 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAG-3DSG: Enhancing 3D Scene Graphs with Re-Shot Guided Retrieval-Augmented Generation
Jan 15, 2026Open-vocabulary 3D Scene Graph (3DSG) generation can enhance various downstream tasks in robotics, such as manipulation and navigation, by leveraging structured semantic representations. A 3DSG is constructed from multiple images of a scene, where objects are represented as nodes and relationships as edges. However, existing works for open-vocabulary 3DSG generation suffer from both low object-level recognition accuracy and speed, mainly due to constrained viewpoints, occlusions, and redundant surface density. To address these challenges, we propose RAG-3DSG to mitigate aggregation noise through re-shot guided uncertainty estimation and support object-level Retrieval-Augmented Generation (RAG) via reliable low-uncertainty objects. Furthermore, we propose a dynamic downsample-mapping strategy to accelerate cross-image object aggregation with adaptive granularity. Experiments on Replica dataset demonstrate that RAG-3DSG significantly improves node captioning accuracy in 3DSG generation while reducing the mapping time by two-thirds compared to the vanilla version.
GFM4GA: Graph Foundation Model for Group Anomaly Detection
Jan 15, 2026Group anomaly detection is crucial in many network applications, but faces challenges due to diverse anomaly patterns. Motivated by the success of large language models (LLMs) in natural language processing, graph foundation models (GFMs) is proposed to handle few-shot learning task with fewer labeling efforts. GFMs have been successfully applied to detection of individual anomalies but cannot be generalized to group anomalies, as group anomaly patterns must be detected as a whole and individuals in an abnormal group can look rather normal. Therefore, we propose GFM4GA, a novel graph foundation model for group anomaly detection. The pipeline is pretrained via dual-level contrastive learning based on feature-based estimation and group extraction, to capture potential group anomaly structure and feature inconsistencies. In the downstream tasks, the pipeline is finetuned in parameter-constrained and group-anomaly-proportion weighted few-shot settings, and its adaptive ability to unseen group anomalies expanded via group contexts determined by labeled anomaly neighbors. Experiments show that GFM4GA surpasses group anomaly detectors and GFMs for individual anomalies, achieving average improvements of 2.85% in AUROC and 2.55% in AUPRC.
SSFO: Self-Supervised Faithfulness Optimization for Retrieval-Augmented Generation
Aug 24, 2025Retrieval-Augmented Generation (RAG) systems require Large Language Models (LLMs) to generate responses that are faithful to the retrieved context. However, faithfulness hallucination remains a critical challenge, as existing methods often require costly supervision and post-training or significant inference burdens. To overcome these limitations, we introduce Self-Supervised Faithfulness Optimization (SSFO), the first self-supervised alignment approach for enhancing RAG faithfulness. SSFO constructs preference data pairs by contrasting the model's outputs generated with and without the context. Leveraging Direct Preference Optimization (DPO), SSFO aligns model faithfulness without incurring labeling costs or additional inference burden. We theoretically and empirically demonstrate that SSFO leverages a benign form of \emph{likelihood displacement}, transferring probability mass from parametric-based tokens to context-aligned tokens. Based on this insight, we propose a modified DPO loss function to encourage likelihood displacement. Comprehensive evaluations show that SSFO significantly outperforms existing methods, achieving state-of-the-art faithfulness on multiple context-based question-answering datasets. Notably, SSFO exhibits strong generalization, improving cross-lingual faithfulness and preserving general instruction-following capabilities. We release our code and model at the anonymous link: https://github.com/chkwy/SSFO
CogniBench: A Legal-inspired Framework and Dataset for Assessing Cognitive Faithfulness of Large Language Models
May 28, 2025Faithfulness hallucination are claims generated by a Large Language Model (LLM) not supported by contexts provided to the LLM. Lacking assessment standard, existing benchmarks only contain "factual statements" that rephrase source materials without marking "cognitive statements" that make inference from the given context, making the consistency evaluation and optimization of cognitive statements difficult. Inspired by how an evidence is assessed in the legislative domain, we design a rigorous framework to assess different levels of faithfulness of cognitive statements and create a benchmark dataset where we reveal insightful statistics. We design an annotation pipeline to create larger benchmarks for different LLMs automatically, and the resulting larger-scale CogniBench-L dataset can be used to train accurate cognitive hallucination detection model. We release our model and dataset at: https://github.com/FUTUREEEEEE/CogniBench
Adapting to Non-Stationary Environments: Multi-Armed Bandit Enhanced Retrieval-Augmented Generation on Knowledge Graphs
Dec 10, 2024



Despite the superior performance of Large language models on many NLP tasks, they still face significant limitations in memorizing extensive world knowledge. Recent studies have demonstrated that leveraging the Retrieval-Augmented Generation (RAG) framework, combined with Knowledge Graphs that encapsulate extensive factual data in a structured format, robustly enhances the reasoning capabilities of LLMs. However, deploying such systems in real-world scenarios presents challenges: the continuous evolution of non-stationary environments may lead to performance degradation and user satisfaction requires a careful balance of performance and responsiveness. To address these challenges, we introduce a Multi-objective Multi-Armed Bandit enhanced RAG framework, supported by multiple retrieval methods with diverse capabilities under rich and evolving retrieval contexts in practice. Within this framework, each retrieval method is treated as a distinct ``arm''. The system utilizes real-time user feedback to adapt to dynamic environments, by selecting the appropriate retrieval method based on input queries and the historical multi-objective performance of each arm. Extensive experiments conducted on two benchmark KGQA datasets demonstrate that our method significantly outperforms baseline methods in non-stationary settings while achieving state-of-the-art performance in stationary environments. Code and data are available at https://github.com/FUTUREEEEEE/Dynamic-RAG.git
MBA-RAG: a Bandit Approach for Adaptive Retrieval-Augmented Generation through Question Complexity
Dec 03, 2024



Retrieval Augmented Generation (RAG) has proven to be highly effective in boosting the generative performance of language model in knowledge-intensive tasks. However, existing RAG framework either indiscriminately perform retrieval or rely on rigid single-class classifiers to select retrieval methods, leading to inefficiencies and suboptimal performance across queries of varying complexity. To address these challenges, we propose a reinforcement learning-based framework that dynamically selects the most suitable retrieval strategy based on query complexity. % our solution Our approach leverages a multi-armed bandit algorithm, which treats each retrieval method as a distinct ``arm'' and adapts the selection process by balancing exploration and exploitation. Additionally, we introduce a dynamic reward function that balances accuracy and efficiency, penalizing methods that require more retrieval steps, even if they lead to a correct result. Our method achieves new state of the art results on multiple single-hop and multi-hop datasets while reducing retrieval costs. Our code are available at https://github.com/FUTUREEEEEE/MBA .
Out-of-distribution Detection in Medical Image Analysis: A survey
Apr 28, 2024
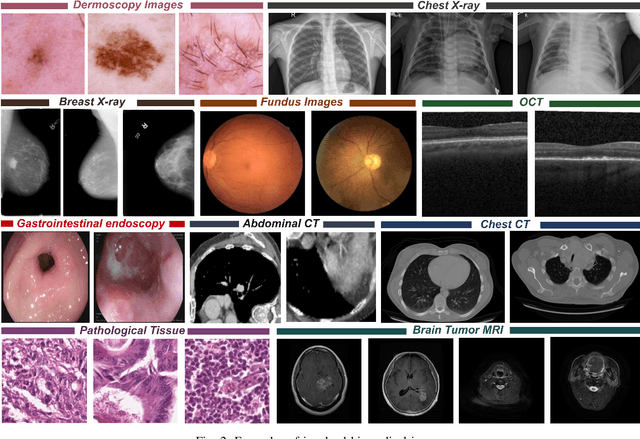
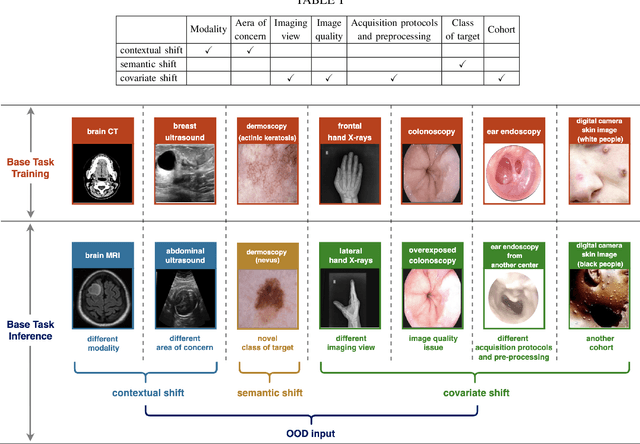

Computer-aided diagnostics has benefited from the development of deep learning-based computer vision techniques in these years. Traditional supervised deep learning methods assume that the test sample is drawn from the identical distribution as the training data. However, it is possible to encounter out-of-distribution samples in real-world clinical scenarios, which may cause silent failure in deep learning-based medical image analysis tasks. Recently, research has explored various out-of-distribution (OOD) detection situations and techniques to enable a trustworthy medical AI system. In this survey, we systematically review the recent advances in OOD detection in medical image analysis. We first explore several factors that may cause a distributional shift when using a deep-learning-based model in clinic scenarios, with three different types of distributional shift well defined on top of these factors. Then a framework is suggested to categorize and feature existing solutions, while the previous studies are reviewed based on the methodology taxonomy. Our discussion also includes evaluation protocols and metrics, as well as the challenge and a research direction lack of exploration.
Uncertainty Quantification on Graph Learning: A Survey
Apr 23, 2024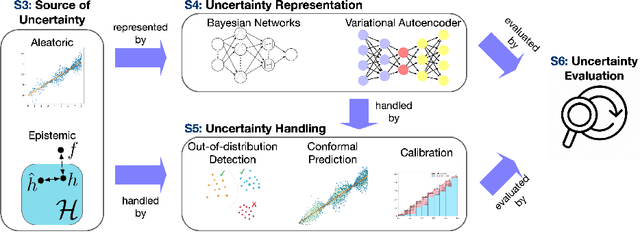
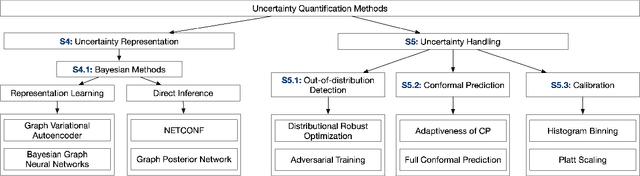
Graphical models, including Graph Neural Networks (GNNs) and Probabilistic Graphical Models (PGMs), have demonstrated their exceptional capabilities across numerous fields. These models necessitate effective uncertainty quantification to ensure reliable decision-making amid the challenges posed by model training discrepancies and unpredictable testing scenarios. This survey examines recent works that address uncertainty quantification within the model architectures, training, and inference of GNNs and PGMs. We aim to provide an overview of the current landscape of uncertainty in graphical models by organizing the recent methods into uncertainty representation and handling. By summarizing state-of-the-art methods, this survey seeks to deepen the understanding of uncertainty quantification in graphical models, thereby increasing their effectiveness and safety in critical applications.
Incorporating Domain Differential Equations into Graph Convolutional Networks to Lower Generalization Discrepancy
Apr 01, 2024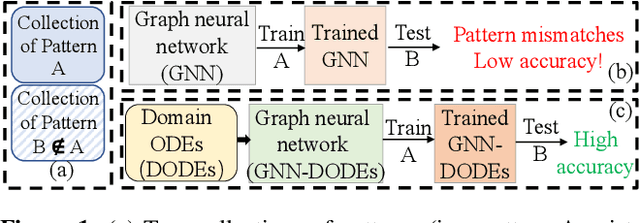

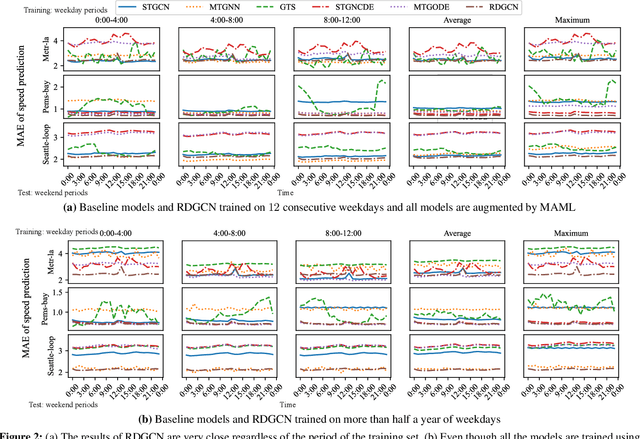

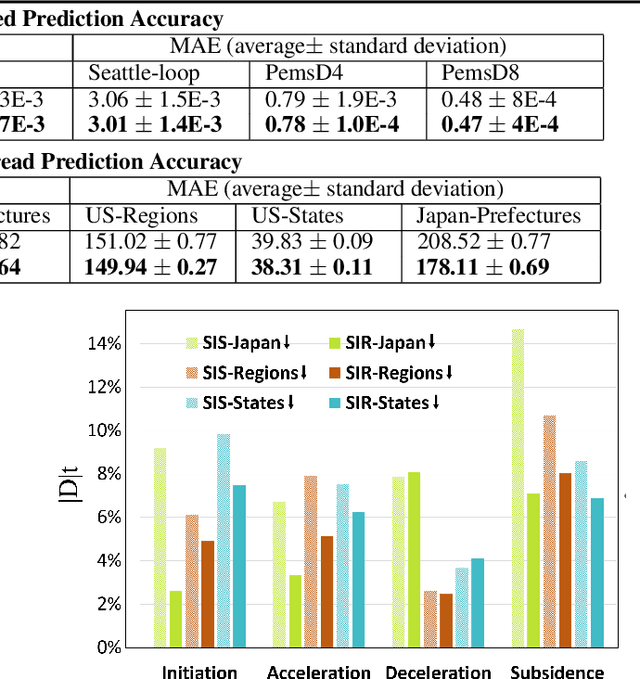
Ensuring both accuracy and robustness in time series prediction is critical to many applications, ranging from urban planning to pandemic management. With sufficient training data where all spatiotemporal patterns are well-represented, existing deep-learning models can make reasonably accurate predictions. However, existing methods fail when the training data are drawn from different circumstances (e.g., traffic patterns on regular days) compared to test data (e.g., traffic patterns after a natural disaster). Such challenges are usually classified under domain generalization. In this work, we show that one way to address this challenge in the context of spatiotemporal prediction is by incorporating domain differential equations into Graph Convolutional Networks (GCNs). We theoretically derive conditions where GCNs incorporating such domain differential equations are robust to mismatched training and testing data compared to baseline domain agnostic models. To support our theory, we propose two domain-differential-equation-informed networks called Reaction-Diffusion Graph Convolutional Network (RDGCN), which incorporates differential equations for traffic speed evolution, and Susceptible-Infectious-Recovered Graph Convolutional Network (SIRGCN), which incorporates a disease propagation model. Both RDGCN and SIRGCN are based on reliable and interpretable domain differential equations that allow the models to generalize to unseen patterns. We experimentally show that RDGCN and SIRGCN are more robust with mismatched testing data than the state-of-the-art deep learning methods.
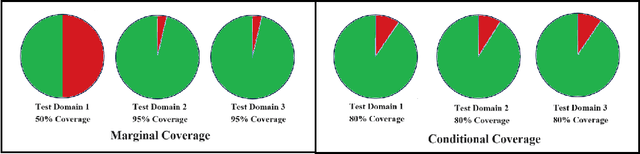
Robust Conformal Prediction under Distribution Shift via Physics-Informed Structural Causal Model
Mar 22, 2024

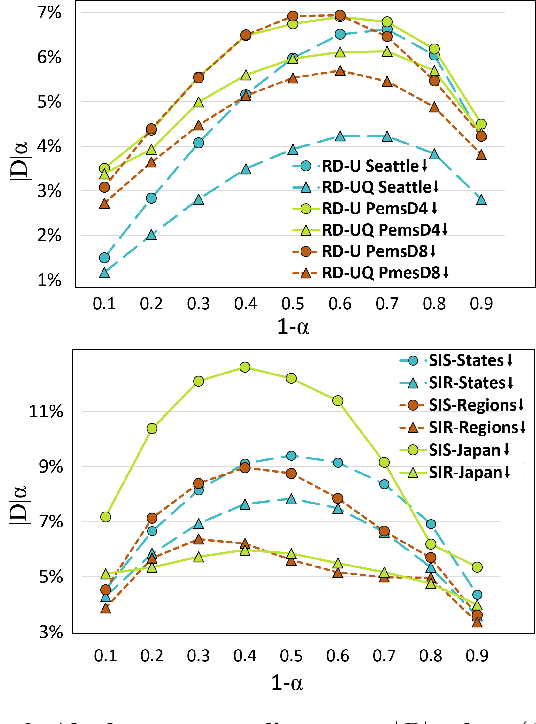
Uncertainty is critical to reliable decision-making with machine learning. Conformal prediction (CP) handles uncertainty by predicting a set on a test input, hoping the set to cover the true label with at least $(1-\alpha)$ confidence. This coverage can be guaranteed on test data even if the marginal distributions $P_X$ differ between calibration and test datasets. However, as it is common in practice, when the conditional distribution $P_{Y|X}$ is different on calibration and test data, the coverage is not guaranteed and it is essential to measure and minimize the coverage loss under distributional shift at \textit{all} possible confidence levels. To address these issues, we upper bound the coverage difference at all levels using the cumulative density functions of calibration and test conformal scores and Wasserstein distance. Inspired by the invariance of physics across data distributions, we propose a physics-informed structural causal model (PI-SCM) to reduce the upper bound. We validated that PI-SCM can improve coverage robustness along confidence level and test domain on a traffic speed prediction task and an epidemic spread task with multiple real-world datasets.