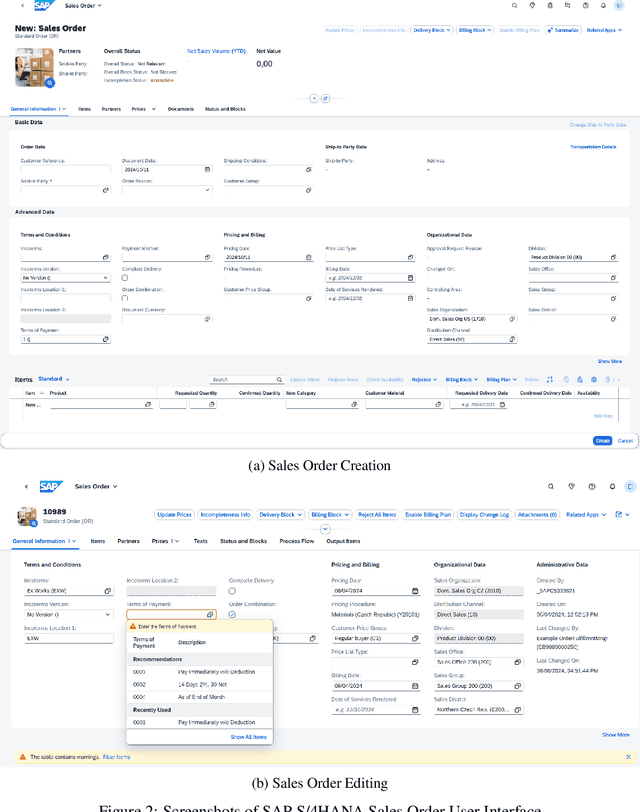
Foundation models, particularly those that incorporate Transformer architectures, have demonstrated exceptional performance in domains such as natural language processing and image processing. Adapting these models to structured data, like tables, however, introduces significant challenges. These difficulties are even more pronounced when addressing multi-table data linked via foreign key, which is prevalent in the enterprise realm and crucial for empowering business use cases. Despite its substantial impact, research focusing on such linked business tables within enterprise settings remains a significantly important yet underexplored domain. To address this, we introduce a curated dataset sourced from an Enterprise Resource Planning (ERP) system, featuring extensive linked tables. This dataset is specifically designed to support research endeavors in table representation learning. By providing access to authentic enterprise data, our goal is to potentially enhance the effectiveness and applicability of models for real-world business contexts.
PORTAL: Scalable Tabular Foundation Models via Content-Specific Tokenization
Oct 17, 2024



Self-supervised learning on tabular data seeks to apply advances from natural language and image domains to the diverse domain of tables. However, current techniques often struggle with integrating multi-domain data and require data cleaning or specific structural requirements, limiting the scalability of pre-training datasets. We introduce PORTAL (Pretraining One-Row-at-a-Time for All tabLes), a framework that handles various data modalities without the need for cleaning or preprocessing. This simple yet powerful approach can be effectively pre-trained on online-collected datasets and fine-tuned to match state-of-the-art methods on complex classification and regression tasks. This work offers a practical advancement in self-supervised learning for large-scale tabular data.
Contrastive Perplexity for Controlled Generation: An Application in Detoxifying Large Language Models
Jan 24, 2024
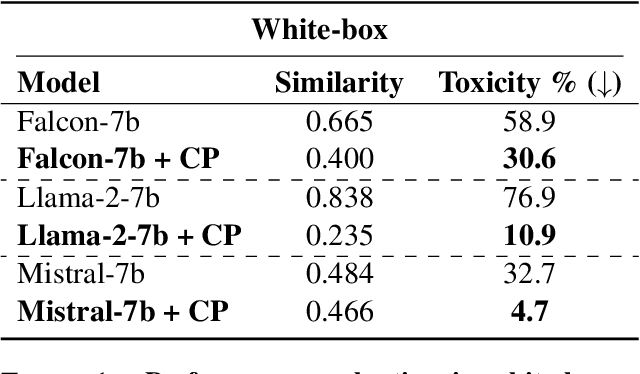


The generation of undesirable and factually incorrect content of large language models poses a significant challenge and remains largely an unsolved issue. This paper studies the integration of a contrastive learning objective for fine-tuning LLMs for implicit knowledge editing and controlled text generation. Optimizing the training objective entails aligning text perplexities in a contrastive fashion. To facilitate training the model in a self-supervised fashion, we leverage an off-the-shelf LLM for training data generation. We showcase applicability in the domain of detoxification. Herein, the proposed approach leads to a significant decrease in the generation of toxic content while preserving general utility for downstream tasks such as commonsense reasoning and reading comprehension. The proposed approach is conceptually simple but empirically powerful.
miCSE: Mutual Information Contrastive Learning for Low-shot Sentence Embeddings
Nov 09, 2022This paper presents miCSE, a mutual information-based Contrastive learning framework that significantly advances the state-of-the-art in few-shot sentence embedding. The proposed approach imposes alignment between the attention pattern of different views during contrastive learning. Learning sentence embeddings with miCSE entails enforcing the syntactic consistency across augmented views for every single sentence, making contrastive self-supervised learning more sample efficient. As a result, the proposed approach shows strong performance in the few-shot learning domain. While it achieves superior results compared to state-of-the-art methods on multiple benchmarks in few-shot learning, it is comparable in the full-shot scenario. The proposed approach is conceptually simple, easy to implement and optimize, yet empirically powerful. This study opens up avenues for efficient self-supervised learning methods that are more robust than current contrastive methods for sentence embedding.
Mixture-of-experts VAEs can disregard variation in surjective multimodal data
Apr 11, 2022
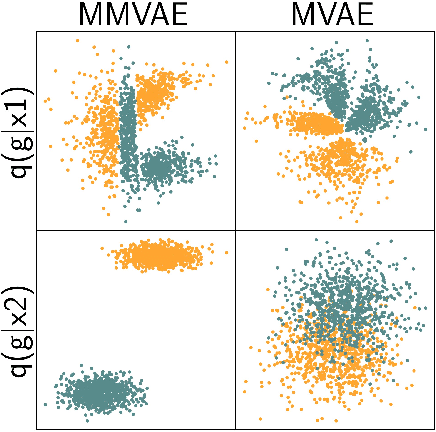
Machine learning systems are often deployed in domains that entail data from multiple modalities, for example, phenotypic and genotypic characteristics describe patients in healthcare. Previous works have developed multimodal variational autoencoders (VAEs) that generate several modalities. We consider subjective data, where single datapoints from one modality (such as class labels) describe multiple datapoints from another modality (such as images). We theoretically and empirically demonstrate that multimodal VAEs with a mixture of experts posterior can struggle to capture variability in such surjective data.
SCD: Self-Contrastive Decorrelation for Sentence Embeddings
Mar 15, 2022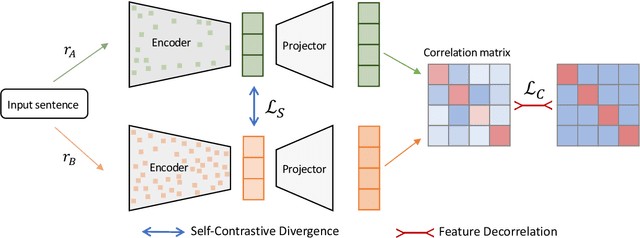
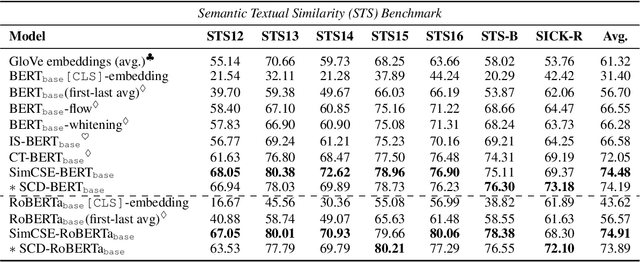
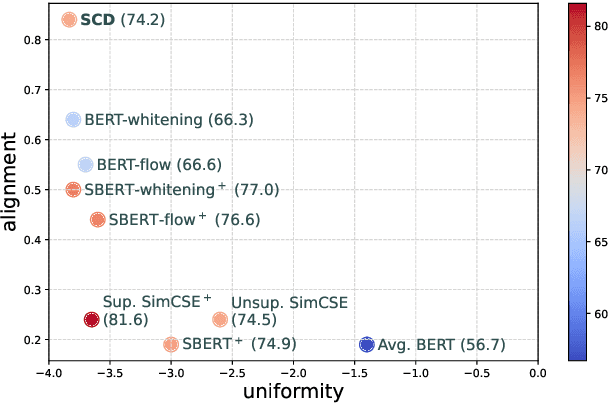
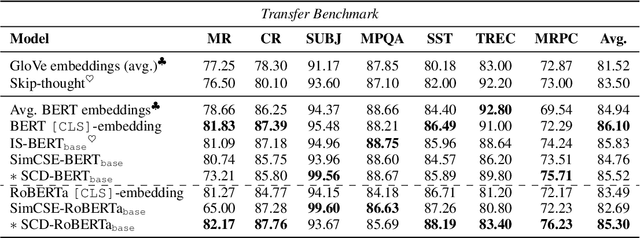
In this paper, we propose Self-Contrastive Decorrelation (SCD), a self-supervised approach. Given an input sentence, it optimizes a joint self-contrastive and decorrelation objective. Learning a representation is facilitated by leveraging the contrast arising from the instantiation of standard dropout at different rates. The proposed method is conceptually simple yet empirically powerful. It achieves comparable results with state-of-the-art methods on multiple benchmarks without using contrastive pairs. This study opens up avenues for efficient self-supervised learning methods that are more robust than current contrastive methods.