 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProSoftArena: Benchmarking Hierarchical Capabilities of Multimodal Agents in Professional Software Environments
Dec 30, 2025Multimodal agents are making rapid progress on general computer-use tasks, yet existing benchmarks remain largely confined to browsers and basic desktop applications, falling short in professional software workflows that dominate real-world scientific and industrial practice. To close this gap, we introduce ProSoftArena, a benchmark and platform specifically for evaluating multimodal agents in professional software environments. We establish the first capability hierarchy tailored to agent use of professional software and construct a benchmark of 436 realistic work and research tasks spanning 6 disciplines and 13 core professional applications. To ensure reliable and reproducible assessment, we build an executable real-computer environment with an execution-based evaluation framework and uniquely incorporate a human-in-the-loop evaluation paradigm. Extensive experiments show that even the best-performing agent attains only a 24.4\% success rate on L2 tasks and completely fails on L3 multi-software workflow. In-depth analysis further provides valuable insights for addressing current agent limitations and more effective design principles, paving the way to build more capable agents in professional software settings. This project is available at: https://prosoftarena.github.io.
Code-in-the-Loop Forensics: Agentic Tool Use for Image Forgery Detection
Dec 18, 2025
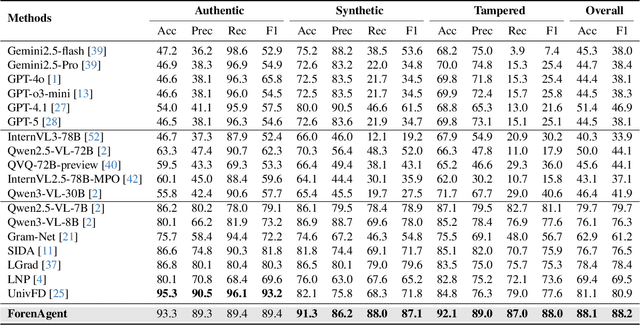
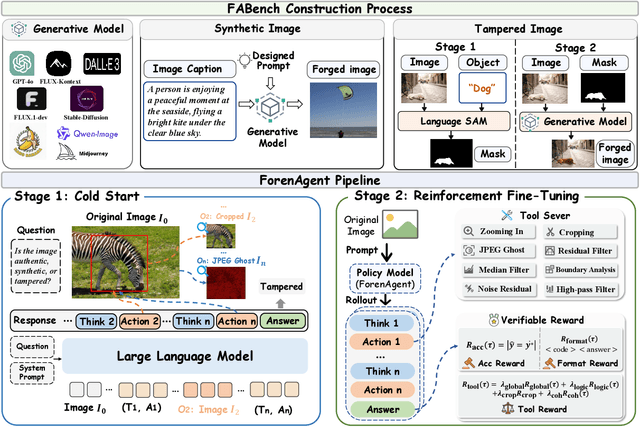
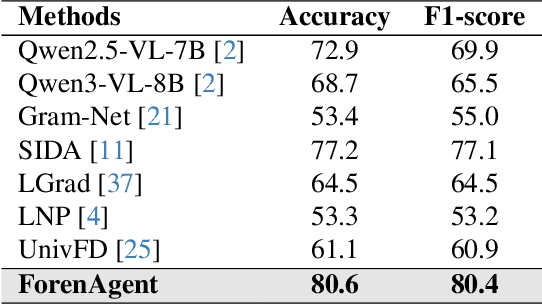
Existing image forgery detection (IFD) methods either exploit low-level, semantics-agnostic artifacts or rely on multimodal large language models (MLLMs) with high-level semantic knowledge. Although naturally complementary, these two information streams are highly heterogeneous in both paradigm and reasoning, making it difficult for existing methods to unify them or effectively model their cross-level interactions. To address this gap, we propose ForenAgent, a multi-round interactive IFD framework that enables MLLMs to autonomously generate, execute, and iteratively refine Python-based low-level tools around the detection objective, thereby achieving more flexible and interpretable forgery analysis. ForenAgent follows a two-stage training pipeline combining Cold Start and Reinforcement Fine-Tuning to enhance its tool interaction capability and reasoning adaptability progressively. Inspired by human reasoning, we design a dynamic reasoning loop comprising global perception, local focusing, iterative probing, and holistic adjudication, and instantiate it as both a data-sampling strategy and a task-aligned process reward. For systematic training and evaluation, we construct FABench, a heterogeneous, high-quality agent-forensics dataset comprising 100k images and approximately 200k agent-interaction question-answer pairs. Experiments show that ForenAgent exhibits emergent tool-use competence and reflective reasoning on challenging IFD tasks when assisted by low-level tools, charting a promising route toward general-purpose IFD. The code will be released after the review process is completed.
Dialogue as Discovery: Navigating Human Intent Through Principled Inquiry
Oct 31, 2025A fundamental bottleneck in human-AI collaboration is the "intention expression gap," the difficulty for humans to effectively convey complex, high-dimensional thoughts to AI. This challenge often traps users in inefficient trial-and-error loops and is exacerbated by the diverse expertise levels of users. We reframe this problem from passive instruction following to a Socratic collaboration paradigm, proposing an agent that actively probes for information to resolve its uncertainty about user intent. we name the proposed agent Nous, trained to acquire proficiency in this inquiry policy. The core mechanism of Nous is a training framework grounded in the first principles of information theory. Within this framework, we define the information gain from dialogue as an intrinsic reward signal, which is fundamentally equivalent to the reduction of Shannon entropy over a structured task space. This reward design enables us to avoid reliance on costly human preference annotations or external reward models. To validate our framework, we develop an automated simulation pipeline to generate a large-scale, preference-based dataset for the challenging task of scientific diagram generation. Comprehensive experiments, including ablations, subjective and objective evaluations, and tests across user expertise levels, demonstrate the effectiveness of our proposed framework. Nous achieves leading efficiency and output quality, while remaining robust to varying user expertise. Moreover, its design is domain-agnostic, and we show evidence of generalization beyond diagram generation. Experimental results prove that our work offers a principled, scalable, and adaptive paradigm for resolving uncertainty about user intent in complex human-AI collaboration.
From Pixels to Paths: A Multi-Agent Framework for Editable Scientific Illustration
Oct 31, 2025Scientific illustrations demand both high information density and post-editability. However, current generative models have two major limitations: Frist, image generation models output rasterized images lacking semantic structure, making it impossible to access, edit, or rearrange independent visual components in the images. Second, code-based generation methods (TikZ or SVG), although providing element-level control, force users into the cumbersome cycle of "writing-compiling-reviewing" and lack the intuitiveness of manipulation. Neither of these two approaches can well meet the needs for efficiency, intuitiveness, and iterative modification in scientific creation. To bridge this gap, we introduce VisPainter, a multi-agent framework for scientific illustration built upon the model context protocol. VisPainter orchestrates three specialized modules-a Manager, a Designer, and a Toolbox-to collaboratively produce diagrams compatible with standard vector graphics software. This modular, role-based design allows each element to be explicitly represented and manipulated, enabling true element-level control and any element can be added and modified later. To systematically evaluate the quality of scientific illustrations, we introduce VisBench, a benchmark with seven-dimensional evaluation metrics. It assesses high-information-density scientific illustrations from four aspects: content, layout, visual perception, and interaction cost. To this end, we conducted extensive ablation experiments to verify the rationality of our architecture and the reliability of our evaluation methods. Finally, we evaluated various vision-language models, presenting fair and credible model rankings along with detailed comparisons of their respective capabilities. Additionally, we isolated and quantified the impacts of role division, step control,and description on the quality of illustrations.
A High-Quality Dataset and Reliable Evaluation for Interleaved Image-Text Generation
Jun 11, 2025Recent advancements in Large Multimodal Models (LMMs) have significantly improved multimodal understanding and generation. However, these models still struggle to generate tightly interleaved image-text outputs, primarily due to the limited scale, quality and instructional richness of current training datasets. To address this, we introduce InterSyn, a large-scale multimodal dataset constructed using our Self-Evaluation with Iterative Refinement (SEIR) method. InterSyn features multi-turn, instruction-driven dialogues with tightly interleaved imagetext responses, providing rich object diversity and rigorous automated quality refinement, making it well-suited for training next-generation instruction-following LMMs. Furthermore, to address the lack of reliable evaluation tools capable of assessing interleaved multimodal outputs, we introduce SynJudge, an automatic evaluation model designed to quantitatively assess multimodal outputs along four dimensions: text content, image content, image quality, and image-text synergy. Experimental studies show that the SEIR method leads to substantially higher dataset quality compared to an otherwise identical process without refinement. Moreover, LMMs trained on InterSyn achieve uniform performance gains across all evaluation metrics, confirming InterSyn's utility for advancing multimodal systems.
SridBench: Benchmark of Scientific Research Illustration Drawing of Image Generation Model
May 28, 2025Recent years have seen rapid advances in AI-driven image generation. Early diffusion models emphasized perceptual quality, while newer multimodal models like GPT-4o-image integrate high-level reasoning, improving semantic understanding and structural composition. Scientific illustration generation exemplifies this evolution: unlike general image synthesis, it demands accurate interpretation of technical content and transformation of abstract ideas into clear, standardized visuals. This task is significantly more knowledge-intensive and laborious, often requiring hours of manual work and specialized tools. Automating it in a controllable, intelligent manner would provide substantial practical value. Yet, no benchmark currently exists to evaluate AI on this front. To fill this gap, we introduce SridBench, the first benchmark for scientific figure generation. It comprises 1,120 instances curated from leading scientific papers across 13 natural and computer science disciplines, collected via human experts and MLLMs. Each sample is evaluated along six dimensions, including semantic fidelity and structural accuracy. Experimental results reveal that even top-tier models like GPT-4o-image lag behind human performance, with common issues in text/visual clarity and scientific correctness. These findings highlight the need for more advanced reasoning-driven visual generation capabilities.
IA-T2I: Internet-Augmented Text-to-Image Generation
May 21, 2025Current text-to-image (T2I) generation models achieve promising results, but they fail on the scenarios where the knowledge implied in the text prompt is uncertain. For example, a T2I model released in February would struggle to generate a suitable poster for a movie premiering in April, because the character designs and styles are uncertain to the model. To solve this problem, we propose an Internet-Augmented text-to-image generation (IA-T2I) framework to compel T2I models clear about such uncertain knowledge by providing them with reference images. Specifically, an active retrieval module is designed to determine whether a reference image is needed based on the given text prompt; a hierarchical image selection module is introduced to find the most suitable image returned by an image search engine to enhance the T2I model; a self-reflection mechanism is presented to continuously evaluate and refine the generated image to ensure faithful alignment with the text prompt. To evaluate the proposed framework's performance, we collect a dataset named Img-Ref-T2I, where text prompts include three types of uncertain knowledge: (1) known but rare. (2) unknown. (3) ambiguous. Moreover, we carefully craft a complex prompt to guide GPT-4o in making preference evaluation, which has been shown to have an evaluation accuracy similar to that of human preference evaluation. Experimental results demonstrate the effectiveness of our framework, outperforming GPT-4o by about 30% in human evaluation.
Rethinking Lanes and Points in Complex Scenarios for Monocular 3D Lane Detection
Mar 08, 2025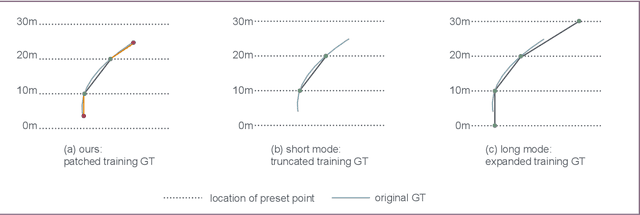
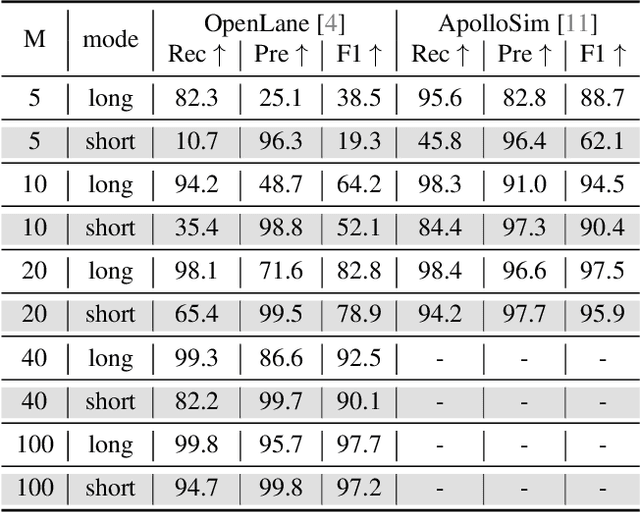
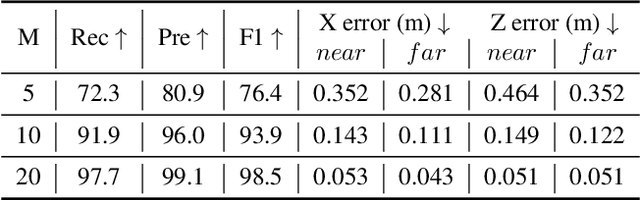
Monocular 3D lane detection is a fundamental task in autonomous driving. Although sparse-point methods lower computational load and maintain high accuracy in complex lane geometries, current methods fail to fully leverage the geometric structure of lanes in both lane geometry representations and model design. In lane geometry representations, we present a theoretical analysis alongside experimental validation to verify that current sparse lane representation methods contain inherent flaws, resulting in potential errors of up to 20 m, which raise significant safety concerns for driving. To address this issue, we propose a novel patching strategy to completely represent the full lane structure. To enable existing models to match this strategy, we introduce the EndPoint head (EP-head), which adds a patching distance to endpoints. The EP-head enables the model to predict more complete lane representations even with fewer preset points, effectively addressing existing limitations and paving the way for models that are faster and require fewer parameters in the future. In model design, to enhance the model's perception of lane structures, we propose the PointLane attention (PL-attention), which incorporates prior geometric knowledge into the attention mechanism. Extensive experiments demonstrate the effectiveness of the proposed methods on various state-of-the-art models. For instance, in terms of the overall F1-score, our methods improve Persformer by 4.4 points, Anchor3DLane by 3.2 points, and LATR by 2.8 points. The code will be available soon.
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
May 23, 2024



Autonomous agents that execute human tasks by controlling computers can enhance human productivity and application accessibility. Yet, progress in this field will be driven by realistic and reproducible benchmarks. We present AndroidWorld, a fully functioning Android environment that provides reward signals for 116 programmatic task workflows across 20 real world Android applications. Unlike existing interactive environments, which provide a static test set, AndroidWorld dynamically constructs tasks that are parameterized and expressed in natural language in unlimited ways, thus enabling testing on a much larger and realistic suite of tasks. Reward signals are derived from the computer's system state, making them durable across task variations and extensible across different apps. To demonstrate AndroidWorld's benefits and mode of operation, we introduce a new computer control agent, M3A. M3A can complete 30.6% of the AndroidWorld's tasks, leaving ample room for future work. Furthermore, we adapt a popular desktop web agent to work on Android, which we find to be less effective on mobile, suggesting future research is needed to achieve universal, cross-domain agents. Finally, we conduct a robustness analysis by testing M3A against a range of task variations on a representative subset of tasks, demonstrating that variations in task parameters can significantly alter the complexity of a task and therefore an agent's performance, highlighting the importance of testing agents under diverse conditions. AndroidWorld and the experiments in this paper are available at https://github.com/google-research/android_world.
Reviewing continual learning from the perspective of human-level intelligence
Nov 23, 2021
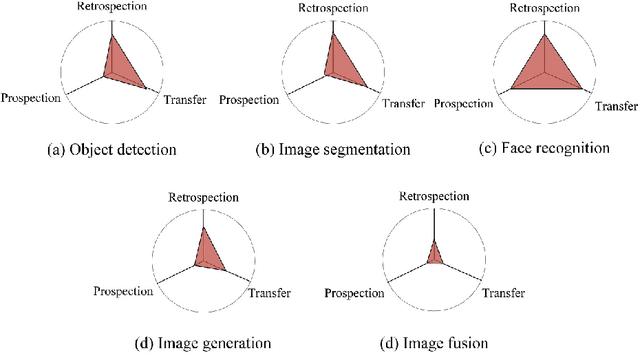
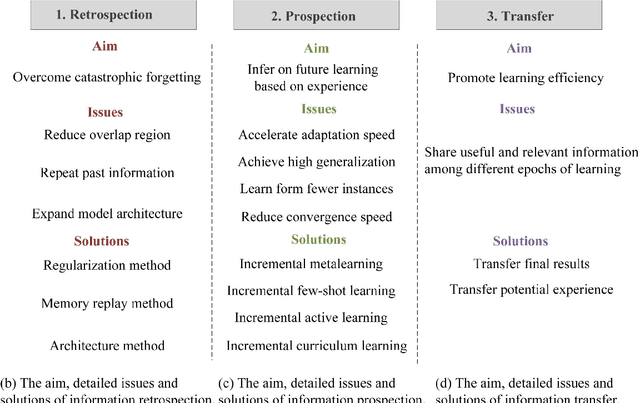
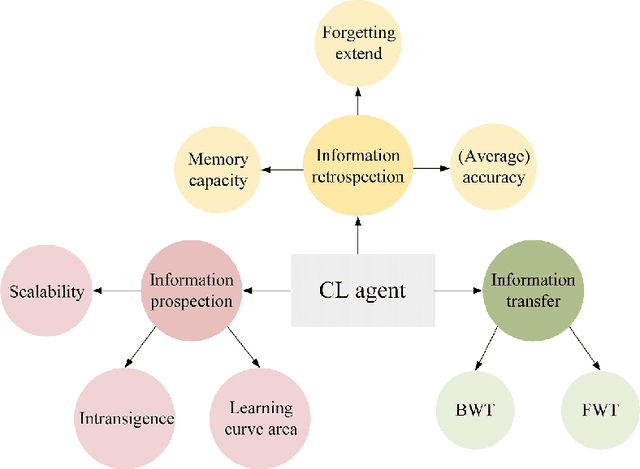
Humans' continual learning (CL) ability is closely related to Stability Versus Plasticity Dilemma that describes how humans achieve ongoing learning capacity and preservation for learned information. The notion of CL has always been present in artificial intelligence (AI) since its births. This paper proposes a comprehensive review of CL. Different from previous reviews that mainly focus on the catastrophic forgetting phenomenon in CL, this paper surveys CL from a more macroscopic perspective based on the Stability Versus Plasticity mechanism. Analogous to biological counterpart, "smart" AI agents are supposed to i) remember previously learned information (information retrospection); ii) infer on new information continuously (information prospection:); iii) transfer useful information (information transfer), to achieve high-level CL. According to the taxonomy, evaluation metrics, algorithms, applications as well as some open issues are then introduced. Our main contributions concern i) rechecking CL from the level of artificial general intelligence; ii) providing a detailed and extensive overview on CL topics; iii) presenting some novel ideas on the potential development of CL.