 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemmAnomaly: Leveraging Visual Context for Robust Anomaly Detection in the Non-Visual World with mmWave Radar
Apr 01, 2026mmWave radar enables human sensing in non-visual scenarios-e.g., through clothing or certain types of walls-where traditional cameras fail due to occlusion or privacy limitations. However, robust anomaly detection with mmWave remains challenging, as signal reflections are influenced by material properties, clutter, and multipath interference, producing complex, non-Gaussian distortions. Existing methods lack contextual awareness and misclassify benign signal variations as anomalies. We present mmAnomaly, a multi-modal anomaly detection framework that combines mmWave radar with RGBD input to incorporate visual context. Our system extracts semantic cues-such as scene geometry and material properties-using a fast ResNet-based classifier, and uses a conditional latent diffusion model to synthesize the expected mmWave spectrum for the given visual context. A dual-input comparison module then identifies spatial deviations between real and generated spectra to localize anomalies. We evaluate mmAnomaly on two multi-modal datasets across three applications: concealed weapon localization, through-wall intruder localization, and through-wall fall localization. The system achieves up to 94% F1 score and sub-meter localization error, demonstrating robust generalization across clothing, occlusions, and cluttered environments. These results establish mmAnomaly as an accurate and interpretable framework for context-aware anomaly detection in mmWave sensing.
mmCounter: Static People Counting in Dense Indoor Scenarios Using mmWave Radar
Dec 11, 2025mmWave radars struggle to detect or count individuals in dense, static (non-moving) groups due to limitations in spatial resolution and reliance on movement for detection. We present mmCounter, which accurately counts static people in dense indoor spaces (up to three people per square meter). mmCounter achieves this by extracting ultra-low frequency (< 1 Hz) signals, primarily from breathing and micro-scale body movements such as slight torso shifts, and applying novel signal processing techniques to differentiate these subtle signals from background noise and nearby static objects. Our problem differs significantly from existing studies on breathing rate estimation, which assume the number of people is known a priori. In contrast, mmCounter utilizes a novel multi-stage signal processing pipeline to extract relevant low-frequency sources along with their spatial information and map these sources to individual people, enabling accurate counting. Extensive evaluations in various environments demonstrate that mmCounter delivers an 87% average F1 score and 0.6 mean absolute error in familiar environments, and a 60% average F1 score and 1.1 mean absolute error in previously untested environments. It can count up to seven individuals in a three square meter space, such that there is no side-by-side spacing and only a one-meter front-to-back distance.
mmWEAVER: Environment-Specific mmWave Signal Synthesis from a Photo and Activity Description
Dec 10, 2025Realistic signal generation and dataset augmentation are essential for advancing mmWave radar applications such as activity recognition and pose estimation, which rely heavily on diverse, and environment-specific signal datasets. However, mmWave signals are inherently complex, sparse, and high-dimensional, making physical simulation computationally expensive. This paper presents mmWeaver, a novel framework that synthesizes realistic, environment-specific complex mmWave signals by modeling them as continuous functions using Implicit Neural Representations (INRs), achieving up to 49-fold compression. mmWeaver incorporates hypernetworks that dynamically generate INR parameters based on environmental context (extracted from RGB-D images) and human motion features (derived from text-to-pose generation via MotionGPT), enabling efficient and adaptive signal synthesis. By conditioning on these semantic and geometric priors, mmWeaver generates diverse I/Q signals at multiple resolutions, preserving phase information critical for downstream tasks such as point cloud estimation and activity classification. Extensive experiments show that mmWeaver achieves a complex SSIM of 0.88 and a PSNR of 35 dB, outperforming existing methods in signal realism while improving activity recognition accuracy by up to 7% and reducing human pose estimation error by up to 15%, all while operating 6-35 times faster than simulation-based approaches.
SpeechQualityLLM: LLM-Based Multimodal Assessment of Speech Quality
Dec 09, 2025Objective speech quality assessment is central to telephony, VoIP, and streaming systems, where large volumes of degraded audio must be monitored and optimized at scale. Classical metrics such as PESQ and POLQA approximate human mean opinion scores (MOS) but require carefully controlled conditions and expensive listening tests, while learning-based models such as NISQA regress MOS and multiple perceptual dimensions from waveforms or spectrograms, achieving high correlation with subjective ratings yet remaining rigid: they do not support interactive, natural-language queries and do not natively provide textual rationales. In this work, we introduce SpeechQualityLLM, a multimodal speech quality question-answering (QA) system that couples an audio encoder with a language model and is trained on the NISQA corpus using template-based question-answer pairs covering overall MOS and four perceptual dimensions (noisiness, coloration, discontinuity, and loudness) in both single-ended (degraded only) and double-ended (degraded plus clean reference) setups. Instead of directly regressing scores, our system is supervised to generate textual answers from which numeric predictions are parsed and evaluated with standard regression and ranking metrics; on held-out NISQA clips, the double-ended model attains a MOS mean absolute error (MAE) of 0.41 with Pearson correlation of 0.86, with competitive performance on dimension-wise tasks. Beyond these quantitative gains, it offers a flexible natural-language interface in which the language model acts as an audio quality expert: practitioners can query arbitrary aspects of degradations, prompt the model to emulate different listener profiles to capture human variability and produce diverse but plausible judgments rather than a single deterministic score, and thereby reduce reliance on large-scale crowdsourced tests and their monetary cost.
PortLLM: Personalizing Evolving Large Language Models with Training-Free and Portable Model Patches
Oct 08, 2024



As large language models (LLMs) increasingly shape the AI landscape, fine-tuning pretrained models has become more popular than in the pre-LLM era for achieving optimal performance in domain-specific tasks. However, pretrained LLMs such as ChatGPT are periodically evolved, i.e., model parameters are frequently updated), making it challenging for downstream users with limited resources to keep up with fine-tuning the newest LLMs for their domain application. Even though fine-tuning costs have nowadays been reduced thanks to the innovations of parameter-efficient fine-tuning such as LoRA, not all downstream users have adequate computing for frequent personalization. Moreover, access to fine-tuning datasets, particularly in sensitive domains such as healthcare, could be time-restrictive, making it crucial to retain the knowledge encoded in earlier fine-tuned rounds for future adaptation. In this paper, we present PortLLM, a training-free framework that (i) creates an initial lightweight model update patch to capture domain-specific knowledge, and (ii) allows a subsequent seamless plugging for the continual personalization of evolved LLM at minimal cost. Our extensive experiments cover seven representative datasets, from easier question-answering tasks {BoolQ, SST2} to harder reasoning tasks {WinoGrande, GSM8K}, and models including {Mistral-7B, Llama2, Llama3.1, and Gemma2}, validating the portability of our designed model patches and showcasing the effectiveness of our proposed framework. For instance, PortLLM achieves comparable performance to LoRA fine-tuning with reductions of up to 12.2x in GPU memory usage. Finally, we provide theoretical justifications to understand the portability of our model update patches, which offers new insights into the theoretical dimension of LLMs' personalization.
Characterizing Disparity Between Edge Models and High-Accuracy Base Models for Vision Tasks
Jul 13, 2024



Edge devices, with their widely varying capabilities, support a diverse range of edge AI models. This raises the question: how does an edge model differ from a high-accuracy (base) model for the same task? We introduce XDELTA, a novel explainable AI tool that explains differences between a high-accuracy base model and a computationally efficient but lower-accuracy edge model. To achieve this, we propose a learning-based approach to characterize the model difference, named the DELTA network, which complements the feature representation capability of the edge network in a compact form. To construct DELTA, we propose a sparsity optimization framework that extracts the essence of the base model to ensure compactness and sufficient feature representation capability of DELTA, and implement a negative correlation learning approach to ensure it complements the edge model. We conduct a comprehensive evaluation to test XDELTA's ability to explain model discrepancies, using over 1.2 million images and 24 models, and assessing real-world deployments with six participants. XDELTA excels in explaining differences between base and edge models (arbitrary pairs as well as compressed base models) through geometric and concept-level analysis, proving effective in real-world applications.
SensEmo: Enabling Affective Learning through Real-time Emotion Recognition with Smartwatches
Jul 13, 2024



Recent research has demonstrated the capability of physiological signals to infer both user emotional and attention responses. This presents an opportunity for leveraging widely available physiological sensors in smartwatches, to detect real-time emotional cues in users, such as stress and excitement. In this paper, we introduce SensEmo, a smartwatch-based system designed for affective learning. SensEmo utilizes multiple physiological sensor data, including heart rate and galvanic skin response, to recognize a student's motivation and concentration levels during class. This recognition is facilitated by a personalized emotion recognition model that predicts emotional states based on degrees of valence and arousal. With real-time emotion and attention feedback from students, we design a Markov decision process-based algorithm to enhance student learning effectiveness and experience by by offering suggestions to the teacher regarding teaching content and pacing. We evaluate SensEmo with 22 participants in real-world classroom environments. Evaluation results show that SensEmo recognizes student emotion with an average of 88.9% accuracy. More importantly, SensEmo assists students to achieve better online learning outcomes, e.g., an average of 40.0% higher grades in quizzes, over the traditional learning without student emotional feedback.
Data Distribution Dynamics in Real-World WiFi-Based Patient Activity Monitoring for Home Healthcare
Feb 03, 2024This paper examines the application of WiFi signals for real-world monitoring of daily activities in home healthcare scenarios. While the state-of-the-art of WiFi-based activity recognition is promising in lab environments, challenges arise in real-world settings due to environmental, subject, and system configuration variables, affecting accuracy and adaptability. The research involved deploying systems in various settings and analyzing data shifts. It aims to guide realistic development of robust, context-aware WiFi sensing systems for elderly care. The findings suggest a shift in WiFi-based activity sensing, bridging the gap between academic research and practical applications, enhancing life quality through technology.
SoundSieve: Seconds-Long Audio Event Recognition on Intermittently-Powered Systems
May 25, 2023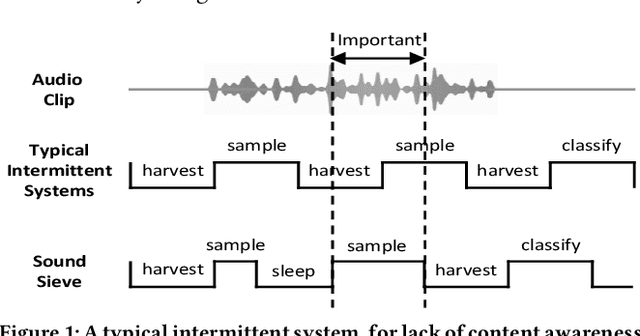
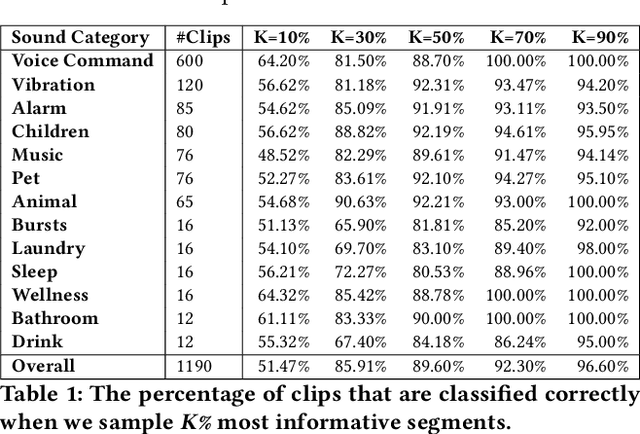
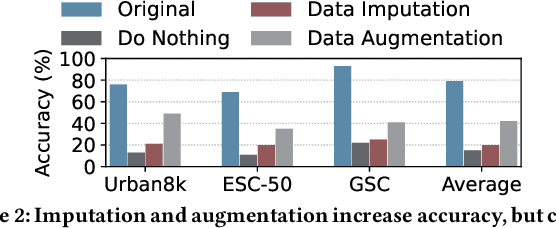
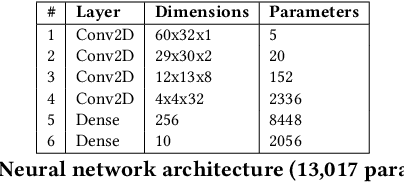
A fundamental problem of every intermittently-powered sensing system is that signals acquired by these systems over a longer period in time are also intermittent. As a consequence, these systems fail to capture parts of a longer-duration event that spans over multiple charge-discharge cycles of the capacitor that stores the harvested energy. From an application's perspective, this is viewed as sporadic bursts of missing values in the input data -- which may not be recoverable using statistical interpolation or imputation methods. In this paper, we study this problem in the light of an intermittent audio classification system and design an end-to-end system -- SoundSieve -- that is capable of accurately classifying audio events that span multiple on-off cycles of the intermittent system. SoundSieve employs an offline audio analyzer that learns to identify and predict important segments of an audio clip that must be sampled to ensure accurate classification of the audio. At runtime, SoundSieve employs a lightweight, energy- and content-aware audio sampler that decides when the system should wake up to capture the next chunk of audio; and a lightweight, intermittence-aware audio classifier that performs imputation and on-device inference. Through extensive evaluations using popular audio datasets as well as real systems, we demonstrate that SoundSieve yields 5%--30% more accurate inference results than the state-of-the-art.
CarFi: Rider Localization Using Wi-Fi CSI
Dec 21, 2022



With the rise of hailing services, people are increasingly relying on shared mobility (e.g., Uber, Lyft) drivers to pick up for transportation. However, such drivers and riders have difficulties finding each other in urban areas as GPS signals get blocked by skyscrapers, in crowded environments (e.g., in stadiums, airports, and bars), at night, and in bad weather. It wastes their time, creates a bad user experience, and causes more CO2 emissions due to idle driving. In this work, we explore the potential of Wi-Fi to help drivers to determine the street side of the riders. Our proposed system is called CarFi that uses Wi-Fi CSI from two antennas placed inside a moving vehicle and a data-driven technique to determine the street side of the rider. By collecting real-world data in realistic and challenging settings by blocking the signal with other people and other parked cars, we see that CarFi is 95.44% accurate in rider-side determination in both line of sight (LoS) and non-line of sight (nLoS) conditions, and can be run on an embedded GPU in real-time.