 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAPO: Tool-Aware Policy Optimization via Credit Transfer for Multimodal Search Agents
Jun 04, 2026We identify and formally characterize credit misassignment as a systematic failure mode of GRPO in tool-augmented multimodal search agents: its uniform broadcast of trajectory-level advantages to all tokens causes valuable tool-use steps in failing trajectories to be penalized no differently from valueless ones. We further empirically quantify the scale of this phenomenon. Over half of failing trajectories and failing tool-use actions exhibit correctable credit misassignment, demonstrating that the wasted training signal is both substantial and structurally exploitable. Building on this insight, we propose Tool-Aware Policy Optimization (TAPO), which exploits the parameter-determinism property of information-acquisition tools: similar call parameters define equivalent information-acquisition actions and should therefore share comparable action credit. TAPO constructs counterfactual witnesses within the current training batch and compensates misassigned negative credit via confidence-gated conservative advantage correction. It requires no additional annotation, models, or sampling, and introduces negligible computational overhead. Across multiple multimodal search benchmarks, TAPO delivers consistent, plug-and-play improvements over strong baselines for three mainstream RL algorithms (GRPO, GSPO, and SAPO). Our code and models will be publicly released upon acceptance.
ASAP: Advancing Medical Volumetric Representation Learning with Anatomy-aware Semantically-adaptive Pre-training
May 30, 2026Learning transferable and interpretable representations from medical volumetric scans remains challenging due to complex anatomical structures and weak, heterogeneous supervision provided by radiology reports. In this paper, we propose Anatomy-aware Semantically-Adaptive Pre-training (ASAP), a principled vision-language pre-training framework for fine-grained medical volumetric representation learning from large-scale chest CT scans and their corresponding radiology reports. ASAP integrates three key components: (1) an anatomy-aware knowledge injection module that incorporates organ-level structural priors via off-the-shelf segmentation tool to encourage anatomically coherent representations; (2) a semantically-adaptive selective alignment mechanism that dynamically associates sentence-level findings with localized volumetric regions; and (3) a semantically-adaptive fusion module for effective interaction between anatomically informed visual features and grounded textual cues under dual-modal masked modeling paradigm. Beyond methodological contributions, we establish a comprehensive benchmark for medical volumetric vision-language pre-training on chest CT, covering 15 datasets and 22 downstream tasks spanning abnormality classification, segmentation, disease prognosis prediction, report generation, vocabulary classification, cross-modal retrieval and visual question answering. This benchmark provides standardized evaluation protocols to systematically assess representation quality under diverse clinical settings and data regimes. Extensive experiments demonstrate that ASAP consistently achieves state-of-the-art performance across tasks and datasets, with particularly pronounced gains under limited supervision and distribution shift, validating its effectiveness in learning transferable and clinically meaningful volumetric representations.
Concept-to-Pixel: Prompt-Free Universal Medical Image Segmentation
Mar 18, 2026Universal medical image segmentation seeks to use a single foundational model to handle diverse tasks across multiple imaging modalities. However, existing approaches often rely heavily on manual visual prompts or retrieved reference images, which limits their automation and robustness. In addition, naive joint training across modalities often fails to address large domain shifts. To address these limitations, we propose Concept-to-Pixel (C2P), a novel prompt-free universal segmentation framework. C2P explicitly separates anatomical knowledge into two components: Geometric and Semantic representations. It leverages Multimodal Large Language Models (MLLMs) to distill abstract, high-level medical concepts into learnable Semantic Tokens and introduces explicitly supervised Geometric Tokens to enforce universal physical and structural constraints. These disentangled tokens interact deeply with image features to generate input-specific dynamic kernels for precise mask prediction. Furthermore, we introduce a Geometry-Aware Inference Consensus mechanism, which utilizes the model's predicted geometric constraints to assess prediction reliability and suppress outliers. Extensive experiments and analysis on a unified benchmark comprising eight diverse datasets across seven modalities demonstrate the significant superiority of our jointly trained approach, compared to universe- or single-model approaches. Remarkably, our unified model demonstrates strong generalization, achieving impressive results not only on zero-shot tasks involving unseen cases but also in cross-modal transfers across similar tasks. Code is available at: https://github.com/Yundi218/Concept-to-Pixel
UCAD: Uncertainty-guided Contour-aware Displacement for semi-supervised medical image segmentation
Jan 24, 2026Existing displacement strategies in semi-supervised segmentation only operate on rectangular regions, ignoring anatomical structures and resulting in boundary distortions and semantic inconsistency. To address these issues, we propose UCAD, an Uncertainty-Guided Contour-Aware Displacement framework for semi-supervised medical image segmentation that preserves contour-aware semantics while enhancing consistency learning. Our UCAD leverages superpixels to generate anatomically coherent regions aligned with anatomy boundaries, and an uncertainty-guided selection mechanism to selectively displace challenging regions for better consistency learning. We further propose a dynamic uncertainty-weighted consistency loss, which adaptively stabilizes training and effectively regularizes the model on unlabeled regions. Extensive experiments demonstrate that UCAD consistently outperforms state-of-the-art semi-supervised segmentation methods, achieving superior segmentation accuracy under limited annotation. The code is available at:https://github.com/dcb937/UCAD.
Equivariant Sampling for Improving Diffusion Model-based Image Restoration
Nov 13, 2025

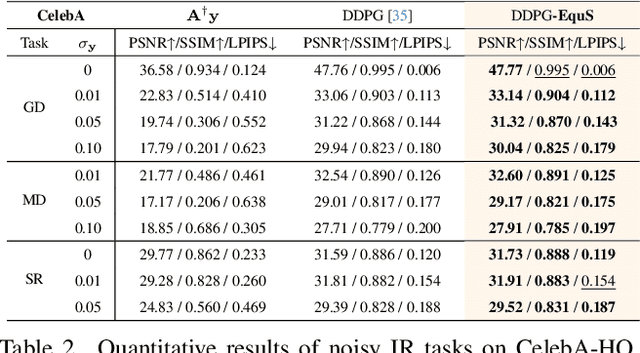

Recent advances in generative models, especially diffusion models, have significantly improved image restoration (IR) performance. However, existing problem-agnostic diffusion model-based image restoration (DMIR) methods face challenges in fully leveraging diffusion priors, resulting in suboptimal performance. In this paper, we address the limitations of current problem-agnostic DMIR methods by analyzing their sampling process and providing effective solutions. We introduce EquS, a DMIR method that imposes equivariant information through dual sampling trajectories. To further boost EquS, we propose the Timestep-Aware Schedule (TAS) and introduce EquS$^+$. TAS prioritizes deterministic steps to enhance certainty and sampling efficiency. Extensive experiments on benchmarks demonstrate that our method is compatible with previous problem-agnostic DMIR methods and significantly boosts their performance without increasing computational costs. Our code is available at https://github.com/FouierL/EquS.
U-Bench: A Comprehensive Understanding of U-Net through 100-Variant Benchmarking
Oct 08, 2025


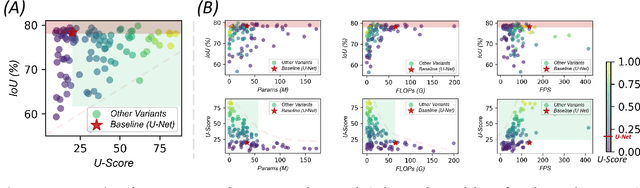
Over the past decade, U-Net has been the dominant architecture in medical image segmentation, leading to the development of thousands of U-shaped variants. Despite its widespread adoption, there is still no comprehensive benchmark to systematically evaluate their performance and utility, largely because of insufficient statistical validation and limited consideration of efficiency and generalization across diverse datasets. To bridge this gap, we present U-Bench, the first large-scale, statistically rigorous benchmark that evaluates 100 U-Net variants across 28 datasets and 10 imaging modalities. Our contributions are threefold: (1) Comprehensive Evaluation: U-Bench evaluates models along three key dimensions: statistical robustness, zero-shot generalization, and computational efficiency. We introduce a novel metric, U-Score, which jointly captures the performance-efficiency trade-off, offering a deployment-oriented perspective on model progress. (2) Systematic Analysis and Model Selection Guidance: We summarize key findings from the large-scale evaluation and systematically analyze the impact of dataset characteristics and architectural paradigms on model performance. Based on these insights, we propose a model advisor agent to guide researchers in selecting the most suitable models for specific datasets and tasks. (3) Public Availability: We provide all code, models, protocols, and weights, enabling the community to reproduce our results and extend the benchmark with future methods. In summary, U-Bench not only exposes gaps in previous evaluations but also establishes a foundation for fair, reproducible, and practically relevant benchmarking in the next decade of U-Net-based segmentation models. The project can be accessed at: https://fenghetan9.github.io/ubench. Code is available at: https://github.com/FengheTan9/U-Bench.
SimCroP: Radiograph Representation Learning with Similarity-driven Cross-granularity Pre-training
Sep 10, 2025Medical vision-language pre-training shows great potential in learning representative features from massive paired radiographs and reports. However, in computed tomography (CT) scans, the distribution of lesions which contain intricate structures is characterized by spatial sparsity. Besides, the complex and implicit relationships between different pathological descriptions in each sentence of the report and their corresponding sub-regions in radiographs pose additional challenges. In this paper, we propose a Similarity-Driven Cross-Granularity Pre-training (SimCroP) framework on chest CTs, which combines similarity-driven alignment and cross-granularity fusion to improve radiograph interpretation. We first leverage multi-modal masked modeling to optimize the encoder for understanding precise low-level semantics from radiographs. Then, similarity-driven alignment is designed to pre-train the encoder to adaptively select and align the correct patches corresponding to each sentence in reports. The cross-granularity fusion module integrates multimodal information across instance level and word-patch level, which helps the model better capture key pathology structures in sparse radiographs, resulting in improved performance for multi-scale downstream tasks. SimCroP is pre-trained on a large-scale paired CT-reports dataset and validated on image classification and segmentation tasks across five public datasets. Experimental results demonstrate that SimCroP outperforms both cutting-edge medical self-supervised learning methods and medical vision-language pre-training methods. Codes and models are available at https://github.com/ToniChopp/SimCroP.
U-RWKV: Lightweight medical image segmentation with direction-adaptive RWKV
Jul 15, 2025Achieving equity in healthcare accessibility requires lightweight yet high-performance solutions for medical image segmentation, particularly in resource-limited settings. Existing methods like U-Net and its variants often suffer from limited global Effective Receptive Fields (ERFs), hindering their ability to capture long-range dependencies. To address this, we propose U-RWKV, a novel framework leveraging the Recurrent Weighted Key-Value(RWKV) architecture, which achieves efficient long-range modeling at O(N) computational cost. The framework introduces two key innovations: the Direction-Adaptive RWKV Module(DARM) and the Stage-Adaptive Squeeze-and-Excitation Module(SASE). DARM employs Dual-RWKV and QuadScan mechanisms to aggregate contextual cues across images, mitigating directional bias while preserving global context and maintaining high computational efficiency. SASE dynamically adapts its architecture to different feature extraction stages, balancing high-resolution detail preservation and semantic relationship capture. Experiments demonstrate that U-RWKV achieves state-of-the-art segmentation performance with high computational efficiency, offering a practical solution for democratizing advanced medical imaging technologies in resource-constrained environments. The code is available at https://github.com/hbyecoding/U-RWKV.
AA-CLIP: Enhancing Zero-shot Anomaly Detection via Anomaly-Aware CLIP
Mar 09, 2025Anomaly detection (AD) identifies outliers for applications like defect and lesion detection. While CLIP shows promise for zero-shot AD tasks due to its strong generalization capabilities, its inherent Anomaly-Unawareness leads to limited discrimination between normal and abnormal features. To address this problem, we propose Anomaly-Aware CLIP (AA-CLIP), which enhances CLIP's anomaly discrimination ability in both text and visual spaces while preserving its generalization capability. AA-CLIP is achieved through a straightforward yet effective two-stage approach: it first creates anomaly-aware text anchors to differentiate normal and abnormal semantics clearly, then aligns patch-level visual features with these anchors for precise anomaly localization. This two-stage strategy, with the help of residual adapters, gradually adapts CLIP in a controlled manner, achieving effective AD while maintaining CLIP's class knowledge. Extensive experiments validate AA-CLIP as a resource-efficient solution for zero-shot AD tasks, achieving state-of-the-art results in industrial and medical applications. The code is available at https://github.com/Mwxinnn/AA-CLIP.
* 8 pages, 7 figures
Hi-End-MAE: Hierarchical encoder-driven masked autoencoders are stronger vision learners for medical image segmentation
Feb 12, 2025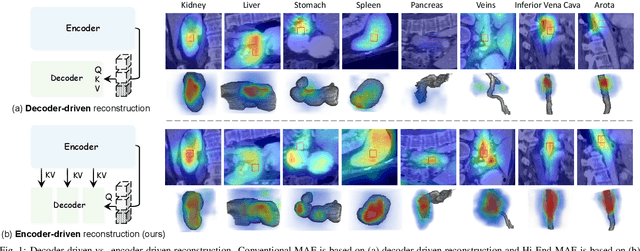
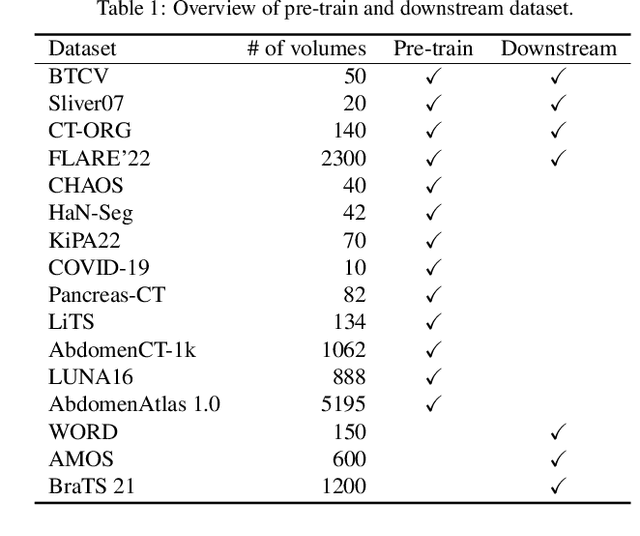
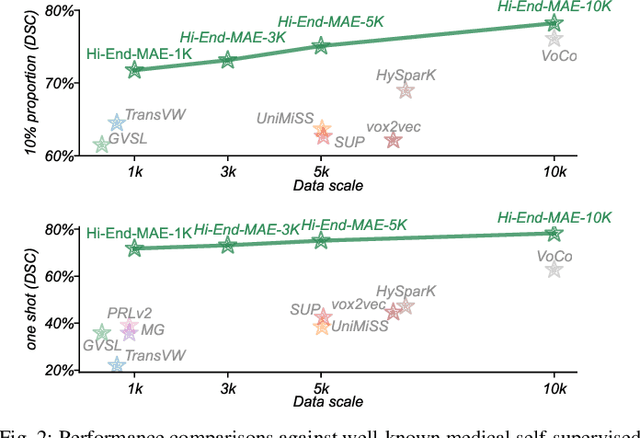
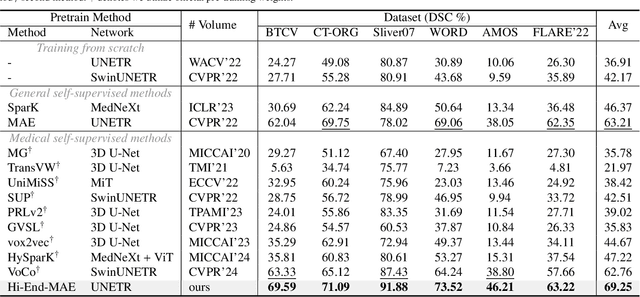
Medical image segmentation remains a formidable challenge due to the label scarcity. Pre-training Vision Transformer (ViT) through masked image modeling (MIM) on large-scale unlabeled medical datasets presents a promising solution, providing both computational efficiency and model generalization for various downstream tasks. However, current ViT-based MIM pre-training frameworks predominantly emphasize local aggregation representations in output layers and fail to exploit the rich representations across different ViT layers that better capture fine-grained semantic information needed for more precise medical downstream tasks. To fill the above gap, we hereby present Hierarchical Encoder-driven MAE (Hi-End-MAE), a simple yet effective ViT-based pre-training solution, which centers on two key innovations: (1) Encoder-driven reconstruction, which encourages the encoder to learn more informative features to guide the reconstruction of masked patches; and (2) Hierarchical dense decoding, which implements a hierarchical decoding structure to capture rich representations across different layers. We pre-train Hi-End-MAE on a large-scale dataset of 10K CT scans and evaluated its performance across seven public medical image segmentation benchmarks. Extensive experiments demonstrate that Hi-End-MAE achieves superior transfer learning capabilities across various downstream tasks, revealing the potential of ViT in medical imaging applications. The code is available at: https://github.com/FengheTan9/Hi-End-MAE