 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-experts VAEs can disregard variation in surjective multimodal data
Apr 11, 2022
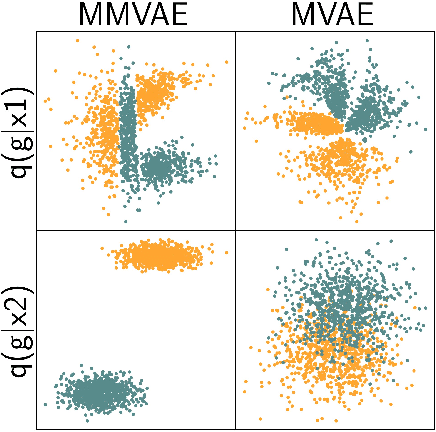
Machine learning systems are often deployed in domains that entail data from multiple modalities, for example, phenotypic and genotypic characteristics describe patients in healthcare. Previous works have developed multimodal variational autoencoders (VAEs) that generate several modalities. We consider subjective data, where single datapoints from one modality (such as class labels) describe multiple datapoints from another modality (such as images). We theoretically and empirically demonstrate that multimodal VAEs with a mixture of experts posterior can struggle to capture variability in such surjective data.
Learning Graph-Based Priors for Generalized Zero-Shot Learning
Oct 22, 2020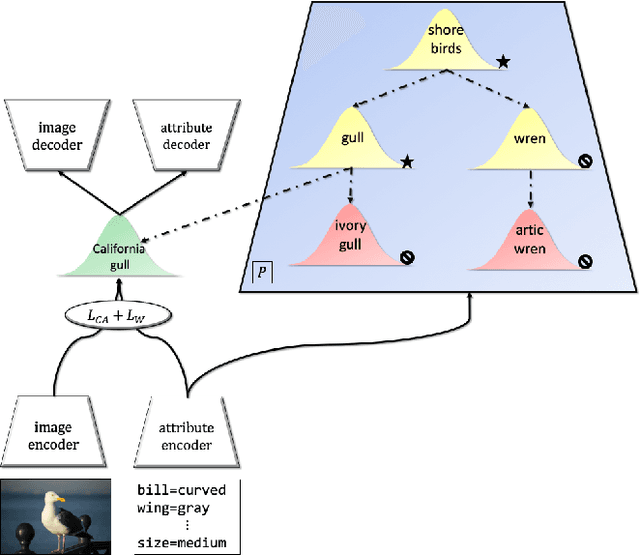

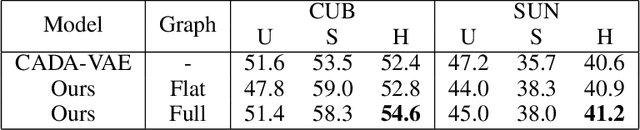
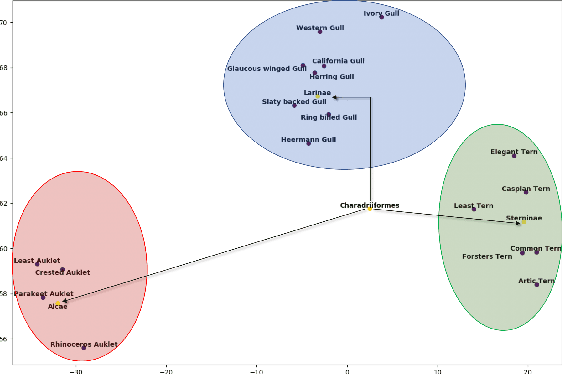
The task of zero-shot learning (ZSL) requires correctly predicting the label of samples from classes which were unseen at training time. This is achieved by leveraging side information about class labels, such as label attributes or word embeddings. Recently, attention has shifted to the more realistic task of generalized ZSL (GZSL) where test sets consist of seen and unseen samples. Recent approaches to GZSL have shown the value of generative models, which are used to generate samples from unseen classes. In this work, we incorporate an additional source of side information in the form of a relation graph over labels. We leverage this graph in order to learn a set of prior distributions, which encourage an aligned variational autoencoder (VAE) model to learn embeddings which respect the graph structure. Using this approach we are able to achieve improved performance on the CUB and SUN benchmarks over a strong baseline.
Low-Shot Learning from Imaginary 3D Model
Jan 04, 2019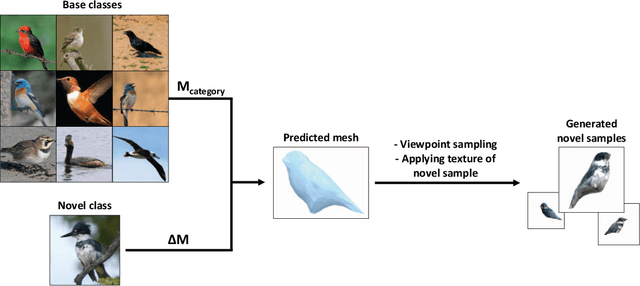
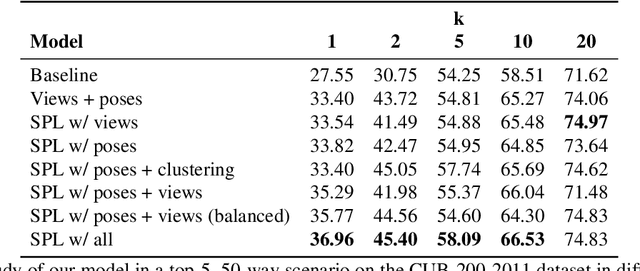
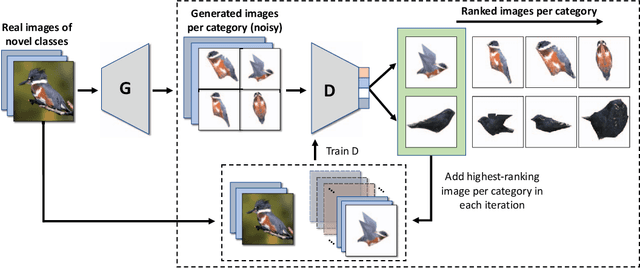

Since the advent of deep learning, neural networks have demonstrated remarkable results in many visual recognition tasks, constantly pushing the limits. However, the state-of-the-art approaches are largely unsuitable in scarce data regimes. To address this shortcoming, this paper proposes employing a 3D model, which is derived from training images. Such a model can then be used to hallucinate novel viewpoints and poses for the scarce samples of the few-shot learning scenario. A self-paced learning approach allows for the selection of a diverse set of high-quality images, which facilitates the training of a classifier. The performance of the proposed approach is showcased on the fine-grained CUB-200-2011 dataset in a few-shot setting and significantly improves our baseline accuracy.