 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAV Trajectory Optimization via Improved Noisy Deep Q-Network
Feb 05, 2026This paper proposes an Improved Noisy Deep Q-Network (Noisy DQN) to enhance the exploration and stability of Unmanned Aerial Vehicle (UAV) when applying deep reinforcement learning in simulated environments. This method enhances the exploration ability by combining the residual NoisyLinear layer with an adaptive noise scheduling mechanism, while improving training stability through smooth loss and soft target network updates. Experiments show that the proposed model achieves faster convergence and up to $+40$ higher rewards compared to standard DQN and quickly reach to the minimum number of steps required for the task 28 in the 15 * 15 grid navigation environment set up. The results show that our comprehensive improvements to the network structure of NoisyNet, exploration control, and training stability contribute to enhancing the efficiency and reliability of deep Q-learning.
MambaMIM: Pre-training Mamba with State Space Token-interpolation
Aug 15, 2024Generative self-supervised learning demonstrates outstanding representation learning capabilities in both Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). However, there are currently no generative pre-training methods related to selective state space models (Mamba) that can handle long-range dependencies effectively. To address this challenge, we introduce a generative self-supervised learning method for Mamba (MambaMIM) based on Selective Structure State Space Sequence Token-interpolation (S6T), a general-purpose pre-training method for arbitrary Mamba architectures. Our method, MambaMIM, incorporates a bottom-up 3D hybrid masking strategy in the encoder to maintain masking consistency across different architectures. Additionally, S6T is employed to learn causal relationships between the masked sequence in the state space. MambaMIM can be used on any single or hybrid Mamba architectures to enhance the Mamba long-range representation capability. Extensive downstream experiments reveal the feasibility and advancement of using Mamba for pre-training medical image tasks. The code is available at: https://github.com/FengheTan9/MambaMIM
A Novel Image Descriptor with Aggregated Semantic Skeleton Representation for Long-term Visual Place Recognition
Feb 08, 2022


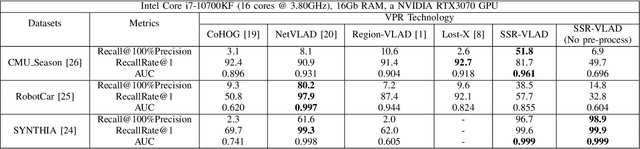
In a Simultaneous Localization and Mapping (SLAM) system, a loop-closure can eliminate accumulated errors, which is accomplished by Visual Place Recognition (VPR), a task that retrieves the current scene from a set of pre-stored sequential images through matching specific scene-descriptors. In urban scenes, the appearance variation caused by seasons and illumination has brought great challenges to the robustness of scene descriptors. Semantic segmentation images can not only deliver the shape information of objects but also their categories and spatial relations that will not be affected by the appearance variation of the scene. Innovated by the Vector of Locally Aggregated Descriptor (VLAD), in this paper, we propose a novel image descriptor with aggregated semantic skeleton representation (SSR), dubbed SSR-VLAD, for the VPR under drastic appearance-variation of environments. The SSR-VLAD of one image aggregates the semantic skeleton features of each category and encodes the spatial-temporal distribution information of the image semantic information. We conduct a series of experiments on three public datasets of challenging urban scenes. Compared with four state-of-the-art VPR methods- CoHOG, NetVLAD, LOST-X, and Region-VLAD, VPR by matching SSR-VLAD outperforms those methods and maintains competitive real-time performance at the same time.