 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReusing Pre-Training Data at Test Time is a Compute Multiplier
Nov 06, 2025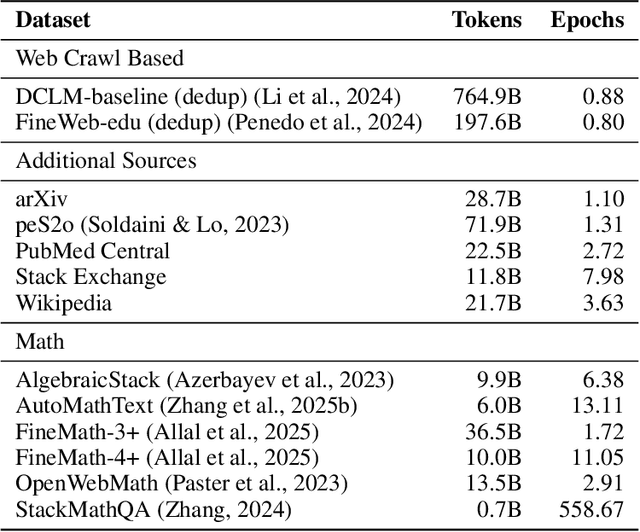
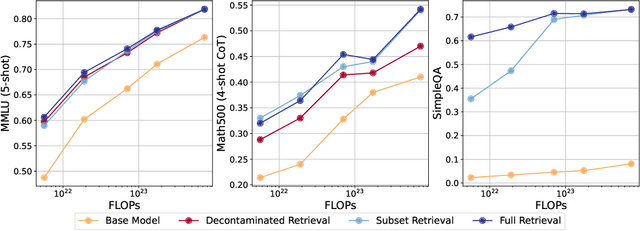
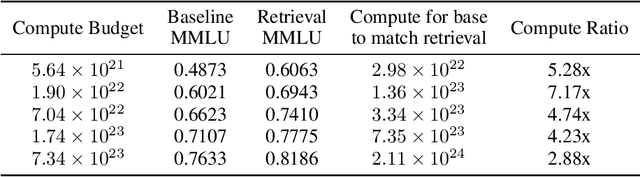
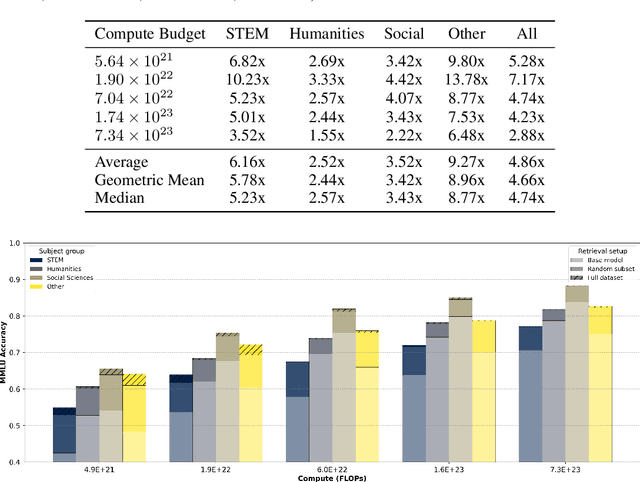
Large language models learn from their vast pre-training corpora, gaining the ability to solve an ever increasing variety of tasks; yet although researchers work to improve these datasets, there is little effort to understand how efficient the pre-training apparatus is at extracting ideas and knowledge from the data. In this work, we use retrieval augmented generation along with test-time compute as a way to quantify how much dataset value was left behind by the process of pre-training, and how this changes across scale. We demonstrate that pre-training then retrieving from standard and largely open-sourced datasets results in significant accuracy gains in MMLU, Math-500, and SimpleQA, which persist through decontamination. For MMLU we observe that retrieval acts as a ~5x compute multiplier versus pre-training alone. We show that these results can be further improved by leveraging additional compute at test time to parse the retrieved context, demonstrating a 10 percentage point improvement on MMLU for the public LLaMA 3.1 8B model. Overall, our results suggest that today's pre-training methods do not make full use of the information in existing pre-training datasets, leaving significant room for progress.
MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Sep 19, 2025
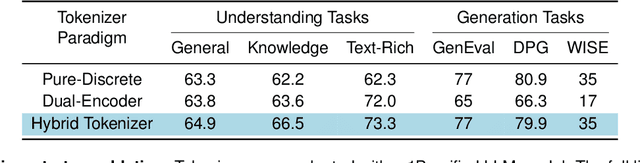
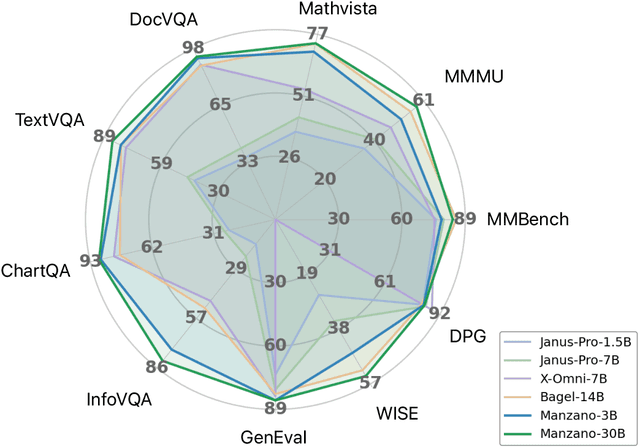
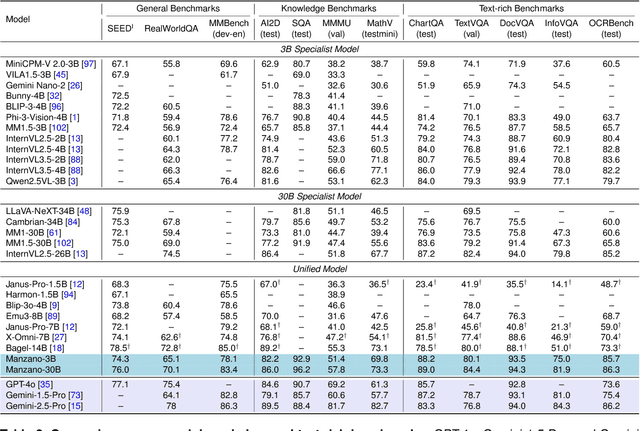
Unified multimodal Large Language Models (LLMs) that can both understand and generate visual content hold immense potential. However, existing open-source models often suffer from a performance trade-off between these capabilities. We present Manzano, a simple and scalable unified framework that substantially reduces this tension by coupling a hybrid image tokenizer with a well-curated training recipe. A single shared vision encoder feeds two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a common semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels. The architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation. Our studies show minimal task conflicts and consistent gains from scaling model size, validating our design choice of a hybrid tokenizer.
Synthetic bootstrapped pretraining
Sep 17, 2025We introduce Synthetic Bootstrapped Pretraining (SBP), a language model (LM) pretraining procedure that first learns a model of relations between documents from the pretraining dataset and then leverages it to synthesize a vast new corpus for joint training. While the standard pretraining teaches LMs to learn causal correlations among tokens within a single document, it is not designed to efficiently model the rich, learnable inter-document correlations that can potentially lead to better performance. We validate SBP by designing a compute-matched pretraining setup and pretrain a 3B-parameter model on up to 1T tokens from scratch. We find SBP consistently improves upon a strong repetition baseline and delivers a significant fraction of performance improvement attainable by an oracle upper bound with access to 20x more unique data. Qualitative analysis reveals that the synthesized documents go beyond mere paraphrases -- SBP first abstracts a core concept from the seed material and then crafts a new narration on top of it. Besides strong empirical performance, SBP admits a natural Bayesian interpretation: the synthesizer implicitly learns to abstract the latent concepts shared between related documents.
Can External Validation Tools Improve Annotation Quality for LLM-as-a-Judge?
Jul 22, 2025Pairwise preferences over model responses are widely collected to evaluate and provide feedback to large language models (LLMs). Given two alternative model responses to the same input, a human or AI annotator selects the "better" response. This approach can provide feedback for domains where other hard-coded metrics are difficult to obtain (e.g., chat response quality), thereby helping model evaluation or training. However, for some domains high-quality pairwise comparisons can be tricky to obtain - from AI and humans. For example, for responses with many factual statements, annotators may disproportionately weigh writing quality rather than underlying facts. In this work, we explore augmenting standard AI annotator systems with additional tools to improve performance on three challenging response domains: long-form factual, math and code tasks. We propose a tool-using agentic system to provide higher quality feedback on these domains. Our system uses web-search and code execution to ground itself based on external validation, independent of the LLM's internal knowledge and biases. We provide extensive experimental results evaluating our method across the three targeted response domains as well as general annotation tasks, using RewardBench (incl. AlpacaEval and LLMBar), RewardMath, as well as three new datasets for domains with saturated pre-existing datasets. Our results indicate that external tools can indeed improve performance in many, but not all, cases. More generally, our experiments highlight the sensitivity of performance to simple parameters (e.g., prompt) and the need for improved (non-saturated) annotator benchmarks. We share our code at https://github.com/apple/ml-agent-evaluator.
RATTENTION: Towards the Minimal Sliding Window Size in Local-Global Attention Models
Jun 18, 2025Local-global attention models have recently emerged as compelling alternatives to standard Transformers, promising improvements in both training and inference efficiency. However, the crucial choice of window size presents a Pareto tradeoff: larger windows maintain performance akin to full attention but offer minimal efficiency gains in short-context scenarios, while smaller windows can lead to performance degradation. Current models, such as Gemma2 and Mistral, adopt conservative window sizes (e.g., 4096 out of an 8192 pretraining length) to preserve performance. This work investigates strategies to shift this Pareto frontier, enabling local-global models to achieve efficiency gains even in short-context regimes. Our core motivation is to address the intrinsic limitation of local attention -- its complete disregard for tokens outside the defined window. We explore RATTENTION, a variant of local attention integrated with a specialized linear attention mechanism designed to capture information from these out-of-window tokens. Pretraining experiments at the 3B and 12B scales demonstrate that RATTENTION achieves a superior Pareto tradeoff between performance and efficiency. As a sweet spot, RATTENTION with a window size of just 512 consistently matches the performance of full-attention models across diverse settings. Furthermore, the recurrent nature inherent in the linear attention component of RATTENTION contributes to enhanced long-context performance, as validated on the RULER benchmark. Crucially, these improvements do not compromise training efficiency; thanks to a specialized kernel implementation and the reduced window size, RATTENTION maintains training speeds comparable to existing state-of-the-art approaches.
Finding Fantastic Experts in MoEs: A Unified Study for Expert Dropping Strategies and Observations
Apr 10, 2025Sparsely activated Mixture-of-Experts (SMoE) has shown promise in scaling up the learning capacity of neural networks. However, vanilla SMoEs have issues such as expert redundancy and heavy memory requirements, making them inefficient and non-scalable, especially for resource-constrained scenarios. Expert-level sparsification of SMoEs involves pruning the least important experts to address these limitations. In this work, we aim to address three questions: (1) What is the best recipe to identify the least knowledgeable subset of experts that can be dropped with minimal impact on performance? (2) How should we perform expert dropping (one-shot or iterative), and what correction measures can we undertake to minimize its drastic impact on SMoE subnetwork capabilities? (3) What capabilities of full-SMoEs are severely impacted by the removal of the least dominant experts, and how can we recover them? Firstly, we propose MoE Experts Compression Suite (MC-Suite), which is a collection of some previously explored and multiple novel recipes to provide a comprehensive benchmark for estimating expert importance from diverse perspectives, as well as unveil numerous valuable insights for SMoE experts. Secondly, unlike prior works with a one-shot expert pruning approach, we explore the benefits of iterative pruning with the re-estimation of the MC-Suite criterion. Moreover, we introduce the benefits of task-agnostic fine-tuning as a correction mechanism during iterative expert dropping, which we term MoE Lottery Subnetworks. Lastly, we present an experimentally validated conjecture that, during expert dropping, SMoEs' instruction-following capabilities are predominantly hurt, which can be restored to a robust level subject to external augmentation of instruction-following capabilities using k-shot examples and supervised fine-tuning.
Talking Turns: Benchmarking Audio Foundation Models on Turn-Taking Dynamics
Mar 03, 2025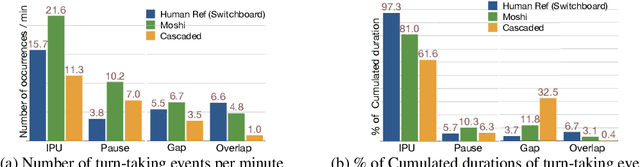

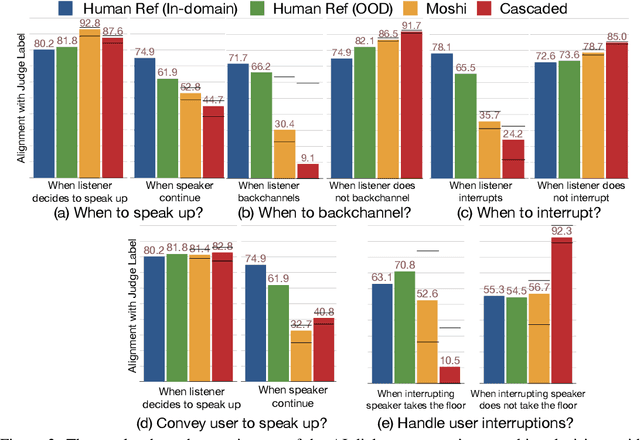

The recent wave of audio foundation models (FMs) could provide new capabilities for conversational modeling. However, there have been limited efforts to evaluate these audio FMs comprehensively on their ability to have natural and interactive conversations. To engage in meaningful conversation with the end user, we would want the FMs to additionally perform a fluent succession of turns without too much overlapping speech or long stretches of silence. Inspired by this, we ask whether the recently proposed audio FMs can understand, predict, and perform turn-taking events? To answer this, we propose a novel evaluation protocol that can assess spoken dialog system's turn-taking capabilities using a supervised model as a judge that has been trained to predict turn-taking events in human-human conversations. Using this protocol, we present the first comprehensive user study that evaluates existing spoken dialogue systems on their ability to perform turn-taking events and reveal many interesting insights, such as they sometimes do not understand when to speak up, can interrupt too aggressively and rarely backchannel. We further evaluate multiple open-source and proprietary audio FMs accessible through APIs on carefully curated test benchmarks from Switchboard to measure their ability to understand and predict turn-taking events and identify significant room for improvement. We will open source our evaluation platform to promote the development of advanced conversational AI systems.
Instruction-Following Pruning for Large Language Models
Jan 07, 2025



With the rapid scaling of large language models (LLMs), structured pruning has become a widely used technique to learn efficient, smaller models from larger ones, delivering superior performance compared to training similarly sized models from scratch. In this paper, we move beyond the traditional static pruning approach of determining a fixed pruning mask for a model, and propose a dynamic approach to structured pruning. In our method, the pruning mask is input-dependent and adapts dynamically based on the information described in a user instruction. Our approach, termed "instruction-following pruning", introduces a sparse mask predictor that takes the user instruction as input and dynamically selects the most relevant model parameters for the given task. To identify and activate effective parameters, we jointly optimize the sparse mask predictor and the LLM, leveraging both instruction-following data and the pre-training corpus. Experimental results demonstrate the effectiveness of our approach on a wide range of evaluation benchmarks. For example, our 3B activated model improves over the 3B dense model by 5-8 points of absolute margin on domains such as math and coding, and rivals the performance of a 9B model.
Improve Vision Language Model Chain-of-thought Reasoning
Oct 21, 2024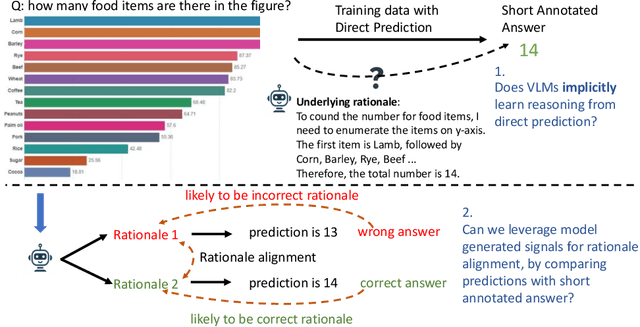


Chain-of-thought (CoT) reasoning in vision language models (VLMs) is crucial for improving interpretability and trustworthiness. However, current training recipes lack robust CoT reasoning data, relying on datasets dominated by short annotations with minimal rationales. In this work, we show that training VLM on short answers does not generalize well to reasoning tasks that require more detailed responses. To address this, we propose a two-fold approach. First, we distill rationales from GPT-4o model to enrich the training data and fine-tune VLMs, boosting their CoT performance. Second, we apply reinforcement learning to further calibrate reasoning quality. Specifically, we construct positive (correct) and negative (incorrect) pairs of model-generated reasoning chains, by comparing their predictions with annotated short answers. Using this pairwise data, we apply the Direct Preference Optimization algorithm to refine the model's reasoning abilities. Our experiments demonstrate significant improvements in CoT reasoning on benchmark datasets and better generalization to direct answer prediction as well. This work emphasizes the importance of incorporating detailed rationales in training and leveraging reinforcement learning to strengthen the reasoning capabilities of VLMs.
EC-DIT: Scaling Diffusion Transformers with Adaptive Expert-Choice Routing
Oct 02, 2024



Diffusion transformers have been widely adopted for text-to-image synthesis. While scaling these models up to billions of parameters shows promise, the effectiveness of scaling beyond current sizes remains underexplored and challenging. By explicitly exploiting the computational heterogeneity of image generations, we develop a new family of Mixture-of-Experts (MoE) models (EC-DIT) for diffusion transformers with expert-choice routing. EC-DIT learns to adaptively optimize the compute allocated to understand the input texts and generate the respective image patches, enabling heterogeneous computation aligned with varying text-image complexities. This heterogeneity provides an efficient way of scaling EC-DIT up to 97 billion parameters and achieving significant improvements in training convergence, text-to-image alignment, and overall generation quality over dense models and conventional MoE models. Through extensive ablations, we show that EC-DIT demonstrates superior scalability and adaptive compute allocation by recognizing varying textual importance through end-to-end training. Notably, in text-to-image alignment evaluation, our largest models achieve a state-of-the-art GenEval score of 71.68% and still maintain competitive inference speed with intuitive interpretability.