 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHIMERA: Compact Synthetic Data for Generalizable LLM Reasoning
Mar 01, 2026Large Language Models (LLMs) have recently exhibited remarkable reasoning capabilities, largely enabled by supervised fine-tuning (SFT)- and reinforcement learning (RL)-based post-training on high-quality reasoning data. However, reproducing and extending these capabilities in open and scalable settings is hindered by three fundamental data-centric challenges: (1) the cold-start problem, arising from the lack of seed datasets with detailed, long Chain-of-Thought (CoT) trajectories needed to initialize reasoning policies; (2) limited domain coverage, as most existing open-source reasoning datasets are concentrated in mathematics, with limited coverage of broader scientific disciplines; and (3) the annotation bottleneck, where the difficulty of frontier-level reasoning tasks makes reliable human annotation prohibitively expensive or infeasible. To address these challenges, we introduce CHIMERA, a compact synthetic reasoning dataset comprising 9K samples for generalizable cross-domain reasoning. CHIMERA is constructed with three key properties: (1) it provides rich, long CoT reasoning trajectories synthesized by state-of-the-art reasoning models; (2) it has broad and structured coverage, spanning 8 major scientific disciplines and over 1K fine-grained topics organized via a model-generated hierarchical taxonomy; and (3) it employs a fully automated, scalable evaluation pipeline that uses strong reasoning models to cross-validate both problem validity and answer correctness. We use CHIMERA to post-train a 4B Qwen3 model. Despite the dataset's modest size, the resulting model achieves strong performance on a suite of challenging reasoning benchmarks, including GPQA-Diamond, AIME 24/25/26, HMMT 25, and Humanity's Last Exam, approaching or matching the reasoning performance of substantially larger models such as DeepSeek-R1 and Qwen3-235B.
FlashSchNet: Fast and Accurate Coarse-Grained Neural Network Molecular Dynamics
Feb 13, 2026Graph neural network (GNN) potentials such as SchNet improve the accuracy and transferability of molecular dynamics (MD) simulation by learning many-body interactions, but remain slower than classical force fields due to fragmented kernels and memory-bound pipelines that underutilize GPUs. We show that a missing principle is making GNN-MD IO-aware, carefully accounting for reads and writes between GPU high-bandwidth memory (HBM) and on-chip SRAM. We present FlashSchNet, an efficient and accurate IO-aware SchNet-style GNN-MD framework built on four techniques: (1) flash radial basis, which fuses pairwise distance computation, Gaussian basis expansion, and cosine envelope into a single tiled pass, computing each distance once and reusing it across all basis functions; (2) flash message passing, which fuses cutoff, neighbor gather, filter multiplication, and reduction to avoid materializing edge tensors in HBM; (3) flash aggregation, which reformulates scatter-add via CSR segment reduce, reducing atomic writes by a factor of feature dimension and enabling contention-free accumulation in both forward and backward passes; (4) channel-wise 16-bit quantization that exploits the low per-channel dynamic range in SchNet MLP weights to further improve throughput with negligible accuracy loss. On a single NVIDIA RTX PRO 6000, FlashSchNet achieves 1000 ns/day aggregate simulation throughput over 64 parallel replicas on coarse-grained (CG) protein containing 269 beads (6.5x faster than CGSchNet baseline with 80% reduction of peak memory), surpassing classical force fields (e.g. MARTINI) while retaining SchNet-level accuracy and transferability.
Towards Building Non-Fine-Tunable Foundation Models
Jan 31, 2026Open-sourcing foundation models (FMs) enables broad reuse but also exposes model trainers to economic and safety risks from unrestricted downstream fine-tuning. We address this problem by building non-fine-tunable foundation models: models that remain broadly usable in their released form while yielding limited adaptation gains under task-agnostic unauthorized fine-tuning. We propose Private Mask Pre-Training (PMP), a pre-training framework that concentrates representation learning into a sparse subnetwork identified early in training. The binary mask defining this subnetwork is kept private, and only the final dense weights are released. This forces unauthorized fine-tuning without access to the mask to update parameters misaligned with pretraining subspace, inducing an intrinsic mismatch between the fine-tuning objective and the pre-training geometry. We provide theoretical analysis showing that this mismatch destabilizes gradient-based adaptation and bounds fine-tuning gains. Empirical results on large language models demonstrating that PMP preserves base model performance while consistently degrading unauthorized fine-tuning across a wide range of downstream tasks, with the strength of non-fine-tunability controlled by the mask ratio.
DOGe: Defensive Output Generation for LLM Protection Against Knowledge Distillation
May 26, 2025



Large Language Models (LLMs) represent substantial intellectual and economic investments, yet their effectiveness can inadvertently facilitate model imitation via knowledge distillation (KD).In practical scenarios, competitors can distill proprietary LLM capabilities by simply observing publicly accessible outputs, akin to reverse-engineering a complex performance by observation alone. Existing protective methods like watermarking only identify imitation post-hoc, while other defenses assume the student model mimics the teacher's internal logits, rendering them ineffective against distillation purely from observed output text. This paper confronts the challenge of actively protecting LLMs within the realistic constraints of API-based access. We introduce an effective and efficient Defensive Output Generation (DOGe) strategy that subtly modifies the output behavior of an LLM. Its outputs remain accurate and useful for legitimate users, yet are designed to be misleading for distillation, significantly undermining imitation attempts. We achieve this by fine-tuning only the final linear layer of the teacher LLM with an adversarial loss. This targeted training approach anticipates and disrupts distillation attempts during inference time. Our experiments show that, while preserving or even improving the original performance of the teacher model, student models distilled from the defensively generated teacher outputs demonstrate catastrophically reduced performance, demonstrating our method's effectiveness as a practical safeguard against KD-based model imitation.
Occult: Optimizing Collaborative Communication across Experts for Accelerated Parallel MoE Training and Inference
May 19, 2025Mixture-of-experts (MoE) architectures could achieve impressive computational efficiency with expert parallelism, which relies heavily on all-to-all communication across devices. Unfortunately, such communication overhead typically constitutes a significant portion of the total runtime, hampering the scalability of distributed training and inference for modern MoE models (consuming over $40\%$ runtime in large-scale training). In this paper, we first define collaborative communication to illustrate this intrinsic limitation, and then propose system- and algorithm-level innovations to reduce communication costs. Specifically, given a pair of experts co-activated by one token, we call them "collaborated", which comprises $2$ cases as intra- and inter-collaboration, depending on whether they are kept on the same device. Our pilot investigations reveal that augmenting the proportion of intra-collaboration can accelerate expert parallelism at scale. It motivates us to strategically optimize collaborative communication for accelerated MoE training and inference, dubbed Occult. Our designs are capable of either delivering exact results with reduced communication cost or controllably minimizing the cost with collaboration pruning, materialized by modified fine-tuning. Comprehensive experiments on various MoE-LLMs demonstrate that Occult can be faster than popular state-of-the-art inference or training frameworks (more than $1.5\times$ speed up across multiple tasks and models) with comparable or superior quality compared to the standard fine-tuning. Code is available at $\href{https://github.com/UNITES-Lab/Occult}{https://github.com/UNITES-Lab/Occult}$.
GroverGPT-2: Simulating Grover's Algorithm via Chain-of-Thought Reasoning and Quantum-Native Tokenization
May 08, 2025Quantum computing offers theoretical advantages over classical computing for specific tasks, yet the boundary of practical quantum advantage remains an open question. To investigate this boundary, it is crucial to understand whether, and how, classical machines can learn and simulate quantum algorithms. Recent progress in large language models (LLMs) has demonstrated strong reasoning abilities, prompting exploration into their potential for this challenge. In this work, we introduce GroverGPT-2, an LLM-based method for simulating Grover's algorithm using Chain-of-Thought (CoT) reasoning and quantum-native tokenization. Building on its predecessor, GroverGPT-2 performs simulation directly from quantum circuit representations while producing logically structured and interpretable outputs. Our results show that GroverGPT-2 can learn and internalize quantum circuit logic through efficient processing of quantum-native tokens, providing direct evidence that classical models like LLMs can capture the structure of quantum algorithms. Furthermore, GroverGPT-2 outputs interleave circuit data with natural language, embedding explicit reasoning into the simulation. This dual capability positions GroverGPT-2 as a prototype for advancing machine understanding of quantum algorithms and modeling quantum circuit logic. We also identify an empirical scaling law for GroverGPT-2 with increasing qubit numbers, suggesting a path toward scalable classical simulation. These findings open new directions for exploring the limits of classical simulatability, enhancing quantum education and research, and laying groundwork for future foundation models in quantum computing.
Finding Fantastic Experts in MoEs: A Unified Study for Expert Dropping Strategies and Observations
Apr 10, 2025Sparsely activated Mixture-of-Experts (SMoE) has shown promise in scaling up the learning capacity of neural networks. However, vanilla SMoEs have issues such as expert redundancy and heavy memory requirements, making them inefficient and non-scalable, especially for resource-constrained scenarios. Expert-level sparsification of SMoEs involves pruning the least important experts to address these limitations. In this work, we aim to address three questions: (1) What is the best recipe to identify the least knowledgeable subset of experts that can be dropped with minimal impact on performance? (2) How should we perform expert dropping (one-shot or iterative), and what correction measures can we undertake to minimize its drastic impact on SMoE subnetwork capabilities? (3) What capabilities of full-SMoEs are severely impacted by the removal of the least dominant experts, and how can we recover them? Firstly, we propose MoE Experts Compression Suite (MC-Suite), which is a collection of some previously explored and multiple novel recipes to provide a comprehensive benchmark for estimating expert importance from diverse perspectives, as well as unveil numerous valuable insights for SMoE experts. Secondly, unlike prior works with a one-shot expert pruning approach, we explore the benefits of iterative pruning with the re-estimation of the MC-Suite criterion. Moreover, we introduce the benefits of task-agnostic fine-tuning as a correction mechanism during iterative expert dropping, which we term MoE Lottery Subnetworks. Lastly, we present an experimentally validated conjecture that, during expert dropping, SMoEs' instruction-following capabilities are predominantly hurt, which can be restored to a robust level subject to external augmentation of instruction-following capabilities using k-shot examples and supervised fine-tuning.
Advancing MoE Efficiency: A Collaboration-Constrained Routing (C2R) Strategy for Better Expert Parallelism Design
Apr 02, 2025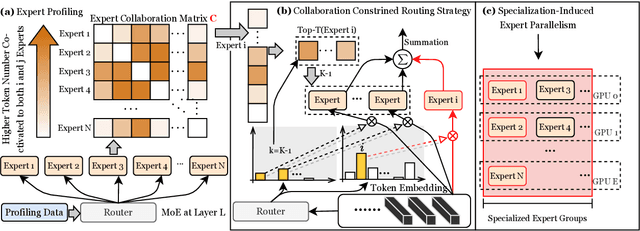
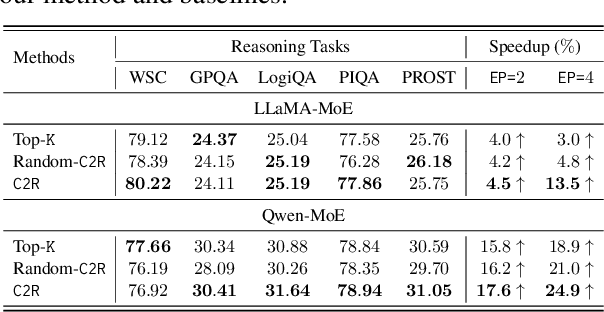
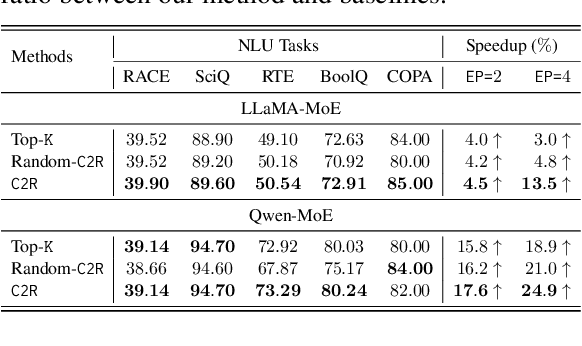
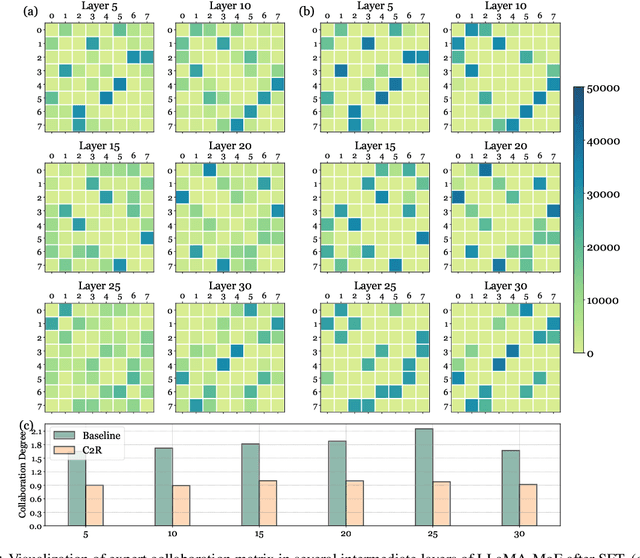
Mixture-of-Experts (MoE) has successfully scaled up models while maintaining nearly constant computing costs. By employing a gating network to route input tokens, it selectively activates a subset of expert networks to process the corresponding token embeddings. However, in practice, the efficiency of MoE is challenging to achieve due to two key reasons: imbalanced expert activation, which leads to substantial idle time during model or expert parallelism, and insufficient capacity utilization; massive communication overhead, induced by numerous expert routing combinations in expert parallelism at the system level. Previous works typically formulate it as the load imbalance issue characterized by the gating network favoring certain experts over others or attribute it to static execution which fails to adapt to the dynamic expert workload at runtime. In this paper, we exploit it from a brand new perspective, a higher-order view and analysis of MoE routing policies: expert collaboration and specialization where some experts tend to activate broadly with others (collaborative), while others are more likely to activate only with a specific subset of experts (specialized). Our experiments reveal that most experts tend to be overly collaborative, leading to increased communication overhead from repeatedly sending tokens to different accelerators. To this end, we propose a novel collaboration-constrained routing (C2R) strategy to encourage more specialized expert groups, as well as to improve expert utilization, and present an efficient implementation of MoE that further leverages expert specialization. We achieve an average performance improvement of 0.51% and 0.33% on LLaMA-MoE and Qwen-MoE respectively across ten downstream NLP benchmarks, and reduce the all2all communication costs between GPUs, bringing an extra 20%-30% total running time savings on top of the existing SoTA, i.e. MegaBlocks.
ORAL: Prompting Your Large-Scale LoRAs via Conditional Recurrent Diffusion
Mar 31, 2025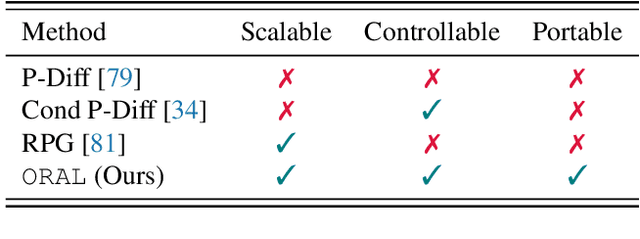
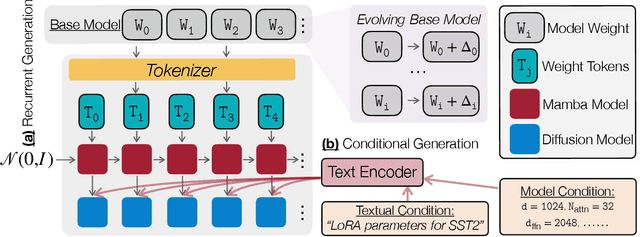
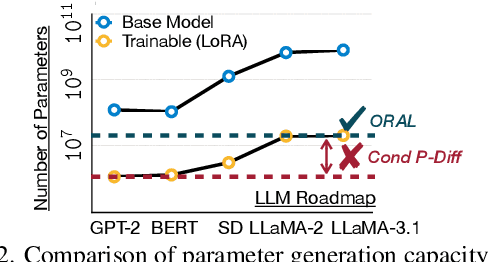

Parameter generation has emerged as a novel paradigm for neural network development, offering an alternative to traditional neural network training by synthesizing high-quality model weights directly. In the context of Low-Rank Adaptation (LoRA) for evolving ($\textit{i.e.}$, constantly updated) large language models (LLMs), this approach promises efficient adaptation without costly retraining. However, existing methods face critical limitations in simultaneously achieving scalability and controllability. In this paper, we introduce $\texttt{ORAL}$, a novel $\textbf{conditional recurrent diffusion}$ framework that addresses these challenges. $\texttt{ORAL}$ incorporates a novel conditioning mechanism that integrates model architecture and textual task specifications, enabling the generation of task-specific LoRA parameters that can seamlessly transfer across evolving foundation models. Our approach successfully scales to billions-of-parameter LLMs and maintains controllability. Through extensive experiments across seven language tasks, four vision tasks, and three multimodal tasks using five pre-trained LLMs, we demonstrate that $\texttt{ORAL}$ generates high-quality LoRA parameters that achieve comparable or superior performance to vanilla trained counterparts.
Make Optimization Once and for All with Fine-grained Guidance
Mar 14, 2025Learning to Optimize (L2O) enhances optimization efficiency with integrated neural networks. L2O paradigms achieve great outcomes, e.g., refitting optimizer, generating unseen solutions iteratively or directly. However, conventional L2O methods require intricate design and rely on specific optimization processes, limiting scalability and generalization. Our analyses explore general framework for learning optimization, called Diff-L2O, focusing on augmenting sampled solutions from a wider view rather than local updates in real optimization process only. Meanwhile, we give the related generalization bound, showing that the sample diversity of Diff-L2O brings better performance. This bound can be simply applied to other fields, discussing diversity, mean-variance, and different tasks. Diff-L2O's strong compatibility is empirically verified with only minute-level training, comparing with other hour-levels.