 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Documents to Spans: Code-Centric Learning for LLM-based ICD Coding
Mar 16, 2026ICD coding is a critical yet challenging task in healthcare. Recently, LLM-based methods demonstrate stronger generalization than discriminative methods in ICD coding. However, fine-tuning LLMs for ICD coding faces three major challenges. First, existing public ICD coding datasets provide limited coverage of the ICD code space, restricting a model's ability to generalize to unseen codes. Second, naive fine-tuning diminishes the interpretability of LLMs, as few public datasets contain explicit supporting evidence for assigned codes. Third, ICD coding typically involves long clinical documents, making fine-tuning LLMs computationally expensive. To address these issues, we propose Code-Centric Learning, a training framework that shifts supervision from full clinical documents to scalable, short evidence spans. The key idea of this framework is that span-level learning improves LLMs' ability to perform document-level ICD coding. Our proposed framework consists of a mixed training strategy and code-centric data expansion, which substantially reduces training cost, improves accuracy on unseen ICD codes and preserves interpretability. Under the same LLM backbone, our method substantially outperforms strong baselines. Notably, our method enables small-scale LLMs to achieve performance comparable to much larger proprietary models, demonstrating its effectiveness and potential for fully automated ICD coding.
QCAgent: An agentic framework for quality-controllable pathology report generation from whole slide image
Mar 02, 2026Recent methods for pathology report generation from whole-slide image (WSI) are capable of producing slide-level diagnostic descriptions but fail to ground fine-grained statements in localized visual evidence. Furthermore, they lack control over which diagnostic details to include and how to verify them. Inspired by emerging agentic analysis paradigms and the diagnostic workflow of pathologists,who selectively examine multiple fields of view, we propose QCAgent, an agentic framework for quality-controllable WSI report generation. The core innovations of this framework are as follows: (i) it incorporates a customized critique mechanism guided by a user-defined checklist specifying required diagnostic details and constraints; (ii) it re-identifies informative regions in the WSI based on the critique feedback and text-patch semantic retrieval, a process that iteratively enriches and reconciles the report. Experiments demonstrate that by making report requirements explicitly prompt-defined, constraint-aware, and verifiable through evidence-grounded refinement, QCAgent enables controllable generation of clinically meaningful and high-coverage pathology reports from WSI.
Towards Personalized Multi-Modal MRI Synthesis across Heterogeneous Datasets
Feb 23, 2026Synthesizing missing modalities in multi-modal magnetic resonance imaging (MRI) is vital for ensuring diagnostic completeness, particularly when full acquisitions are infeasible due to time constraints, motion artifacts, and patient tolerance. Recent unified synthesis models have enabled flexible synthesis tasks by accommodating various input-output configurations. However, their training and evaluation are typically restricted to a single dataset, limiting their generalizability across diverse clinical datasets and impeding practical deployment. To address this limitation, we propose PMM-Synth, a personalized MRI synthesis framework that not only supports various synthesis tasks but also generalizes effectively across heterogeneous datasets. PMM-Synth is jointly trained on multiple multi-modal MRI datasets that differ in modality coverage, disease types, and intensity distributions. It achieves cross-dataset generalization through three core innovations: a Personalized Feature Modulation module that dynamically adapts feature representations based on dataset identifier to mitigate the impact of distributional shifts; a Modality-Consistent Batch Scheduler that facilitates stable and efficient batch training under inconsistent modality conditions; and a selective supervision loss to ensure effective learning when ground truth modalities are partially missing. Evaluated on four clinical multi-modal MRI datasets, PMM-Synth consistently outperforms state-of-the-art methods in both one-to-one and many-to-one synthesis tasks, achieving superior PSNR and SSIM scores. Qualitative results further demonstrate improved preservation of anatomical structures and pathological details. Additionally, downstream tumor segmentation and radiological reporting studies suggest that PMM-Synth holds potential for supporting reliable diagnosis under real-world modality-missing scenarios.
CausalSpatial: A Benchmark for Object-Centric Causal Spatial Reasoning
Jan 19, 2026Humans can look at a static scene and instantly predict what happens next -- will moving this object cause a collision? We call this ability Causal Spatial Reasoning. However, current multimodal large language models (MLLMs) cannot do this, as they remain largely restricted to static spatial perception, struggling to answer "what-if" questions in a 3D scene. We introduce CausalSpatial, a diagnostic benchmark evaluating whether models can anticipate consequences of object motions across four tasks: Collision, Compatibility, Occlusion, and Trajectory. Results expose a severe gap: humans score 84% while GPT-5 achieves only 54%. Why do MLLMs fail? Our analysis uncovers a fundamental deficiency: models over-rely on textual chain-of-thought reasoning that drifts from visual evidence, producing fluent but spatially ungrounded hallucinations. To address this, we propose the Causal Object World model (COW), a framework that externalizes the simulation process by generating videos of hypothetical dynamics. With explicit visual cues of causality, COW enables models to ground their reasoning in physical reality rather than linguistic priors. We make the dataset and code publicly available here: https://github.com/CausalSpatial/CausalSpatial
Equivariant Sampling for Improving Diffusion Model-based Image Restoration
Nov 13, 2025

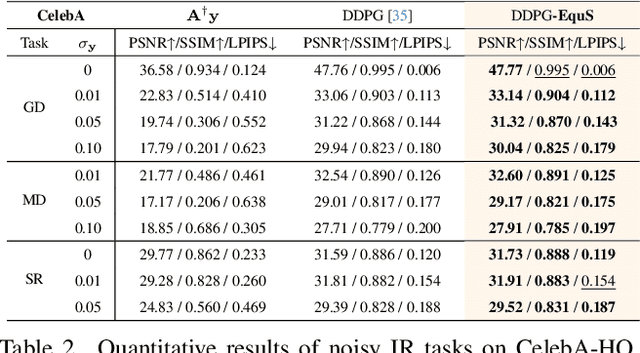

Recent advances in generative models, especially diffusion models, have significantly improved image restoration (IR) performance. However, existing problem-agnostic diffusion model-based image restoration (DMIR) methods face challenges in fully leveraging diffusion priors, resulting in suboptimal performance. In this paper, we address the limitations of current problem-agnostic DMIR methods by analyzing their sampling process and providing effective solutions. We introduce EquS, a DMIR method that imposes equivariant information through dual sampling trajectories. To further boost EquS, we propose the Timestep-Aware Schedule (TAS) and introduce EquS$^+$. TAS prioritizes deterministic steps to enhance certainty and sampling efficiency. Extensive experiments on benchmarks demonstrate that our method is compatible with previous problem-agnostic DMIR methods and significantly boosts their performance without increasing computational costs. Our code is available at https://github.com/FouierL/EquS.
RadGS-Reg: Registering Spine CT with Biplanar X-rays via Joint 3D Radiative Gaussians Reconstruction and 3D/3D Registration
Aug 28, 2025Computed Tomography (CT)/X-ray registration in image-guided navigation remains challenging because of its stringent requirements for high accuracy and real-time performance. Traditional "render and compare" methods, relying on iterative projection and comparison, suffer from spatial information loss and domain gap. 3D reconstruction from biplanar X-rays supplements spatial and shape information for 2D/3D registration, but current methods are limited by dense-view requirements and struggles with noisy X-rays. To address these limitations, we introduce RadGS-Reg, a novel framework for vertebral-level CT/X-ray registration through joint 3D Radiative Gaussians (RadGS) reconstruction and 3D/3D registration. Specifically, our biplanar X-rays vertebral RadGS reconstruction module explores learning-based RadGS reconstruction method with a Counterfactual Attention Learning (CAL) mechanism, focusing on vertebral regions in noisy X-rays. Additionally, a patient-specific pre-training strategy progressively adapts the RadGS-Reg from simulated to real data while simultaneously learning vertebral shape prior knowledge. Experiments on in-house datasets demonstrate the state-of-the-art performance for both tasks, surpassing existing methods. The code is available at: https://github.com/shenao1995/RadGS_Reg.
Dyna3DGR: 4D Cardiac Motion Tracking with Dynamic 3D Gaussian Representation
Jul 22, 2025Accurate analysis of cardiac motion is crucial for evaluating cardiac function. While dynamic cardiac magnetic resonance imaging (CMR) can capture detailed tissue motion throughout the cardiac cycle, the fine-grained 4D cardiac motion tracking remains challenging due to the homogeneous nature of myocardial tissue and the lack of distinctive features. Existing approaches can be broadly categorized into image based and representation-based, each with its limitations. Image-based methods, including both raditional and deep learning-based registration approaches, either struggle with topological consistency or rely heavily on extensive training data. Representation-based methods, while promising, often suffer from loss of image-level details. To address these limitations, we propose Dynamic 3D Gaussian Representation (Dyna3DGR), a novel framework that combines explicit 3D Gaussian representation with implicit neural motion field modeling. Our method simultaneously optimizes cardiac structure and motion in a self-supervised manner, eliminating the need for extensive training data or point-to-point correspondences. Through differentiable volumetric rendering, Dyna3DGR efficiently bridges continuous motion representation with image-space alignment while preserving both topological and temporal consistency. Comprehensive evaluations on the ACDC dataset demonstrate that our approach surpasses state-of-the-art deep learning-based diffeomorphic registration methods in tracking accuracy. The code will be available in https://github.com/windrise/Dyna3DGR.
U-RWKV: Lightweight medical image segmentation with direction-adaptive RWKV
Jul 15, 2025Achieving equity in healthcare accessibility requires lightweight yet high-performance solutions for medical image segmentation, particularly in resource-limited settings. Existing methods like U-Net and its variants often suffer from limited global Effective Receptive Fields (ERFs), hindering their ability to capture long-range dependencies. To address this, we propose U-RWKV, a novel framework leveraging the Recurrent Weighted Key-Value(RWKV) architecture, which achieves efficient long-range modeling at O(N) computational cost. The framework introduces two key innovations: the Direction-Adaptive RWKV Module(DARM) and the Stage-Adaptive Squeeze-and-Excitation Module(SASE). DARM employs Dual-RWKV and QuadScan mechanisms to aggregate contextual cues across images, mitigating directional bias while preserving global context and maintaining high computational efficiency. SASE dynamically adapts its architecture to different feature extraction stages, balancing high-resolution detail preservation and semantic relationship capture. Experiments demonstrate that U-RWKV achieves state-of-the-art segmentation performance with high computational efficiency, offering a practical solution for democratizing advanced medical imaging technologies in resource-constrained environments. The code is available at https://github.com/hbyecoding/U-RWKV.
NeRF-based CBCT Reconstruction needs Normalization and Initialization
Jun 24, 2025Cone Beam Computed Tomography (CBCT) is widely used in medical imaging. However, the limited number and intensity of X-ray projections make reconstruction an ill-posed problem with severe artifacts. NeRF-based methods have achieved great success in this task. However, they suffer from a local-global training mismatch between their two key components: the hash encoder and the neural network. Specifically, in each training step, only a subset of the hash encoder's parameters is used (local sparse), whereas all parameters in the neural network participate (global dense). Consequently, hash features generated in each step are highly misaligned, as they come from different subsets of the hash encoder. These misalignments from different training steps are then fed into the neural network, causing repeated inconsistent global updates in training, which leads to unstable training, slower convergence, and degraded reconstruction quality. Aiming to alleviate the impact of this local-global optimization mismatch, we introduce a Normalized Hash Encoder, which enhances feature consistency and mitigates the mismatch. Additionally, we propose a Mapping Consistency Initialization(MCI) strategy that initializes the neural network before training by leveraging the global mapping property from a well-trained model. The initialized neural network exhibits improved stability during early training, enabling faster convergence and enhanced reconstruction performance. Our method is simple yet effective, requiring only a few lines of code while substantially improving training efficiency on 128 CT cases collected from 4 different datasets, covering 7 distinct anatomical regions.
MVP-CBM:Multi-layer Visual Preference-enhanced Concept Bottleneck Model for Explainable Medical Image Classification
Jun 14, 2025The concept bottleneck model (CBM), as a technique improving interpretability via linking predictions to human-understandable concepts, makes high-risk and life-critical medical image classification credible. Typically, existing CBM methods associate the final layer of visual encoders with concepts to explain the model's predictions. However, we empirically discover the phenomenon of concept preference variation, that is, the concepts are preferably associated with the features at different layers than those only at the final layer; yet a blind last-layer-based association neglects such a preference variation and thus weakens the accurate correspondences between features and concepts, impairing model interpretability. To address this issue, we propose a novel Multi-layer Visual Preference-enhanced Concept Bottleneck Model (MVP-CBM), which comprises two key novel modules: (1) intra-layer concept preference modeling, which captures the preferred association of different concepts with features at various visual layers, and (2) multi-layer concept sparse activation fusion, which sparsely aggregates concept activations from multiple layers to enhance performance. Thus, by explicitly modeling concept preferences, MVP-CBM can comprehensively leverage multi-layer visual information to provide a more nuanced and accurate explanation of model decisions. Extensive experiments on several public medical classification benchmarks demonstrate that MVP-CBM achieves state-of-the-art accuracy and interoperability, verifying its superiority. Code is available at https://github.com/wcj6/MVP-CBM.
* 7 pages, 6 figures,