 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Foundation Models for IoT: Taxonomy and Criteria-Based Analysis
Jun 13, 2025

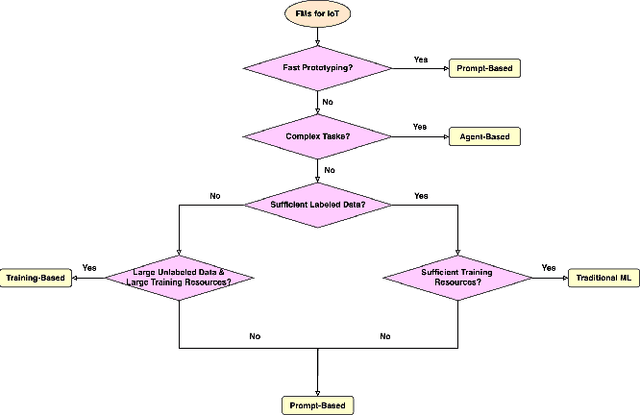
Foundation models have gained growing interest in the IoT domain due to their reduced reliance on labeled data and strong generalizability across tasks, which address key limitations of traditional machine learning approaches. However, most existing foundation model based methods are developed for specific IoT tasks, making it difficult to compare approaches across IoT domains and limiting guidance for applying them to new tasks. This survey aims to bridge this gap by providing a comprehensive overview of current methodologies and organizing them around four shared performance objectives by different domains: efficiency, context-awareness, safety, and security & privacy. For each objective, we review representative works, summarize commonly-used techniques and evaluation metrics. This objective-centric organization enables meaningful cross-domain comparisons and offers practical insights for selecting and designing foundation model based solutions for new IoT tasks. We conclude with key directions for future research to guide both practitioners and researchers in advancing the use of foundation models in IoT applications.
GDTM: An Indoor Geospatial Tracking Dataset with Distributed Multimodal Sensors
Feb 21, 2024



Constantly locating moving objects, i.e., geospatial tracking, is essential for autonomous building infrastructure. Accurate and robust geospatial tracking often leverages multimodal sensor fusion algorithms, which require large datasets with time-aligned, synchronized data from various sensor types. However, such datasets are not readily available. Hence, we propose GDTM, a nine-hour dataset for multimodal object tracking with distributed multimodal sensors and reconfigurable sensor node placements. Our dataset enables the exploration of several research problems, such as optimizing architectures for processing multimodal data, and investigating models' robustness to adverse sensing conditions and sensor placement variances. A GitHub repository containing the code, sample data, and checkpoints of this work is available at https://github.com/nesl/GDTM.
Efficient IoT Inference via Context-Awareness
Oct 29, 2023While existing strategies for optimizing deep learning-based classification models on low-power platforms assume the models are trained on all classes of interest, this paper posits that adopting context-awareness i.e. focusing solely on the likely classes in the current context, can substantially enhance performance in resource-constrained environments. We propose a new paradigm, CACTUS, for scalable and efficient context-aware classification where a micro-classifier recognizes a small set of classes relevant to the current context and, when context change happens, rapidly switches to another suitable micro-classifier. CACTUS has several innovations including optimizing the training cost of context-aware classifiers, enabling on-the-fly context-aware switching between classifiers, and selecting the best context-aware classifiers given limited resources. We show that CACTUS achieves significant benefits in accuracy, latency, and compute budget across a range of datasets and IoT platforms.
Heteroskedastic Geospatial Tracking with Distributed Camera Networks
Jun 04, 2023Visual object tracking has seen significant progress in recent years. However, the vast majority of this work focuses on tracking objects within the image plane of a single camera and ignores the uncertainty associated with predicted object locations. In this work, we focus on the geospatial object tracking problem using data from a distributed camera network. The goal is to predict an object's track in geospatial coordinates along with uncertainty over the object's location while respecting communication constraints that prohibit centralizing raw image data. We present a novel single-object geospatial tracking data set that includes high-accuracy ground truth object locations and video data from a network of four cameras. We present a modeling framework for addressing this task including a novel backbone model and explore how uncertainty calibration and fine-tuning through a differentiable tracker affect performance.
CarFi: Rider Localization Using Wi-Fi CSI
Dec 21, 2022With the rise of hailing services, people are increasingly relying on shared mobility (e.g., Uber, Lyft) drivers to pick up for transportation. However, such drivers and riders have difficulties finding each other in urban areas as GPS signals get blocked by skyscrapers, in crowded environments (e.g., in stadiums, airports, and bars), at night, and in bad weather. It wastes their time, creates a bad user experience, and causes more CO2 emissions due to idle driving. In this work, we explore the potential of Wi-Fi to help drivers to determine the street side of the riders. Our proposed system is called CarFi that uses Wi-Fi CSI from two antennas placed inside a moving vehicle and a data-driven technique to determine the street side of the rider. By collecting real-world data in realistic and challenging settings by blocking the signal with other people and other parked cars, we see that CarFi is 95.44% accurate in rider-side determination in both line of sight (LoS) and non-line of sight (nLoS) conditions, and can be run on an embedded GPU in real-time.