 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Bayesian Low-Rank Adaptation of Large Language Models via Stochastic Variational Subspace Inference
Jun 26, 2025Despite their widespread use, large language models (LLMs) are known to hallucinate incorrect information and be poorly calibrated. This makes the uncertainty quantification of these models of critical importance, especially in high-stakes domains, such as autonomy and healthcare. Prior work has made Bayesian deep learning-based approaches to this problem more tractable by performing inference over the low-rank adaptation (LoRA) parameters of a fine-tuned model. While effective, these approaches struggle to scale to larger LLMs due to requiring further additional parameters compared to LoRA. In this work we present $\textbf{Scala}$ble $\textbf{B}$ayesian $\textbf{L}$ow-Rank Adaptation via Stochastic Variational Subspace Inference (ScalaBL). We perform Bayesian inference in an $r$-dimensional subspace, for LoRA rank $r$. By repurposing the LoRA parameters as projection matrices, we are able to map samples from this subspace into the full weight space of the LLM. This allows us to learn all the parameters of our approach using stochastic variational inference. Despite the low dimensionality of our subspace, we are able to achieve competitive performance with state-of-the-art approaches while only requiring ${\sim}1000$ additional parameters. Furthermore, it allows us to scale up to the largest Bayesian LLM to date, with four times as a many base parameters as prior work.
Calibrating Uncertainty Quantification of Multi-Modal LLMs using Grounding
Apr 30, 2025We introduce a novel approach for calibrating uncertainty quantification (UQ) tailored for multi-modal large language models (LLMs). Existing state-of-the-art UQ methods rely on consistency among multiple responses generated by the LLM on an input query under diverse settings. However, these approaches often report higher confidence in scenarios where the LLM is consistently incorrect. This leads to a poorly calibrated confidence with respect to accuracy. To address this, we leverage cross-modal consistency in addition to self-consistency to improve the calibration of the multi-modal models. Specifically, we ground the textual responses to the visual inputs. The confidence from the grounding model is used to calibrate the overall confidence. Given that using a grounding model adds its own uncertainty in the pipeline, we apply temperature scaling - a widely accepted parametric calibration technique - to calibrate the grounding model's confidence in the accuracy of generated responses. We evaluate the proposed approach across multiple multi-modal tasks, such as medical question answering (Slake) and visual question answering (VQAv2), considering multi-modal models such as LLaVA-Med and LLaVA. The experiments demonstrate that the proposed framework achieves significantly improved calibration on both tasks.
AGENT: An Aerial Vehicle Generation and Design Tool Using Large Language Models
Apr 11, 2025Computer-aided design (CAD) is a promising application area for emerging artificial intelligence methods. Traditional workflows for cyberphysical systems create detailed digital models which can be evaluated by physics simulators in order to narrow the search space before creating physical prototypes. A major bottleneck of this approach is that the simulators are often computationally expensive and slow. Recent advancements in AI methods offer the possibility to accelerate these pipelines. We use the recently released AircraftVerse dataset, which is especially suited for developing and evaluating large language models for designs. AircraftVerse contains a diverse set of UAV designs represented via textual design trees together with detailed physics simulation results. Following the recent success of large language models (LLMs), we propose AGENT (Aircraft GENeraTor). AGENT is a comprehensive design tool built on the CodeT5+ LLM which learns powerful representations of aircraft textual designs directly from JSON files. We develop a curriculum of training tasks which imbues a single model with a suite of useful features. AGENT is able to generate designs conditioned on properties of flight dynamics (hover time, maximum speed, etc.). Additionally, AGENT can issue evaluations of designs allowing it to act as a surrogate model of the physics simulation that underlies the AircraftVerse dataset. We present a series of experiments which demonstrate our system's abilities. We are able to achieve strong performance using the smallest member of the CodeT5+ family (220M parameters). This allows for a flexible and powerful system which can be executed on a single GPU enabling a clear path toward future deployment.
Addressing Uncertainty in LLMs to Enhance Reliability in Generative AI
Nov 04, 2024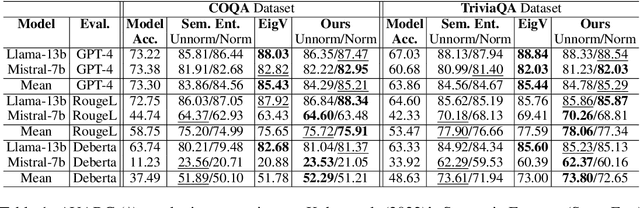
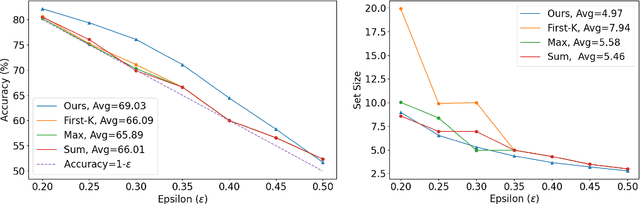
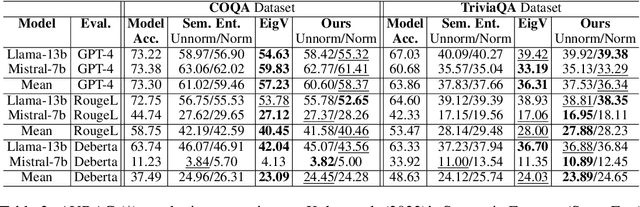
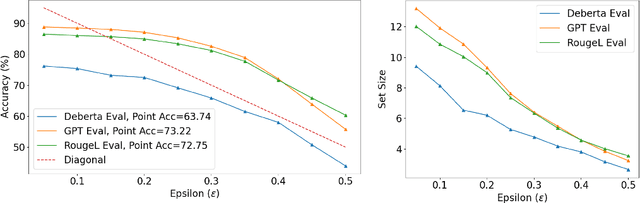
In this paper, we present a dynamic semantic clustering approach inspired by the Chinese Restaurant Process, aimed at addressing uncertainty in the inference of Large Language Models (LLMs). We quantify uncertainty of an LLM on a given query by calculating entropy of the generated semantic clusters. Further, we propose leveraging the (negative) likelihood of these clusters as the (non)conformity score within Conformal Prediction framework, allowing the model to predict a set of responses instead of a single output, thereby accounting for uncertainty in its predictions. We demonstrate the effectiveness of our uncertainty quantification (UQ) technique on two well known question answering benchmarks, COQA and TriviaQA, utilizing two LLMs, Llama2 and Mistral. Our approach achieves SOTA performance in UQ, as assessed by metrics such as AUROC, AUARC, and AURAC. The proposed conformal predictor is also shown to produce smaller prediction sets while maintaining the same probabilistic guarantee of including the correct response, in comparison to existing SOTA conformal prediction baseline.
Temporally Multi-Scale Sparse Self-Attention for Physical Activity Data Imputation
Jun 27, 2024Wearable sensors enable health researchers to continuously collect data pertaining to the physiological state of individuals in real-world settings. However, such data can be subject to extensive missingness due to a complex combination of factors. In this work, we study the problem of imputation of missing step count data, one of the most ubiquitous forms of wearable sensor data. We construct a novel and large scale data set consisting of a training set with over 3 million hourly step count observations and a test set with over 2.5 million hourly step count observations. We propose a domain knowledge-informed sparse self-attention model for this task that captures the temporal multi-scale nature of step-count data. We assess the performance of the model relative to baselines and conduct ablation studies to verify our specific model designs.
FlexLoc: Conditional Neural Networks for Zero-Shot Sensor Perspective Invariance in Object Localization with Distributed Multimodal Sensors
Jun 10, 2024



Localization is a critical technology for various applications ranging from navigation and surveillance to assisted living. Localization systems typically fuse information from sensors viewing the scene from different perspectives to estimate the target location while also employing multiple modalities for enhanced robustness and accuracy. Recently, such systems have employed end-to-end deep neural models trained on large datasets due to their superior performance and ability to handle data from diverse sensor modalities. However, such neural models are often trained on data collected from a particular set of sensor poses (i.e., locations and orientations). During real-world deployments, slight deviations from these sensor poses can result in extreme inaccuracies. To address this challenge, we introduce FlexLoc, which employs conditional neural networks to inject node perspective information to adapt the localization pipeline. Specifically, a small subset of model weights are derived from node poses at run time, enabling accurate generalization to unseen perspectives with minimal additional overhead. Our evaluations on a multimodal, multiview indoor tracking dataset showcase that FlexLoc improves the localization accuracy by almost 50% in the zero-shot case (no calibration data available) compared to the baselines. The source code of FlexLoc is available at https://github.com/nesl/FlexLoc.
GDTM: An Indoor Geospatial Tracking Dataset with Distributed Multimodal Sensors
Feb 21, 2024



Constantly locating moving objects, i.e., geospatial tracking, is essential for autonomous building infrastructure. Accurate and robust geospatial tracking often leverages multimodal sensor fusion algorithms, which require large datasets with time-aligned, synchronized data from various sensor types. However, such datasets are not readily available. Hence, we propose GDTM, a nine-hour dataset for multimodal object tracking with distributed multimodal sensors and reconfigurable sensor node placements. Our dataset enables the exploration of several research problems, such as optimizing architectures for processing multimodal data, and investigating models' robustness to adverse sensing conditions and sensor placement variances. A GitHub repository containing the code, sample data, and checkpoints of this work is available at https://github.com/nesl/GDTM.
Heteroskedastic Geospatial Tracking with Distributed Camera Networks
Jun 04, 2023Visual object tracking has seen significant progress in recent years. However, the vast majority of this work focuses on tracking objects within the image plane of a single camera and ignores the uncertainty associated with predicted object locations. In this work, we focus on the geospatial object tracking problem using data from a distributed camera network. The goal is to predict an object's track in geospatial coordinates along with uncertainty over the object's location while respecting communication constraints that prohibit centralizing raw image data. We present a novel single-object geospatial tracking data set that includes high-accuracy ground truth object locations and video data from a network of four cameras. We present a modeling framework for addressing this task including a novel backbone model and explore how uncertainty calibration and fine-tuning through a differentiable tracker affect performance.
Learning Graph-Based Priors for Generalized Zero-Shot Learning
Oct 22, 2020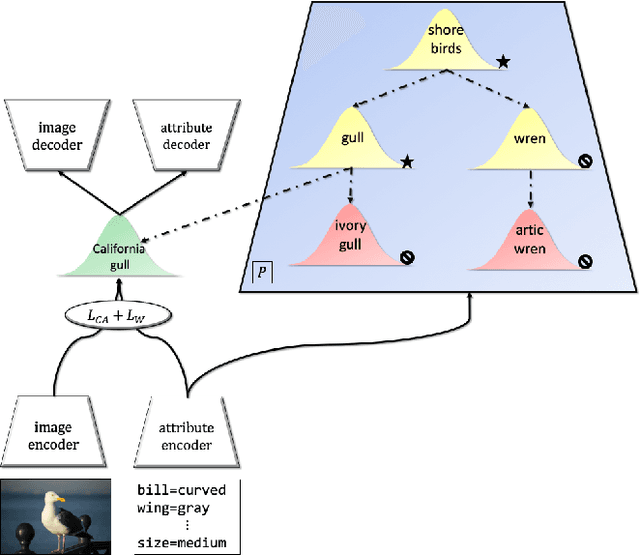

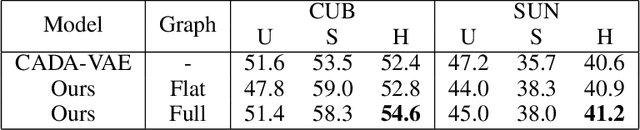
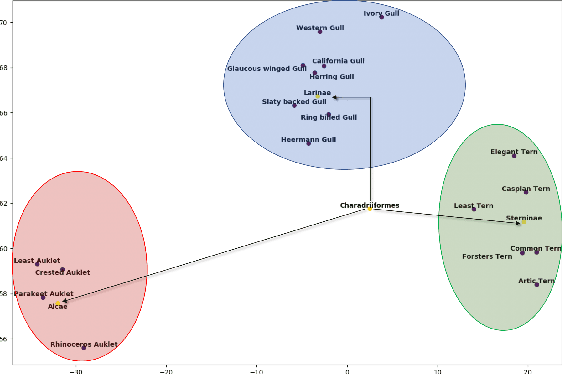
The task of zero-shot learning (ZSL) requires correctly predicting the label of samples from classes which were unseen at training time. This is achieved by leveraging side information about class labels, such as label attributes or word embeddings. Recently, attention has shifted to the more realistic task of generalized ZSL (GZSL) where test sets consist of seen and unseen samples. Recent approaches to GZSL have shown the value of generative models, which are used to generate samples from unseen classes. In this work, we incorporate an additional source of side information in the form of a relation graph over labels. We leverage this graph in order to learn a set of prior distributions, which encourage an aligned variational autoencoder (VAE) model to learn embeddings which respect the graph structure. Using this approach we are able to achieve improved performance on the CUB and SUN benchmarks over a strong baseline.
Integrating Propositional and Relational Label Side Information for Hierarchical Zero-Shot Image Classification
Feb 14, 2019
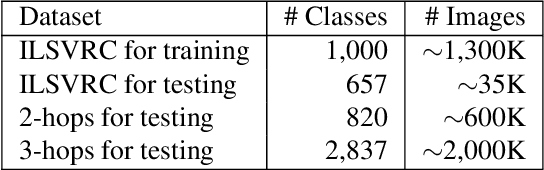


Zero-shot learning (ZSL) is one of the most extreme forms of learning from scarce labeled data. It enables predicting that images belong to classes for which no labeled training instances are available. In this paper, we present a new ZSL framework that leverages both label attribute side information and a semantic label hierarchy. We present two methods, lifted zero-shot prediction and a custom conditional random field (CRF) model, that integrate both forms of side information. We propose benchmark tasks for this framework that focus on making predictions across a range of semantic levels. We show that lifted zero-shot prediction can dramatically outperform baseline methods when making predictions within specified semantic levels, and that the probability distribution provided by the CRF model can be leveraged to yield further performance improvements when making unconstrained predictions over the hierarchy.