 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASAP: Advancing Medical Volumetric Representation Learning with Anatomy-aware Semantically-adaptive Pre-training
May 30, 2026Learning transferable and interpretable representations from medical volumetric scans remains challenging due to complex anatomical structures and weak, heterogeneous supervision provided by radiology reports. In this paper, we propose Anatomy-aware Semantically-Adaptive Pre-training (ASAP), a principled vision-language pre-training framework for fine-grained medical volumetric representation learning from large-scale chest CT scans and their corresponding radiology reports. ASAP integrates three key components: (1) an anatomy-aware knowledge injection module that incorporates organ-level structural priors via off-the-shelf segmentation tool to encourage anatomically coherent representations; (2) a semantically-adaptive selective alignment mechanism that dynamically associates sentence-level findings with localized volumetric regions; and (3) a semantically-adaptive fusion module for effective interaction between anatomically informed visual features and grounded textual cues under dual-modal masked modeling paradigm. Beyond methodological contributions, we establish a comprehensive benchmark for medical volumetric vision-language pre-training on chest CT, covering 15 datasets and 22 downstream tasks spanning abnormality classification, segmentation, disease prognosis prediction, report generation, vocabulary classification, cross-modal retrieval and visual question answering. This benchmark provides standardized evaluation protocols to systematically assess representation quality under diverse clinical settings and data regimes. Extensive experiments demonstrate that ASAP consistently achieves state-of-the-art performance across tasks and datasets, with particularly pronounced gains under limited supervision and distribution shift, validating its effectiveness in learning transferable and clinically meaningful volumetric representations.
Agentifying Patient Dynamics within LLMs through Interacting with Clinical World Model
May 14, 2026Sepsis management in the ICU requires sequential treatment decisions under rapidly evolving patient physiology. Although large language models (LLMs) encode broad clinical knowledge and can reason over guidelines, they are not inherently grounded in action-conditioned patient dynamics. We introduce SepsisAgent, a world model-augmented LLM agent for sepsis treatment recommendation. SepsisAgent uses a learned Clinical World Model to simulate patient responses under candidate fluid--vasopressor interventions, and follows a propose--simulate--refine workflow before committing to a prescription. We first show that world-model access alone yields inconsistent LLM decision performance, motivating agent-specific training. We then train SepsisAgent through a three-stage curriculum: patient-dynamics supervised fine-tuning, propose--simulate--refine behavior cloning, and world-model-based agentic reinforcement learning. On MIMIC-IV sepsis trajectories, SepsisAgent outperforms all traditional RL and LLM-based baselines in off-policy value while achieving the best safety profile under guideline adherence and unsafe-action metrics. Further analysis shows that repeated interaction with the Clinical World Model enables the agent to learn regularities in patient evolution, which remain useful even when simulator access is removed.
DiffVP: Differential Visual Semantic Prompting for LLM-Based CT Report Generation
Mar 18, 2026While large language models (LLMs) have advanced CT report generation, existing methods typically encode 3D volumes holistically, failing to distinguish informative cues from redundant anatomical background. Inspired by radiological cognitive subtraction, we propose Differential Visual Prompting (DiffVP), which conditions report generation on explicit, high-level semantic scan-to-reference differences rather than solely on absolute visual features. DiffVP employs a hierarchical difference extractor to capture complementary global and local semantic discrepancies into a shared latent space, along with a difference-to-prompt generator that transforms these signals into learnable visual prefix tokens for LLM conditioning. These difference prompts serve as structured conditioning signals that implicitly suppress invariant anatomy while amplifying diagnostically relevant visual evidence, thereby facilitating accurate report generation without explicit lesion localization. On two large-scale benchmarks, DiffVP consistently outperforms prior methods, improving the average BLEU-1-4 by +10.98 and +4.36, respectively, and further boosts clinical efficacy on RadGenome-ChestCT (F1 score 0.421). All codes will be released at https://github.com/ArielTYH/DiffVP/.
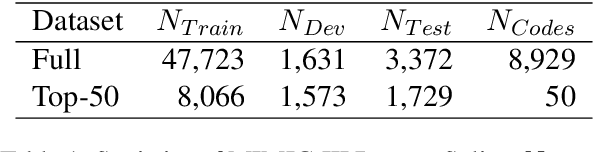
From Documents to Spans: Code-Centric Learning for LLM-based ICD Coding
Mar 16, 2026ICD coding is a critical yet challenging task in healthcare. Recently, LLM-based methods demonstrate stronger generalization than discriminative methods in ICD coding. However, fine-tuning LLMs for ICD coding faces three major challenges. First, existing public ICD coding datasets provide limited coverage of the ICD code space, restricting a model's ability to generalize to unseen codes. Second, naive fine-tuning diminishes the interpretability of LLMs, as few public datasets contain explicit supporting evidence for assigned codes. Third, ICD coding typically involves long clinical documents, making fine-tuning LLMs computationally expensive. To address these issues, we propose Code-Centric Learning, a training framework that shifts supervision from full clinical documents to scalable, short evidence spans. The key idea of this framework is that span-level learning improves LLMs' ability to perform document-level ICD coding. Our proposed framework consists of a mixed training strategy and code-centric data expansion, which substantially reduces training cost, improves accuracy on unseen ICD codes and preserves interpretability. Under the same LLM backbone, our method substantially outperforms strong baselines. Notably, our method enables small-scale LLMs to achieve performance comparable to much larger proprietary models, demonstrating its effectiveness and potential for fully automated ICD coding.
MicroVerse: A Preliminary Exploration Toward a Micro-World Simulation
Feb 28, 2026Recent advances in video generation have opened new avenues for macroscopic simulation of complex dynamic systems, but their application to microscopic phenomena remains largely unexplored. Microscale simulation holds great promise for biomedical applications such as drug discovery, organ-on-chip systems, and disease mechanism studies, while also showing potential in education and interactive visualization. In this work, we introduce MicroWorldBench, a multi-level rubric-based benchmark for microscale simulation tasks. MicroWorldBench enables systematic, rubric-based evaluation through 459 unique expert-annotated criteria spanning multiple microscale simulation task (e.g., organ-level processes, cellular dynamics, and subcellular molecular interactions) and evaluation dimensions (e.g., scientific fidelity, visual quality, instruction following). MicroWorldBench reveals that current SOTA video generation models fail in microscale simulation, showing violations of physical laws, temporal inconsistency, and misalignment with expert criteria. To address these limitations, we construct MicroSim-10K, a high-quality, expert-verified simulation dataset. Leveraging this dataset, we train MicroVerse, a video generation model tailored for microscale simulation. MicroVerse can accurately reproduce complex microscale mechanism. Our work first introduce the concept of Micro-World Simulation and present a proof of concept, paving the way for applications in biology, education, and scientific visualization. Our work demonstrates the potential of educational microscale simulations of biological mechanisms. Our data and code are publicly available at https://github.com/FreedomIntelligence/MicroVerse
Med3D-R1: Incentivizing Clinical Reasoning in 3D Medical Vision-Language Models for Abnormality Diagnosis
Feb 01, 2026Developing 3D vision-language models with robust clinical reasoning remains a challenge due to the inherent complexity of volumetric medical imaging, the tendency of models to overfit superficial report patterns, and the lack of interpretability-aware reward designs. In this paper, we propose Med3D-R1, a reinforcement learning framework with a two-stage training process: Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). During SFT stage, we introduce a residual alignment mechanism to bridge the gap between high-dimensional 3D features and textual embeddings, and an abnormality re-weighting strategy to emphasize clinically informative tokens and reduce structural bias in reports. In RL stage, we redesign the consistency reward to explicitly promote coherent, step-by-step diagnostic reasoning. We evaluate our method on medical multiple-choice visual question answering using two 3D diagnostic benchmarks, CT-RATE and RAD-ChestCT, where our model attains state-of-the-art accuracies of 41.92\% on CT-RATE and 44.99\% on RAD-ChestCT. These results indicate improved abnormality diagnosis and clinical reasoning and outperform prior methods on both benchmarks. Overall, our approach holds promise for enhancing real-world diagnostic workflows by enabling more reliable and transparent 3D medical vision-language systems.
U-Bench: A Comprehensive Understanding of U-Net through 100-Variant Benchmarking
Oct 08, 2025


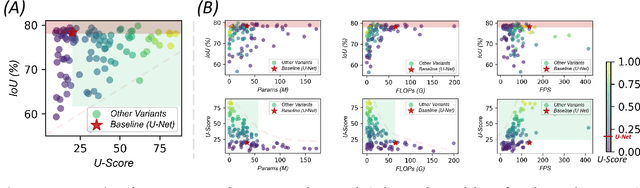
Over the past decade, U-Net has been the dominant architecture in medical image segmentation, leading to the development of thousands of U-shaped variants. Despite its widespread adoption, there is still no comprehensive benchmark to systematically evaluate their performance and utility, largely because of insufficient statistical validation and limited consideration of efficiency and generalization across diverse datasets. To bridge this gap, we present U-Bench, the first large-scale, statistically rigorous benchmark that evaluates 100 U-Net variants across 28 datasets and 10 imaging modalities. Our contributions are threefold: (1) Comprehensive Evaluation: U-Bench evaluates models along three key dimensions: statistical robustness, zero-shot generalization, and computational efficiency. We introduce a novel metric, U-Score, which jointly captures the performance-efficiency trade-off, offering a deployment-oriented perspective on model progress. (2) Systematic Analysis and Model Selection Guidance: We summarize key findings from the large-scale evaluation and systematically analyze the impact of dataset characteristics and architectural paradigms on model performance. Based on these insights, we propose a model advisor agent to guide researchers in selecting the most suitable models for specific datasets and tasks. (3) Public Availability: We provide all code, models, protocols, and weights, enabling the community to reproduce our results and extend the benchmark with future methods. In summary, U-Bench not only exposes gaps in previous evaluations but also establishes a foundation for fair, reproducible, and practically relevant benchmarking in the next decade of U-Net-based segmentation models. The project can be accessed at: https://fenghetan9.github.io/ubench. Code is available at: https://github.com/FengheTan9/U-Bench.
SimCroP: Radiograph Representation Learning with Similarity-driven Cross-granularity Pre-training
Sep 10, 2025Medical vision-language pre-training shows great potential in learning representative features from massive paired radiographs and reports. However, in computed tomography (CT) scans, the distribution of lesions which contain intricate structures is characterized by spatial sparsity. Besides, the complex and implicit relationships between different pathological descriptions in each sentence of the report and their corresponding sub-regions in radiographs pose additional challenges. In this paper, we propose a Similarity-Driven Cross-Granularity Pre-training (SimCroP) framework on chest CTs, which combines similarity-driven alignment and cross-granularity fusion to improve radiograph interpretation. We first leverage multi-modal masked modeling to optimize the encoder for understanding precise low-level semantics from radiographs. Then, similarity-driven alignment is designed to pre-train the encoder to adaptively select and align the correct patches corresponding to each sentence in reports. The cross-granularity fusion module integrates multimodal information across instance level and word-patch level, which helps the model better capture key pathology structures in sparse radiographs, resulting in improved performance for multi-scale downstream tasks. SimCroP is pre-trained on a large-scale paired CT-reports dataset and validated on image classification and segmentation tasks across five public datasets. Experimental results demonstrate that SimCroP outperforms both cutting-edge medical self-supervised learning methods and medical vision-language pre-training methods. Codes and models are available at https://github.com/ToniChopp/SimCroP.
ShizhenGPT: Towards Multimodal LLMs for Traditional Chinese Medicine
Aug 20, 2025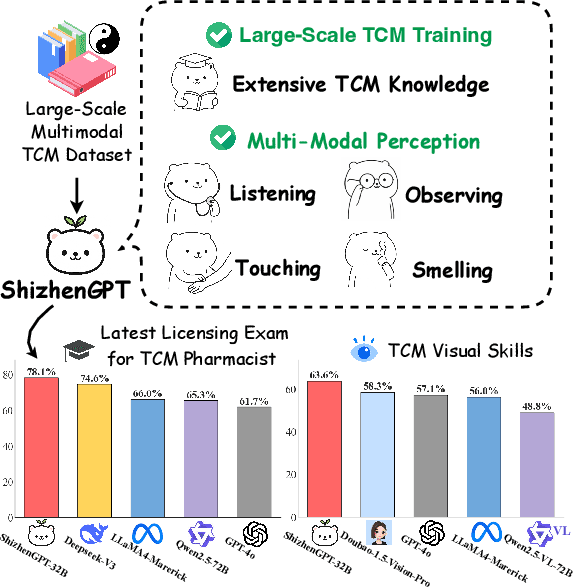
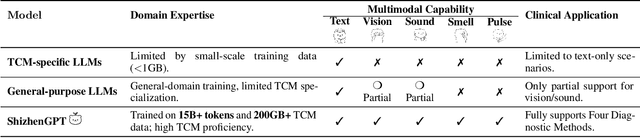
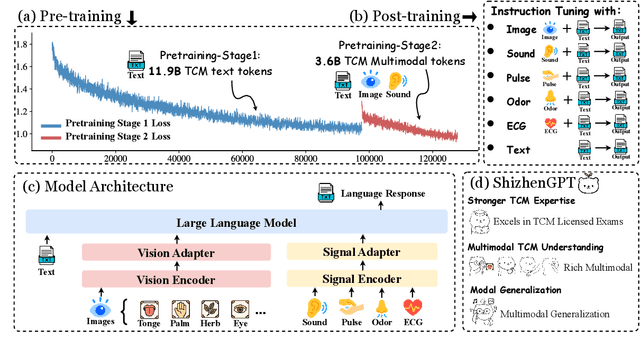
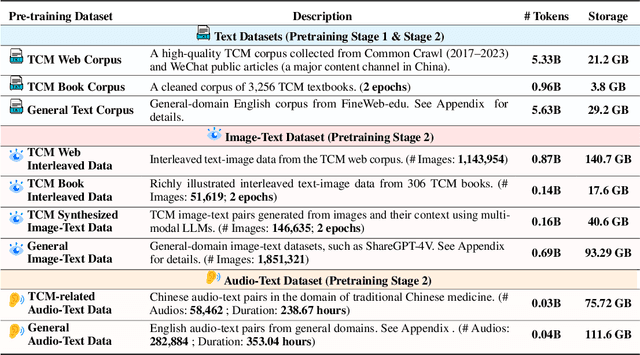
Despite the success of large language models (LLMs) in various domains, their potential in Traditional Chinese Medicine (TCM) remains largely underexplored due to two critical barriers: (1) the scarcity of high-quality TCM data and (2) the inherently multimodal nature of TCM diagnostics, which involve looking, listening, smelling, and pulse-taking. These sensory-rich modalities are beyond the scope of conventional LLMs. To address these challenges, we present ShizhenGPT, the first multimodal LLM tailored for TCM. To overcome data scarcity, we curate the largest TCM dataset to date, comprising 100GB+ of text and 200GB+ of multimodal data, including 1.2M images, 200 hours of audio, and physiological signals. ShizhenGPT is pretrained and instruction-tuned to achieve deep TCM knowledge and multimodal reasoning. For evaluation, we collect recent national TCM qualification exams and build a visual benchmark for Medicinal Recognition and Visual Diagnosis. Experiments demonstrate that ShizhenGPT outperforms comparable-scale LLMs and competes with larger proprietary models. Moreover, it leads in TCM visual understanding among existing multimodal LLMs and demonstrates unified perception across modalities like sound, pulse, smell, and vision, paving the way toward holistic multimodal perception and diagnosis in TCM. Datasets, models, and code are publicly available. We hope this work will inspire further exploration in this field.
A General Knowledge Injection Framework for ICD Coding
May 24, 2025
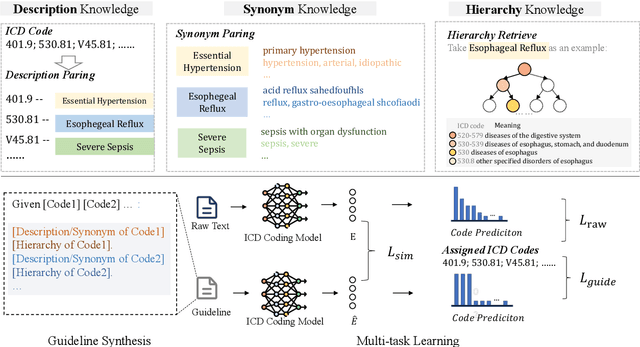
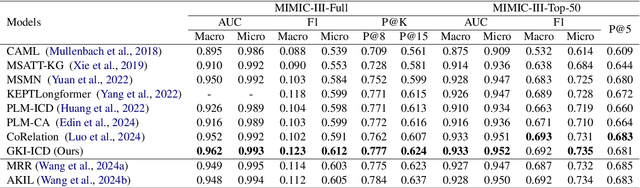
ICD Coding aims to assign a wide range of medical codes to a medical text document, which is a popular and challenging task in the healthcare domain. To alleviate the problems of long-tail distribution and the lack of annotations of code-specific evidence, many previous works have proposed incorporating code knowledge to improve coding performance. However, existing methods often focus on a single type of knowledge and design specialized modules that are complex and incompatible with each other, thereby limiting their scalability and effectiveness. To address this issue, we propose GKI-ICD, a novel, general knowledge injection framework that integrates three key types of knowledge, namely ICD Description, ICD Synonym, and ICD Hierarchy, without specialized design of additional modules. The comprehensive utilization of the above knowledge, which exhibits both differences and complementarity, can effectively enhance the ICD coding performance. Extensive experiments on existing popular ICD coding benchmarks demonstrate the effectiveness of GKI-ICD, which achieves the state-of-the-art performance on most evaluation metrics. Code is available at https://github.com/xuzhang0112/GKI-ICD.