 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Track Transformers: Enabling Fast GPU Inference with Reduced Synchronization
Feb 07, 2026Efficient large-scale inference of transformer-based large language models (LLMs) remains a fundamental systems challenge, frequently requiring multi-GPU parallelism to meet stringent latency and throughput targets. Conventional tensor parallelism decomposes matrix operations across devices but introduces substantial inter-GPU synchronization, leading to communication bottlenecks and degraded scalability. We propose the Parallel Track (PT) Transformer, a novel architectural paradigm that restructures computation to minimize cross-device dependencies. PT achieves up to a 16x reduction in synchronization operations relative to standard tensor parallelism, while maintaining competitive model quality in our experiments. We integrate PT into two widely adopted LLM serving stacks-Tensor-RT-LLM and vLLM-and report consistent improvements in serving efficiency, including up to 15-30% reduced time to first token, 2-12% reduced time per output token, and up to 31.90% increased throughput in both settings.
S$^2$R: Teaching LLMs to Self-verify and Self-correct via Reinforcement Learning
Feb 18, 2025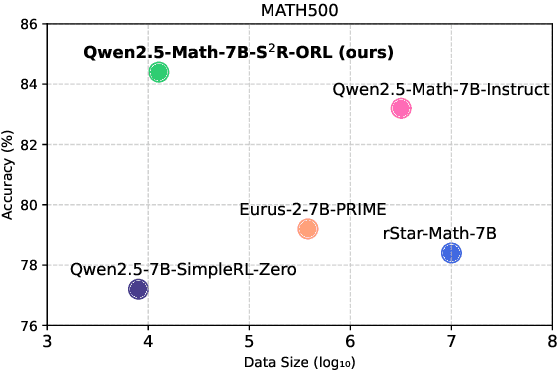
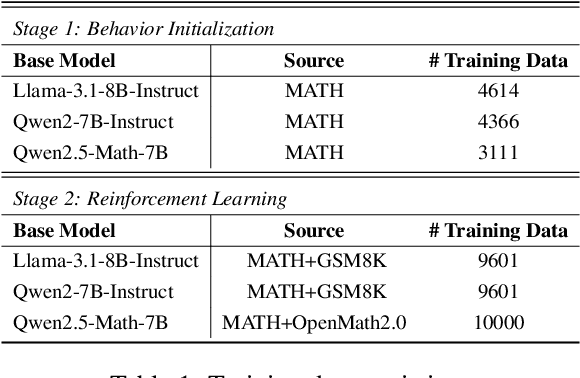
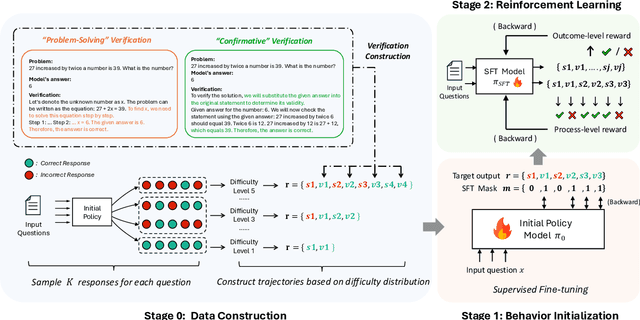
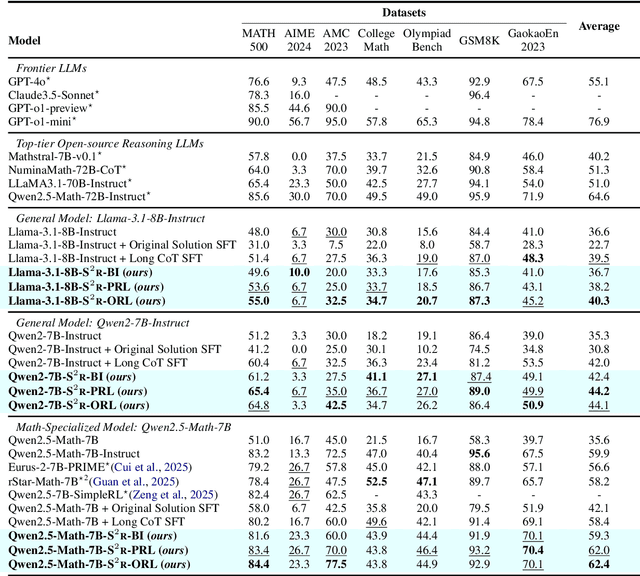
Recent studies have demonstrated the effectiveness of LLM test-time scaling. However, existing approaches to incentivize LLMs' deep thinking abilities generally require large-scale data or significant training efforts. Meanwhile, it remains unclear how to improve the thinking abilities of less powerful base models. In this work, we introduce S$^2$R, an efficient framework that enhances LLM reasoning by teaching models to self-verify and self-correct during inference. Specifically, we first initialize LLMs with iterative self-verification and self-correction behaviors through supervised fine-tuning on carefully curated data. The self-verification and self-correction skills are then further strengthened by both outcome-level and process-level reinforcement learning, with minimized resource requirements, enabling the model to adaptively refine its reasoning process during inference. Our results demonstrate that, with only 3.1k self-verifying and self-correcting behavior initialization samples, Qwen2.5-math-7B achieves an accuracy improvement from 51.0\% to 81.6\%, outperforming models trained on an equivalent amount of long-CoT distilled data. Extensive experiments and analysis based on three base models across both in-domain and out-of-domain benchmarks validate the effectiveness of S$^2$R. Our code and data are available at https://github.com/NineAbyss/S2R.
From Visuals to Vocabulary: Establishing Equivalence Between Image and Text Token Through Autoregressive Pre-training in MLLMs
Feb 13, 2025
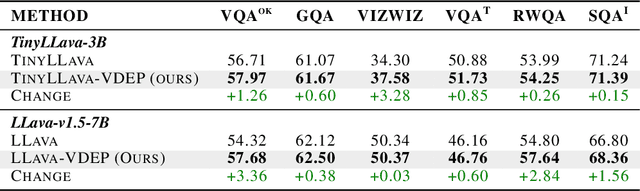
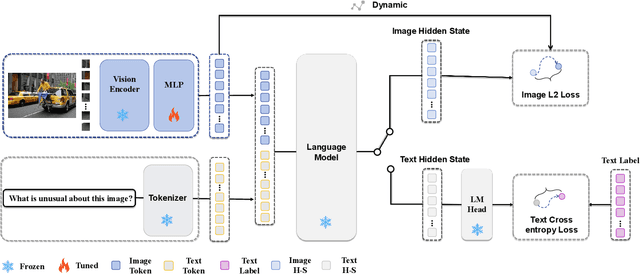
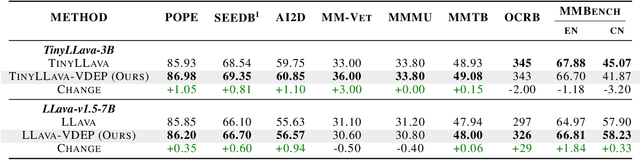
While MLLMs perform well on perceptual tasks, they lack precise multimodal alignment, limiting performance. To address this challenge, we propose Vision Dynamic Embedding-Guided Pretraining (VDEP), a hybrid autoregressive training paradigm for MLLMs. Utilizing dynamic embeddings from the MLP following the visual encoder, this approach supervises image hidden states and integrates image tokens into autoregressive training. Existing MLLMs primarily focused on recovering information from textual inputs, often neglecting the effective processing of image data. In contrast, the key improvement of this work is the reinterpretation of multimodal alignment as a process of recovering information from input data, with particular emphasis on reconstructing detailed visual features.The proposed method seamlessly integrates into standard models without architectural changes. Experiments on 13 benchmarks show VDEP outperforms baselines, surpassing existing methods.
Advancing General Multimodal Capability of Vision-language Models with Pyramid-descent Visual Position Encoding
Jan 19, 2025Vision-language Models (VLMs) have shown remarkable capabilities in advancing general artificial intelligence, yet the irrational encoding of visual positions persists in inhibiting the models' comprehensive perception performance across different levels of granularity. In this work, we propose Pyramid-descent Visual Position Encoding (PyPE), a novel approach designed to enhance the perception of visual tokens within VLMs. By assigning visual position indexes from the periphery to the center and expanding the central receptive field incrementally, PyPE addresses the limitations of traditional raster-scan methods and mitigates the long-term decay effects induced by Rotary Position Embedding (RoPE). Our method reduces the relative distance between interrelated visual elements and instruction tokens, promoting a more rational allocation of attention weights and allowing for a multi-granularity perception of visual elements and countering the over-reliance on anchor tokens. Extensive experimental evaluations demonstrate that PyPE consistently improves the general capabilities of VLMs across various sizes. Code is available at https://github.com/SakuraTroyChen/PyPE.
Instruction-Following Pruning for Large Language Models
Jan 07, 2025



With the rapid scaling of large language models (LLMs), structured pruning has become a widely used technique to learn efficient, smaller models from larger ones, delivering superior performance compared to training similarly sized models from scratch. In this paper, we move beyond the traditional static pruning approach of determining a fixed pruning mask for a model, and propose a dynamic approach to structured pruning. In our method, the pruning mask is input-dependent and adapts dynamically based on the information described in a user instruction. Our approach, termed "instruction-following pruning", introduces a sparse mask predictor that takes the user instruction as input and dynamically selects the most relevant model parameters for the given task. To identify and activate effective parameters, we jointly optimize the sparse mask predictor and the LLM, leveraging both instruction-following data and the pre-training corpus. Experimental results demonstrate the effectiveness of our approach on a wide range of evaluation benchmarks. For example, our 3B activated model improves over the 3B dense model by 5-8 points of absolute margin on domains such as math and coding, and rivals the performance of a 9B model.
Adapting to Non-Stationary Environments: Multi-Armed Bandit Enhanced Retrieval-Augmented Generation on Knowledge Graphs
Dec 10, 2024



Despite the superior performance of Large language models on many NLP tasks, they still face significant limitations in memorizing extensive world knowledge. Recent studies have demonstrated that leveraging the Retrieval-Augmented Generation (RAG) framework, combined with Knowledge Graphs that encapsulate extensive factual data in a structured format, robustly enhances the reasoning capabilities of LLMs. However, deploying such systems in real-world scenarios presents challenges: the continuous evolution of non-stationary environments may lead to performance degradation and user satisfaction requires a careful balance of performance and responsiveness. To address these challenges, we introduce a Multi-objective Multi-Armed Bandit enhanced RAG framework, supported by multiple retrieval methods with diverse capabilities under rich and evolving retrieval contexts in practice. Within this framework, each retrieval method is treated as a distinct ``arm''. The system utilizes real-time user feedback to adapt to dynamic environments, by selecting the appropriate retrieval method based on input queries and the historical multi-objective performance of each arm. Extensive experiments conducted on two benchmark KGQA datasets demonstrate that our method significantly outperforms baseline methods in non-stationary settings while achieving state-of-the-art performance in stationary environments. Code and data are available at https://github.com/FUTUREEEEEE/Dynamic-RAG.git
MBA-RAG: a Bandit Approach for Adaptive Retrieval-Augmented Generation through Question Complexity
Dec 03, 2024



Retrieval Augmented Generation (RAG) has proven to be highly effective in boosting the generative performance of language model in knowledge-intensive tasks. However, existing RAG framework either indiscriminately perform retrieval or rely on rigid single-class classifiers to select retrieval methods, leading to inefficiencies and suboptimal performance across queries of varying complexity. To address these challenges, we propose a reinforcement learning-based framework that dynamically selects the most suitable retrieval strategy based on query complexity. % our solution Our approach leverages a multi-armed bandit algorithm, which treats each retrieval method as a distinct ``arm'' and adapts the selection process by balancing exploration and exploitation. Additionally, we introduce a dynamic reward function that balances accuracy and efficiency, penalizing methods that require more retrieval steps, even if they lead to a correct result. Our method achieves new state of the art results on multiple single-hop and multi-hop datasets while reducing retrieval costs. Our code are available at https://github.com/FUTUREEEEEE/MBA .
EC-DIT: Scaling Diffusion Transformers with Adaptive Expert-Choice Routing
Oct 02, 2024



Diffusion transformers have been widely adopted for text-to-image synthesis. While scaling these models up to billions of parameters shows promise, the effectiveness of scaling beyond current sizes remains underexplored and challenging. By explicitly exploiting the computational heterogeneity of image generations, we develop a new family of Mixture-of-Experts (MoE) models (EC-DIT) for diffusion transformers with expert-choice routing. EC-DIT learns to adaptively optimize the compute allocated to understand the input texts and generate the respective image patches, enabling heterogeneous computation aligned with varying text-image complexities. This heterogeneity provides an efficient way of scaling EC-DIT up to 97 billion parameters and achieving significant improvements in training convergence, text-to-image alignment, and overall generation quality over dense models and conventional MoE models. Through extensive ablations, we show that EC-DIT demonstrates superior scalability and adaptive compute allocation by recognizing varying textual importance through end-to-end training. Notably, in text-to-image alignment evaluation, our largest models achieve a state-of-the-art GenEval score of 71.68% and still maintain competitive inference speed with intuitive interpretability.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Deep State-Space Generative Model For Correlated Time-to-Event Predictions
Jul 28, 2024



Capturing the inter-dependencies among multiple types of clinically-critical events is critical not only to accurate future event prediction, but also to better treatment planning. In this work, we propose a deep latent state-space generative model to capture the interactions among different types of correlated clinical events (e.g., kidney failure, mortality) by explicitly modeling the temporal dynamics of patients' latent states. Based on these learned patient states, we further develop a new general discrete-time formulation of the hazard rate function to estimate the survival distribution of patients with significantly improved accuracy. Extensive evaluations over real EMR data show that our proposed model compares favorably to various state-of-the-art baselines. Furthermore, our method also uncovers meaningful insights about the latent correlations among mortality and different types of organ failures.