 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSilo-Bench: A Scalable Environment for Evaluating Distributed Coordination in Multi-Agent LLM Systems
Mar 01, 2026Large language models are increasingly deployed in multi-agent systems to overcome context limitations by distributing information across agents. Yet whether agents can reliably compute with distributed information -- rather than merely exchange it -- remains an open question. We introduce Silo-Bench, a role-agnostic benchmark of 30 algorithmic tasks across three communication complexity levels, evaluating 54 configurations over 1,620 experiments. Our experiments expose a fundamental Communication-Reasoning Gap: agents spontaneously form task-appropriate coordination topologies and exchange information actively, yet systematically fail to synthesize distributed state into correct answers. The failure is localized to the reasoning-integration stage -- agents often acquire sufficient information but cannot integrate it. This coordination overhead compounds with scale, eventually eliminating parallelization gains entirely. These findings demonstrate that naively scaling agent count cannot circumvent context limitations, and Silo-Bench provides a foundation for tracking progress toward genuinely collaborative multi-agent systems.
Rethinking Lanes and Points in Complex Scenarios for Monocular 3D Lane Detection
Mar 08, 2025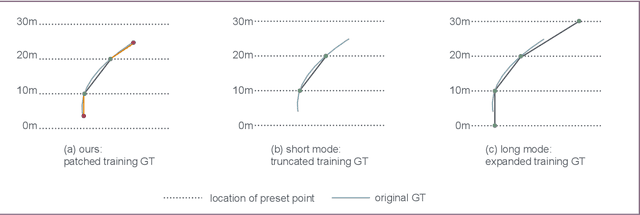
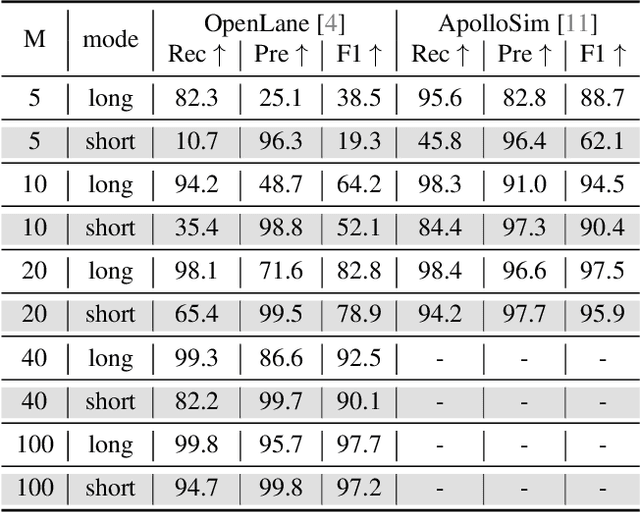
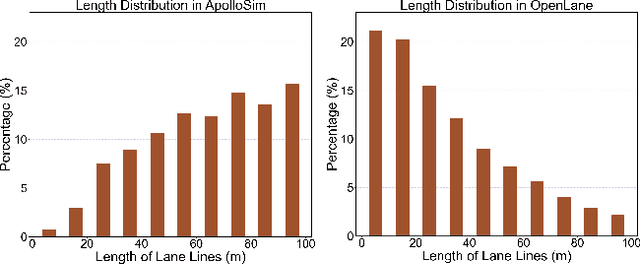
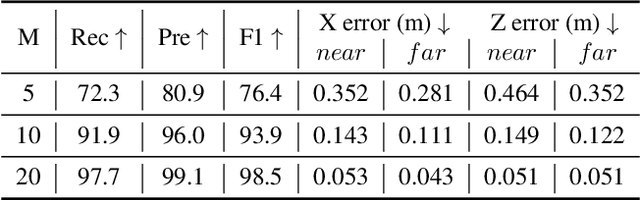
Monocular 3D lane detection is a fundamental task in autonomous driving. Although sparse-point methods lower computational load and maintain high accuracy in complex lane geometries, current methods fail to fully leverage the geometric structure of lanes in both lane geometry representations and model design. In lane geometry representations, we present a theoretical analysis alongside experimental validation to verify that current sparse lane representation methods contain inherent flaws, resulting in potential errors of up to 20 m, which raise significant safety concerns for driving. To address this issue, we propose a novel patching strategy to completely represent the full lane structure. To enable existing models to match this strategy, we introduce the EndPoint head (EP-head), which adds a patching distance to endpoints. The EP-head enables the model to predict more complete lane representations even with fewer preset points, effectively addressing existing limitations and paving the way for models that are faster and require fewer parameters in the future. In model design, to enhance the model's perception of lane structures, we propose the PointLane attention (PL-attention), which incorporates prior geometric knowledge into the attention mechanism. Extensive experiments demonstrate the effectiveness of the proposed methods on various state-of-the-art models. For instance, in terms of the overall F1-score, our methods improve Persformer by 4.4 points, Anchor3DLane by 3.2 points, and LATR by 2.8 points. The code will be available soon.
GraphAD: Interaction Scene Graph for End-to-end Autonomous Driving
Apr 07, 2024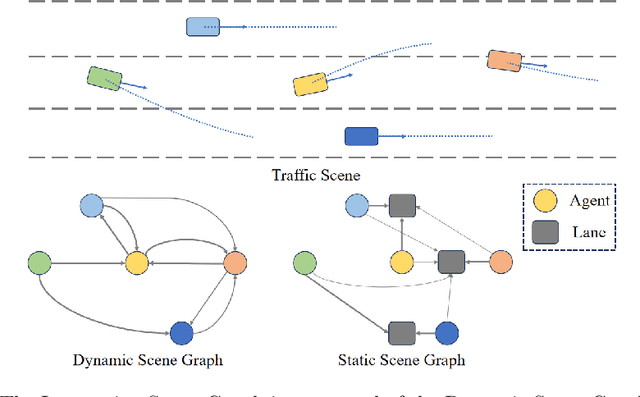
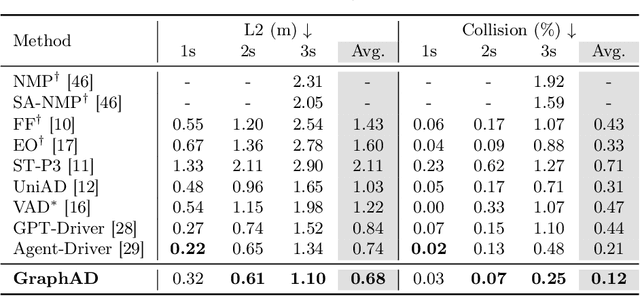
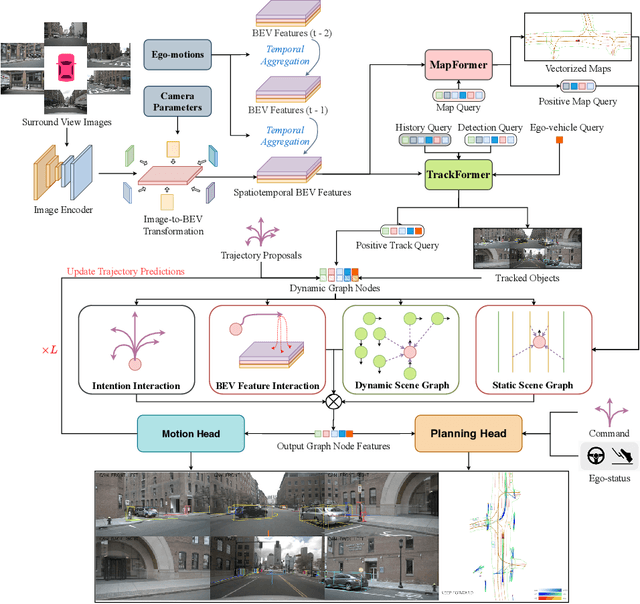
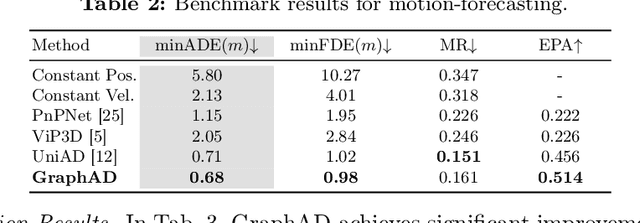
Modeling complicated interactions among the ego-vehicle, road agents, and map elements has been a crucial part for safety-critical autonomous driving. Previous works on end-to-end autonomous driving rely on the attention mechanism for handling heterogeneous interactions, which fails to capture the geometric priors and is also computationally intensive. In this paper, we propose the Interaction Scene Graph (ISG) as a unified method to model the interactions among the ego-vehicle, road agents, and map elements. With the representation of the ISG, the driving agents aggregate essential information from the most influential elements, including the road agents with potential collisions and the map elements to follow. Since a mass of unnecessary interactions are omitted, the more efficient scene-graph-based framework is able to focus on indispensable connections and leads to better performance. We evaluate the proposed method for end-to-end autonomous driving on the nuScenes dataset. Compared with strong baselines, our method significantly outperforms in the full-stack driving tasks, including perception, prediction, and planning. Code will be released at https://github.com/zhangyp15/GraphAD.
3DSFLabelling: Boosting 3D Scene Flow Estimation by Pseudo Auto-labelling
Mar 01, 2024



Learning 3D scene flow from LiDAR point clouds presents significant difficulties, including poor generalization from synthetic datasets to real scenes, scarcity of real-world 3D labels, and poor performance on real sparse LiDAR point clouds. We present a novel approach from the perspective of auto-labelling, aiming to generate a large number of 3D scene flow pseudo labels for real-world LiDAR point clouds. Specifically, we employ the assumption of rigid body motion to simulate potential object-level rigid movements in autonomous driving scenarios. By updating different motion attributes for multiple anchor boxes, the rigid motion decomposition is obtained for the whole scene. Furthermore, we developed a novel 3D scene flow data augmentation method for global and local motion. By perfectly synthesizing target point clouds based on augmented motion parameters, we easily obtain lots of 3D scene flow labels in point clouds highly consistent with real scenarios. On multiple real-world datasets including LiDAR KITTI, nuScenes, and Argoverse, our method outperforms all previous supervised and unsupervised methods without requiring manual labelling. Impressively, our method achieves a tenfold reduction in EPE3D metric on the LiDAR KITTI dataset, reducing it from $0.190m$ to a mere $0.008m$ error.
Detecting As Labeling: Rethinking LiDAR-camera Fusion in 3D Object Detection
Nov 13, 2023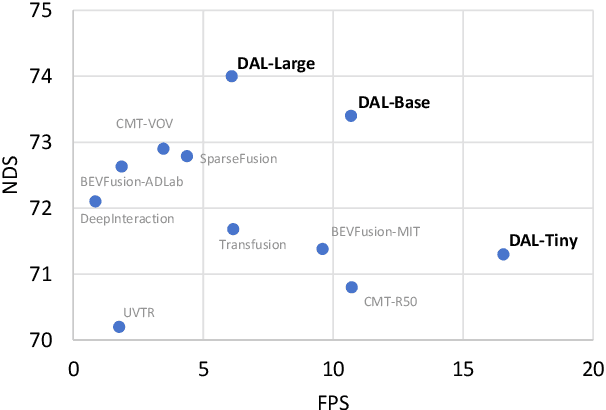

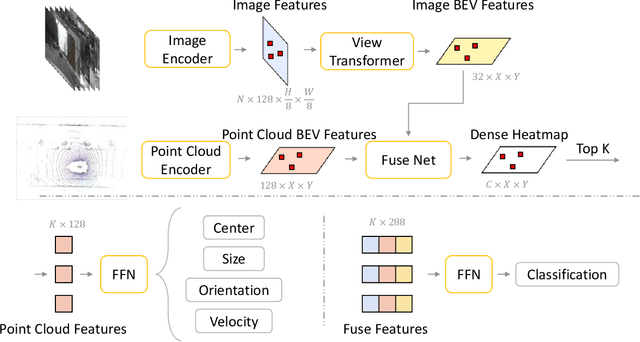
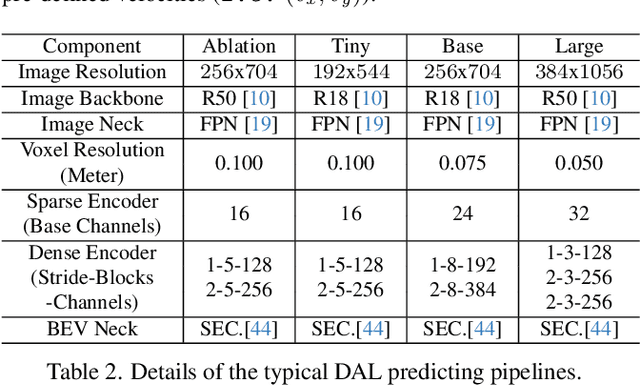
3D object Detection with LiDAR-camera encounters overfitting in algorithm development which is derived from the violation of some fundamental rules. We refer to the data annotation in dataset construction for theory complementing and argue that the regression task prediction should not involve the feature from the camera branch. By following the cutting-edge perspective of 'Detecting As Labeling', we propose a novel paradigm dubbed DAL. With the most classical elementary algorithms, a simple predicting pipeline is constructed by imitating the data annotation process. Then we train it in the simplest way to minimize its dependency and strengthen its portability. Though simple in construction and training, the proposed DAL paradigm not only substantially pushes the performance boundary but also provides a superior trade-off between speed and accuracy among all existing methods. With comprehensive superiority, DAL is an ideal baseline for both future work development and practical deployment. The code has been released to facilitate future work on https://github.com/HuangJunJie2017/BEVDet.
HPS-Det: Dynamic Sample Assignment with Hyper-Parameter Search for Object Detection
Jul 23, 2022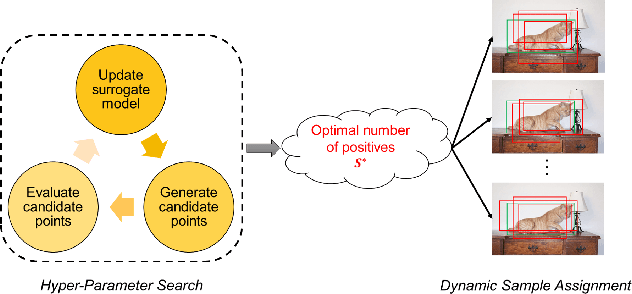

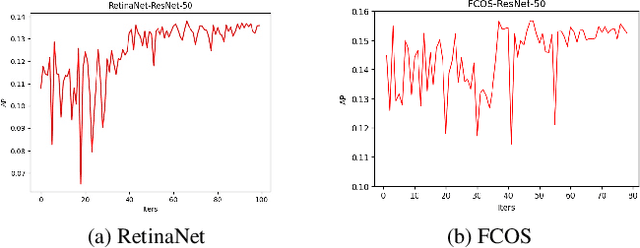
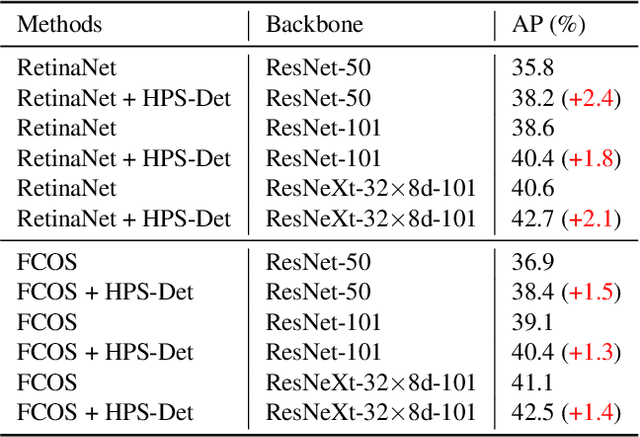
Sample assignment plays a prominent part in modern object detection approaches. However, most existing methods rely on manual design to assign positive / negative samples, which do not explicitly establish the relationships between sample assignment and object detection performance. In this work, we propose a novel dynamic sample assignment scheme based on hyper-parameter search. We first define the number of positive samples assigned to each ground truth as the hyper-parameters and employ a surrogate optimization algorithm to derive the optimal choices. Then, we design a dynamic sample assignment procedure to dynamically select the optimal number of positives at each training iteration. Experiments demonstrate that the resulting HPS-Det brings improved performance over different object detection baselines. Moreover, We analyze the hyper-parameter reusability when transferring between different datasets and between different backbones for object detection, which exhibits the superiority and versatility of our method.
Dual Cross-Attention Learning for Fine-Grained Visual Categorization and Object Re-Identification
May 04, 2022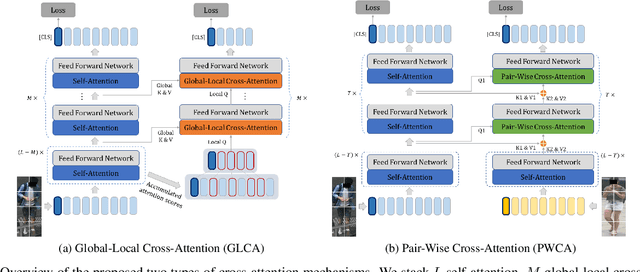
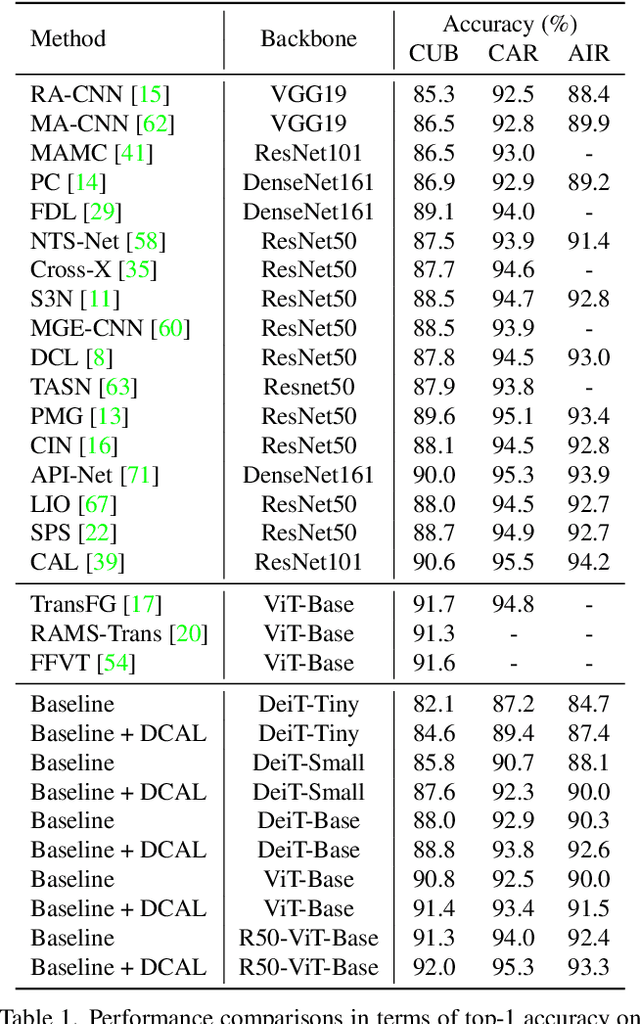
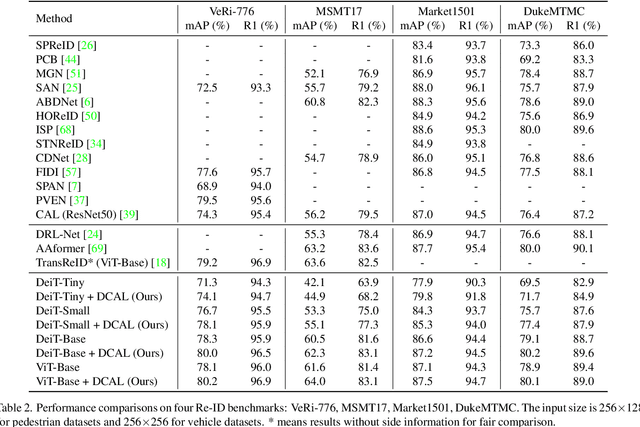
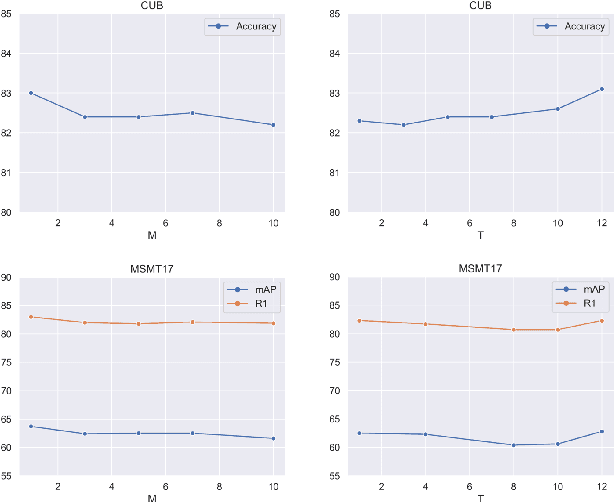
Recently, self-attention mechanisms have shown impressive performance in various NLP and CV tasks, which can help capture sequential characteristics and derive global information. In this work, we explore how to extend self-attention modules to better learn subtle feature embeddings for recognizing fine-grained objects, e.g., different bird species or person identities. To this end, we propose a dual cross-attention learning (DCAL) algorithm to coordinate with self-attention learning. First, we propose global-local cross-attention (GLCA) to enhance the interactions between global images and local high-response regions, which can help reinforce the spatial-wise discriminative clues for recognition. Second, we propose pair-wise cross-attention (PWCA) to establish the interactions between image pairs. PWCA can regularize the attention learning of an image by treating another image as distractor and will be removed during inference. We observe that DCAL can reduce misleading attentions and diffuse the attention response to discover more complementary parts for recognition. We conduct extensive evaluations on fine-grained visual categorization and object re-identification. Experiments demonstrate that DCAL performs on par with state-of-the-art methods and consistently improves multiple self-attention baselines, e.g., surpassing DeiT-Tiny and ViT-Base by 2.8% and 2.4% mAP on MSMT17, respectively.
Dynamic Sparse R-CNN
May 04, 2022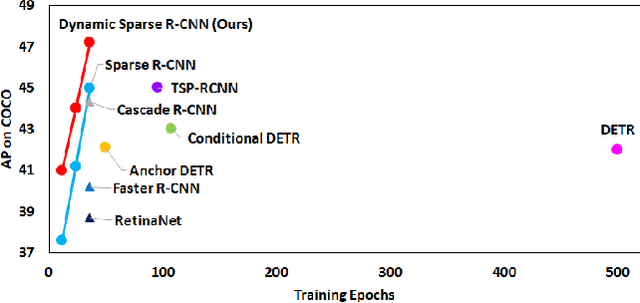
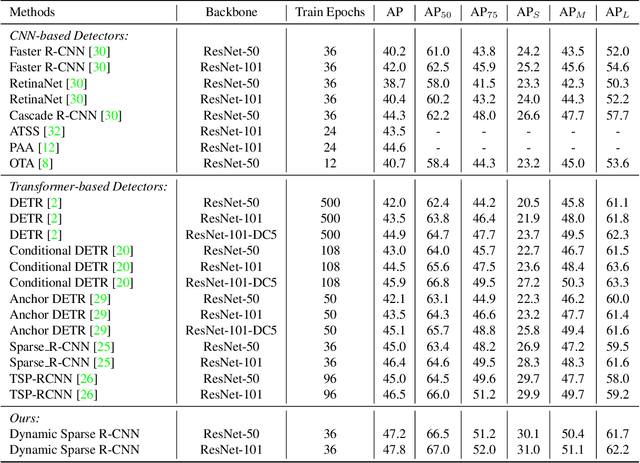
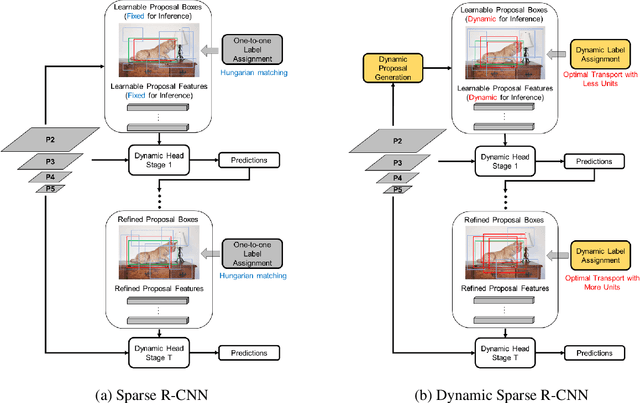

Sparse R-CNN is a recent strong object detection baseline by set prediction on sparse, learnable proposal boxes and proposal features. In this work, we propose to improve Sparse R-CNN with two dynamic designs. First, Sparse R-CNN adopts a one-to-one label assignment scheme, where the Hungarian algorithm is applied to match only one positive sample for each ground truth. Such one-to-one assignment may not be optimal for the matching between the learned proposal boxes and ground truths. To address this problem, we propose dynamic label assignment (DLA) based on the optimal transport algorithm to assign increasing positive samples in the iterative training stages of Sparse R-CNN. We constrain the matching to be gradually looser in the sequential stages as the later stage produces the refined proposals with improved precision. Second, the learned proposal boxes and features remain fixed for different images in the inference process of Sparse R-CNN. Motivated by dynamic convolution, we propose dynamic proposal generation (DPG) to assemble multiple proposal experts dynamically for providing better initial proposal boxes and features for the consecutive training stages. DPG thereby can derive sample-dependent proposal boxes and features for inference. Experiments demonstrate that our method, named Dynamic Sparse R-CNN, can boost the strong Sparse R-CNN baseline with different backbones for object detection. Particularly, Dynamic Sparse R-CNN reaches the state-of-the-art 47.2% AP on the COCO 2017 validation set, surpassing Sparse R-CNN by 2.2% AP with the same ResNet-50 backbone.
Towards Discriminative Representation Learning for Unsupervised Person Re-identification
Aug 16, 2021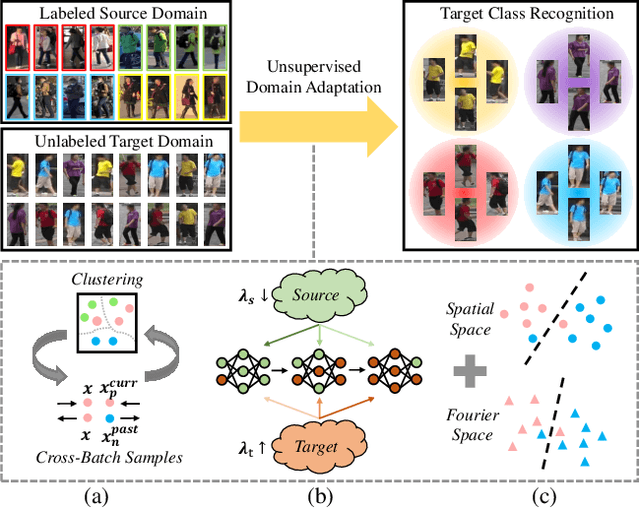
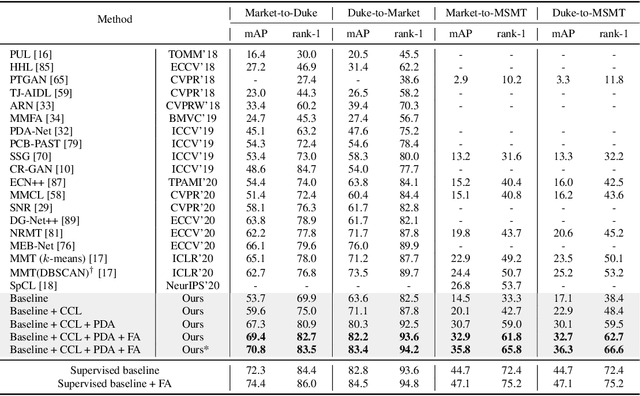
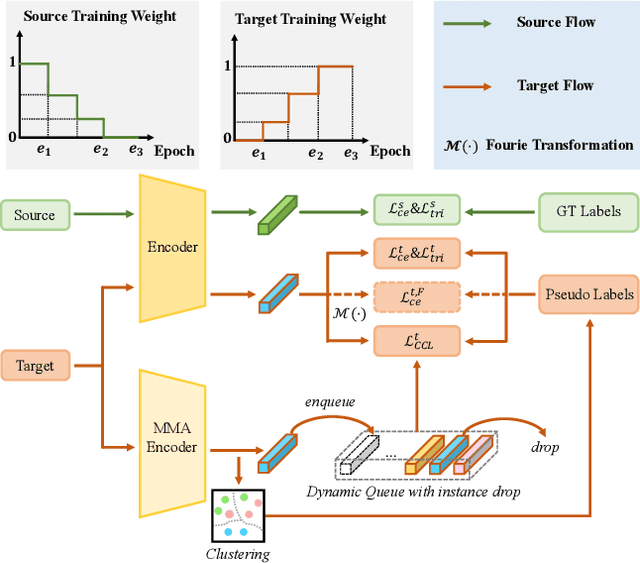
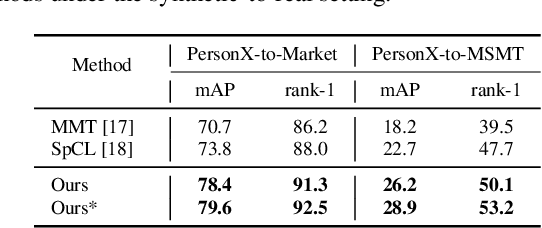
In this work, we address the problem of unsupervised domain adaptation for person re-ID where annotations are available for the source domain but not for target. Previous methods typically follow a two-stage optimization pipeline, where the network is first pre-trained on source and then fine-tuned on target with pseudo labels created by feature clustering. Such methods sustain two main limitations. (1) The label noise may hinder the learning of discriminative features for recognizing target classes. (2) The domain gap may hinder knowledge transferring from source to target. We propose three types of technical schemes to alleviate these issues. First, we propose a cluster-wise contrastive learning algorithm (CCL) by iterative optimization of feature learning and cluster refinery to learn noise-tolerant representations in the unsupervised manner. Second, we adopt a progressive domain adaptation (PDA) strategy to gradually mitigate the domain gap between source and target data. Third, we propose Fourier augmentation (FA) for further maximizing the class separability of re-ID models by imposing extra constraints in the Fourier space. We observe that these proposed schemes are capable of facilitating the learning of discriminative feature representations. Experiments demonstrate that our method consistently achieves notable improvements over the state-of-the-art unsupervised re-ID methods on multiple benchmarks, e.g., surpassing MMT largely by 8.1\%, 9.9\%, 11.4\% and 11.1\% mAP on the Market-to-Duke, Duke-to-Market, Market-to-MSMT and Duke-to-MSMT tasks, respectively.
Cross-Dataset Collaborative Learning for Semantic Segmentation
Mar 21, 2021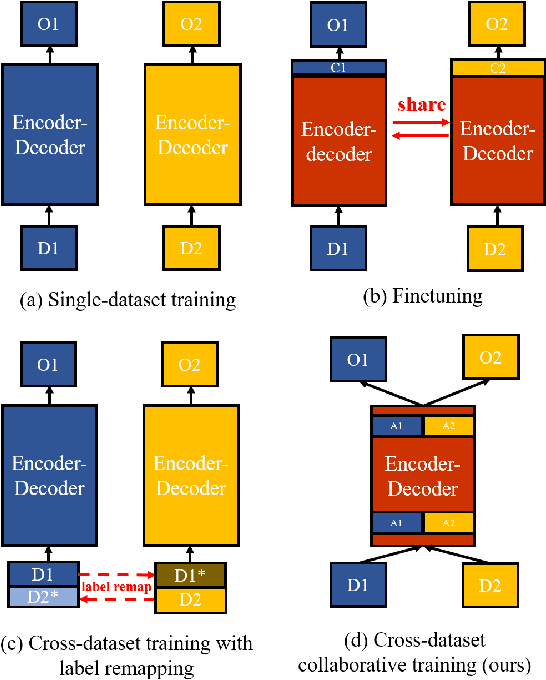
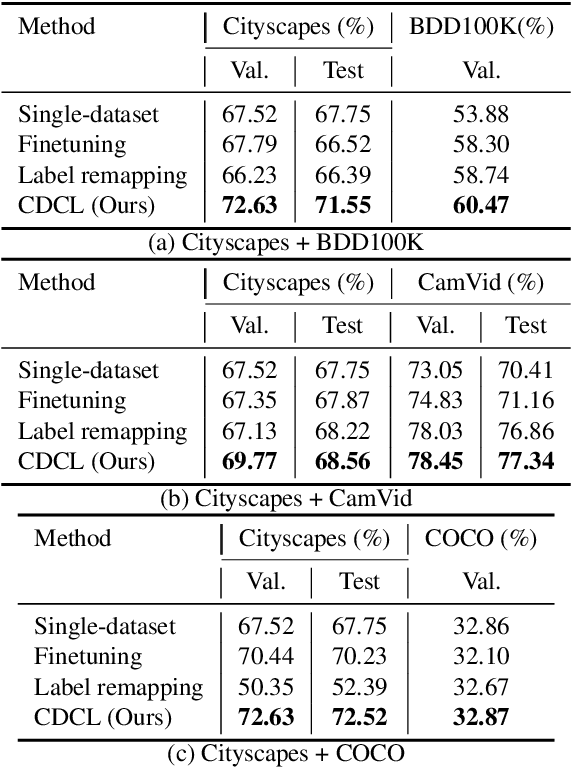
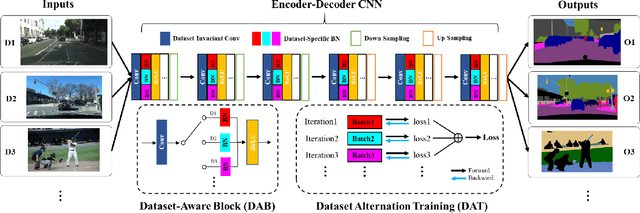

Recent work attempts to improve semantic segmentation performance by exploring well-designed architectures on a target dataset. However, it remains challenging to build a unified system that simultaneously learns from various datasets due to the inherent distribution shift across different datasets. In this paper, we present a simple, flexible, and general method for semantic segmentation, termed Cross-Dataset Collaborative Learning (CDCL). Given multiple labeled datasets, we aim to improve the generalization and discrimination of feature representations on each dataset. Specifically, we first introduce a family of Dataset-Aware Blocks (DAB) as the fundamental computing units of the network, which help capture homogeneous representations and heterogeneous statistics across different datasets. Second, we propose a Dataset Alternation Training (DAT) mechanism to efficiently facilitate the optimization procedure. We conduct extensive evaluations on four diverse datasets, i.e., Cityscapes, BDD100K, CamVid, and COCO Stuff, with single-dataset and cross-dataset settings. Experimental results demonstrate our method consistently achieves notable improvements over prior single-dataset and cross-dataset training methods without introducing extra FLOPs. Particularly, with the same architecture of PSPNet (ResNet-18), our method outperforms the single-dataset baseline by 5.65\%, 6.57\%, and 5.79\% of mIoU on the validation sets of Cityscapes, BDD100K, CamVid, respectively. Code and models will be released.