 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRIP2: A Robust and Powerful Deep Knockoff Method for Feature Selection
Jan 30, 2026Identifying truly predictive covariates while strictly controlling false discoveries remains a fundamental challenge in nonlinear, highly correlated, and low signal-to-noise regimes, where deep learning based feature selection methods are most attractive. We propose Group Regularization Importance Persistence in 2 Dimensions (GRIP2), a deep knockoff feature importance statistic that integrates first-layer feature activity over a two-dimensional regularization surface controlling both sparsity strength and sparsification geometry. To approximate this surface integral in a single training run, we introduce efficient block-stochastic sampling, which aggregates feature activity magnitudes across diverse regularization regimes along the optimization trajectory. The resulting statistics are antisymmetric by construction, ensuring finite-sample FDR control. In extensive experiments on synthetic and semi-real data, GRIP2 demonstrates improved robustness to feature correlation and noise level: in high correlation and low signal-to-noise ratio regimes where standard deep learning based feature selectors may struggle, our method retains high power and stability. Finally, on real-world HIV drug resistance data, GRIP2 recovers known resistance-associated mutations with power better than established linear baselines, confirming its reliability in practice.
Automatic and Structure-Aware Sparsification of Hybrid Neural ODEs
May 25, 2025Hybrid neural ordinary differential equations (neural ODEs) integrate mechanistic models with neural ODEs, offering strong inductive bias and flexibility, and are particularly advantageous in data-scarce healthcare settings. However, excessive latent states and interactions from mechanistic models can lead to training inefficiency and over-fitting, limiting practical effectiveness of hybrid neural ODEs. In response, we propose a new hybrid pipeline for automatic state selection and structure optimization in mechanistic neural ODEs, combining domain-informed graph modifications with data-driven regularization to sparsify the model for improving predictive performance and stability while retaining mechanistic plausibility. Experiments on synthetic and real-world data show improved predictive performance and robustness with desired sparsity, establishing an effective solution for hybrid model reduction in healthcare applications.
DL-QAT: Weight-Decomposed Low-Rank Quantization-Aware Training for Large Language Models
Apr 12, 2025Improving the efficiency of inference in Large Language Models (LLMs) is a critical area of research. Post-training Quantization (PTQ) is a popular technique, but it often faces challenges at low-bit levels, particularly in downstream tasks. Quantization-aware Training (QAT) can alleviate this problem, but it requires significantly more computational resources. To tackle this, we introduced Weight-Decomposed Low-Rank Quantization-Aware Training (DL-QAT), which merges the advantages of QAT while training only less than 1% of the total parameters. Specifically, we introduce a group-specific quantization magnitude to adjust the overall scale of each quantization group. Within each quantization group, we use LoRA matrices to update the weight size and direction in the quantization space. We validated the effectiveness of our method on the LLaMA and LLaMA2 model families. The results show significant improvements over our baseline method across different quantization granularities. For instance, for LLaMA-7B, our approach outperforms the previous state-of-the-art method by 4.2% in MMLU on 3-bit LLaMA-7B model. Additionally, our quantization results on pre-trained models also surpass previous QAT methods, demonstrating the superior performance and efficiency of our approach.
MonoGS++: Fast and Accurate Monocular RGB Gaussian SLAM
Apr 03, 2025We present MonoGS++, a novel fast and accurate Simultaneous Localization and Mapping (SLAM) method that leverages 3D Gaussian representations and operates solely on RGB inputs. While previous 3D Gaussian Splatting (GS)-based methods largely depended on depth sensors, our approach reduces the hardware dependency and only requires RGB input, leveraging online visual odometry (VO) to generate sparse point clouds in real-time. To reduce redundancy and enhance the quality of 3D scene reconstruction, we implemented a series of methodological enhancements in 3D Gaussian mapping. Firstly, we introduced dynamic 3D Gaussian insertion to avoid adding redundant Gaussians in previously well-reconstructed areas. Secondly, we introduced clarity-enhancing Gaussian densification module and planar regularization to handle texture-less areas and flat surfaces better. We achieved precise camera tracking results both on the synthetic Replica and real-world TUM-RGBD datasets, comparable to those of the state-of-the-art. Additionally, our method realized a significant 5.57x improvement in frames per second (fps) over the previous state-of-the-art, MonoGS.
Partial Convolution Meets Visual Attention
Mar 05, 2025Designing an efficient and effective neural network has remained a prominent topic in computer vision research. Depthwise onvolution (DWConv) is widely used in efficient CNNs or ViTs, but it needs frequent memory access during inference, which leads to low throughput. FasterNet attempts to introduce partial convolution (PConv) as an alternative to DWConv but compromises the accuracy due to underutilized channels. To remedy this shortcoming and consider the redundancy between feature map channels, we introduce a novel Partial visual ATtention mechanism (PAT) that can efficiently combine PConv with visual attention. Our exploration indicates that the partial attention mechanism can completely replace the full attention mechanism and reduce model parameters and FLOPs. Our PAT can derive three types of blocks: Partial Channel-Attention block (PAT_ch), Partial Spatial-Attention block (PAT_sp) and Partial Self-Attention block (PAT_sf). First, PAT_ch integrates the enhanced Gaussian channel attention mechanism to infuse global distribution information into the untouched channels of PConv. Second, we introduce the spatial-wise attention to the MLP layer to further improve model accuracy. Finally, we replace PAT_ch in the last stage with the self-attention mechanism to extend the global receptive field. Building upon PAT, we propose a novel hybrid network family, named PATNet, which achieves superior top-1 accuracy and inference speed compared to FasterNet on ImageNet-1K classification and excel in both detection and segmentation on the COCO dataset. Particularly, our PATNet-T2 achieves 1.3% higher accuracy than FasterNet-T2, while exhibiting 25% higher GPU throughput and 24% lower CPU latency.
MSWA: Refining Local Attention with Multi-ScaleWindow Attention
Jan 02, 2025



Transformer-based LLMs have achieved exceptional performance across a wide range of NLP tasks. However, the standard self-attention mechanism suffers from quadratic time complexity and linearly increased cache size. Sliding window attention (SWA) solves this problem by restricting the attention range to a fixed-size local context window. Nevertheless, SWA employs a uniform window size for each head in each layer, making it inefficient in capturing context of varying scales. To mitigate this limitation, we propose Multi-Scale Window Attention (MSWA) which applies diverse window sizes across heads and layers in the Transformer. It not only allows for different window sizes among heads within the same layer but also progressively increases window size allocation from shallow to deep layers, thus enabling the model to capture contextual information with different lengths and distances. Experimental results on language modeling and common-sense reasoning tasks substantiate that MSWA outperforms traditional local attention in both effectiveness and efficiency.
EGSRAL: An Enhanced 3D Gaussian Splatting based Renderer with Automated Labeling for Large-Scale Driving Scene
Dec 20, 2024



3D Gaussian Splatting (3D GS) has gained popularity due to its faster rendering speed and high-quality novel view synthesis. Some researchers have explored using 3D GS for reconstructing driving scenes. However, these methods often rely on various data types, such as depth maps, 3D boxes, and trajectories of moving objects. Additionally, the lack of annotations for synthesized images limits their direct application in downstream tasks. To address these issues, we propose EGSRAL, a 3D GS-based method that relies solely on training images without extra annotations. EGSRAL enhances 3D GS's capability to model both dynamic objects and static backgrounds and introduces a novel adaptor for auto labeling, generating corresponding annotations based on existing annotations. We also propose a grouping strategy for vanilla 3D GS to address perspective issues in rendering large-scale, complex scenes. Our method achieves state-of-the-art performance on multiple datasets without any extra annotation. For example, the PSNR metric reaches 29.04 on the nuScenes dataset. Moreover, our automated labeling can significantly improve the performance of 2D/3D detection tasks. Code is available at https://github.com/jiangxb98/EGSRAL.
FTP: A Fine-grained Token-wise Pruner for Large Language Models via Token Routing
Dec 16, 2024Recently, large language models (LLMs) have demonstrated superior performance across various tasks by adhering to scaling laws, which significantly increase model size. However, the huge computation overhead during inference hinders the deployment in industrial applications. Many works leverage traditional compression approaches to boost model inference, but these always introduce additional training costs to restore the performance and the pruning results typically show noticeable performance drops compared to the original model when aiming for a specific level of acceleration. To address these issues, we propose a fine-grained token-wise pruning approach for the LLMs, which presents a learnable router to adaptively identify the less important tokens and skip them across model blocks to reduce computational cost during inference. To construct the router efficiently, we present a search-based sparsity scheduler for pruning sparsity allocation, a trainable router combined with our proposed four low-dimensional factors as input and three proposed losses. We conduct extensive experiments across different benchmarks on different LLMs to demonstrate the superiority of our method. Our approach achieves state-of-the-art (SOTA) pruning results, surpassing other existing pruning methods. For instance, our method outperforms BlockPruner and ShortGPT by approximately 10 points on both LLaMA2-7B and Qwen1.5-7B in accuracy retention at comparable token sparsity levels.
Fast Occupancy Network
Dec 10, 2024Occupancy Network has recently attracted much attention in autonomous driving. Instead of monocular 3D detection and recent bird's eye view(BEV) models predicting 3D bounding box of obstacles, Occupancy Network predicts the category of voxel in specified 3D space around the ego vehicle via transforming 3D detection task into 3D voxel segmentation task, which has much superiority in tackling category outlier obstacles and providing fine-grained 3D representation. However, existing methods usually require huge computation resources than previous methods, which hinder the Occupancy Network solution applying in intelligent driving systems. To address this problem, we make an analysis of the bottleneck of Occupancy Network inference cost, and present a simple and fast Occupancy Network model, which adopts a deformable 2D convolutional layer to lift BEV feature to 3D voxel feature and presents an efficient voxel feature pyramid network (FPN) module to improve performance with few computational cost. Further, we present a cost-free 2D segmentation branch in perspective view after feature extractors for Occupancy Network during inference phase to improve accuracy. Experimental results demonstrate that our method consistently outperforms existing methods in both accuracy and inference speed, which surpasses recent state-of-the-art (SOTA) OCCNet by 1.7% with ResNet50 backbone with about 3X inference speedup. Furthermore, our method can be easily applied to existing BEV models to transform them into Occupancy Network models.
DiP-GO: A Diffusion Pruner via Few-step Gradient Optimization
Oct 22, 2024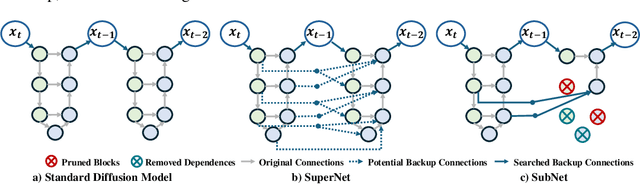
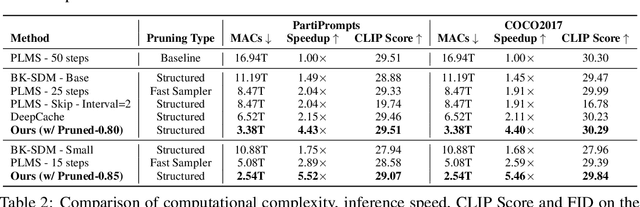
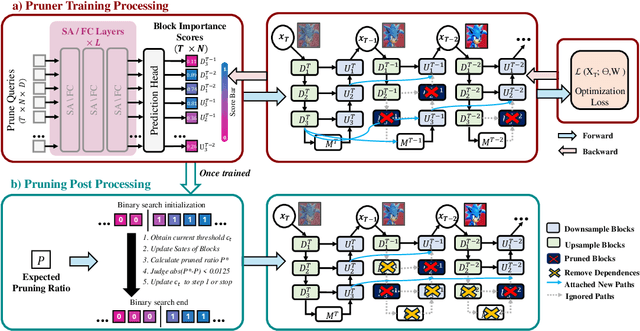

Diffusion models have achieved remarkable progress in the field of image generation due to their outstanding capabilities. However, these models require substantial computing resources because of the multi-step denoising process during inference. While traditional pruning methods have been employed to optimize these models, the retraining process necessitates large-scale training datasets and extensive computational costs to maintain generalization ability, making it neither convenient nor efficient. Recent studies attempt to utilize the similarity of features across adjacent denoising stages to reduce computational costs through simple and static strategies. However, these strategies cannot fully harness the potential of the similar feature patterns across adjacent timesteps. In this work, we propose a novel pruning method that derives an efficient diffusion model via a more intelligent and differentiable pruner. At the core of our approach is casting the model pruning process into a SubNet search process. Specifically, we first introduce a SuperNet based on standard diffusion via adding some backup connections built upon the similar features. We then construct a plugin pruner network and design optimization losses to identify redundant computation. Finally, our method can identify an optimal SubNet through few-step gradient optimization and a simple post-processing procedure. We conduct extensive experiments on various diffusion models including Stable Diffusion series and DiTs. Our DiP-GO approach achieves 4.4 x speedup for SD-1.5 without any loss of accuracy, significantly outperforming the previous state-of-the-art methods.