 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIND: From Passive Mimicry to Active Reasoning through Capability-Aware Multi-Perspective CoT Distillation
Jan 07, 2026While Large Language Models (LLMs) have emerged with remarkable capabilities in complex tasks through Chain-of-Thought reasoning, practical resource constraints have sparked interest in transferring these abilities to smaller models. However, achieving both domain performance and cross-domain generalization remains challenging. Existing approaches typically restrict students to following a single golden rationale and treat different reasoning paths independently. Due to distinct inductive biases and intrinsic preferences, alongside the student's evolving capacity and reasoning preferences during training, a teacher's "optimal" rationale could act as out-of-distribution noise. This misalignment leads to a degeneration of the student's latent reasoning distribution, causing suboptimal performance. To bridge this gap, we propose MIND, a capability-adaptive framework that transitions distillation from passive mimicry to active cognitive construction. We synthesize diverse teacher perspectives through a novel "Teaching Assistant" network. By employing a Feedback-Driven Inertia Calibration mechanism, this network utilizes inertia-filtered training loss to align supervision with the student's current adaptability, effectively enhancing performance while mitigating catastrophic forgetting. Extensive experiments demonstrate that MIND achieves state-of-the-art performance on both in-distribution and out-of-distribution benchmarks, and our sophisticated latent space analysis further confirms the mechanism of reasoning ability internalization.
DeepKD: A Deeply Decoupled and Denoised Knowledge Distillation Trainer
May 21, 2025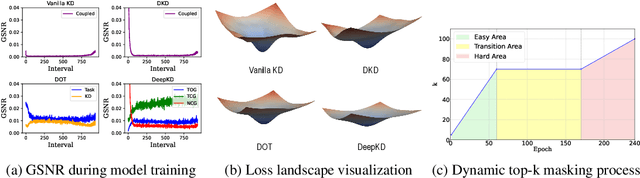
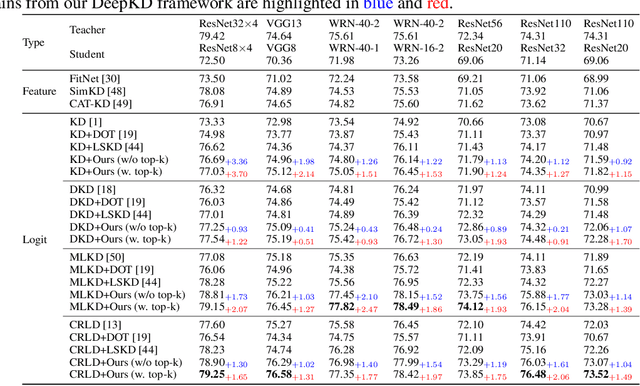
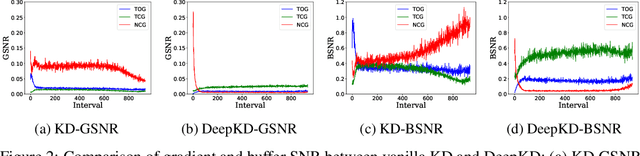
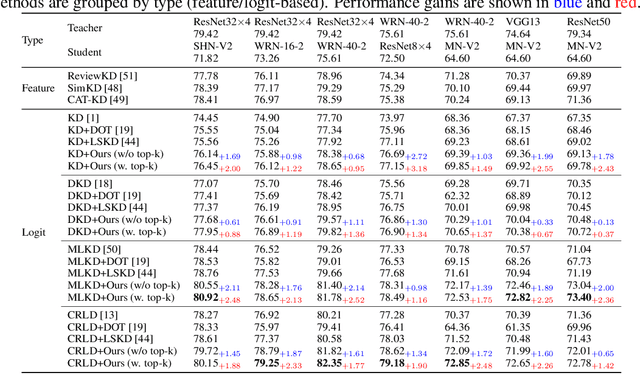
Recent advances in knowledge distillation have emphasized the importance of decoupling different knowledge components. While existing methods utilize momentum mechanisms to separate task-oriented and distillation gradients, they overlook the inherent conflict between target-class and non-target-class knowledge flows. Furthermore, low-confidence dark knowledge in non-target classes introduces noisy signals that hinder effective knowledge transfer. To address these limitations, we propose DeepKD, a novel training framework that integrates dual-level decoupling with adaptive denoising. First, through theoretical analysis of gradient signal-to-noise ratio (GSNR) characteristics in task-oriented and non-task-oriented knowledge distillation, we design independent momentum updaters for each component to prevent mutual interference. We observe that the optimal momentum coefficients for task-oriented gradient (TOG), target-class gradient (TCG), and non-target-class gradient (NCG) should be positively related to their GSNR. Second, we introduce a dynamic top-k mask (DTM) mechanism that gradually increases K from a small initial value to incorporate more non-target classes as training progresses, following curriculum learning principles. The DTM jointly filters low-confidence logits from both teacher and student models, effectively purifying dark knowledge during early training. Extensive experiments on CIFAR-100, ImageNet, and MS-COCO demonstrate DeepKD's effectiveness. Our code is available at https://github.com/haiduo/DeepKD.
A Self-supervised Learning Method for Raman Spectroscopy based on Masked Autoencoders
Apr 21, 2025



Raman spectroscopy serves as a powerful and reliable tool for analyzing the chemical information of substances. The integration of Raman spectroscopy with deep learning methods enables rapid qualitative and quantitative analysis of materials. Most existing approaches adopt supervised learning methods. Although supervised learning has achieved satisfactory accuracy in spectral analysis, it is still constrained by costly and limited well-annotated spectral datasets for training. When spectral annotation is challenging or the amount of annotated data is insufficient, the performance of supervised learning in spectral material identification declines. In order to address the challenge of feature extraction from unannotated spectra, we propose a self-supervised learning paradigm for Raman Spectroscopy based on a Masked AutoEncoder, termed SMAE. SMAE does not require any spectral annotations during pre-training. By randomly masking and then reconstructing the spectral information, the model learns essential spectral features. The reconstructed spectra exhibit certain denoising properties, improving the signal-to-noise ratio (SNR) by more than twofold. Utilizing the network weights obtained from masked pre-training, SMAE achieves clustering accuracy of over 80% for 30 classes of isolated bacteria in a pathogenic bacterial dataset, demonstrating significant improvements compared to classical unsupervised methods and other state-of-the-art deep clustering methods. After fine-tuning the network with a limited amount of annotated data, SMAE achieves an identification accuracy of 83.90% on the test set, presenting competitive performance against the supervised ResNet (83.40%).
KernelDNA: Dynamic Kernel Sharing via Decoupled Naive Adapters
Mar 30, 2025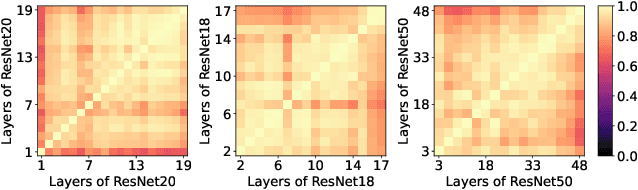
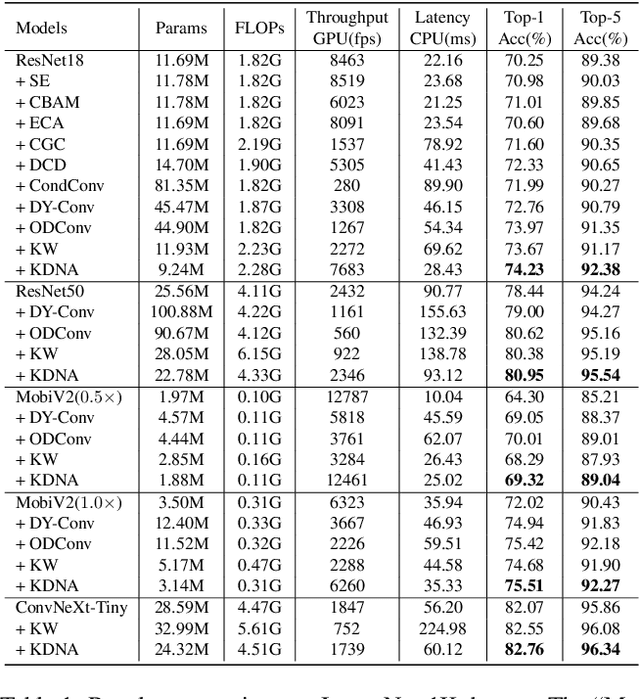
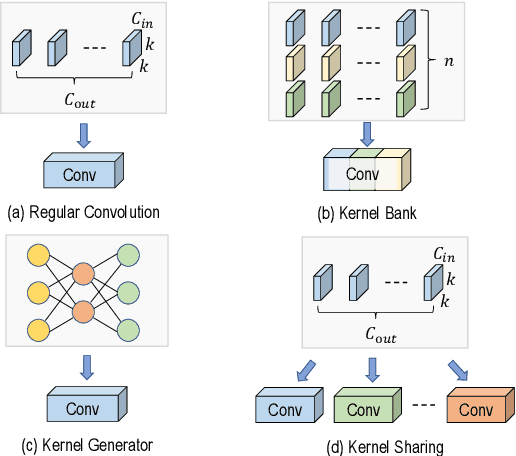
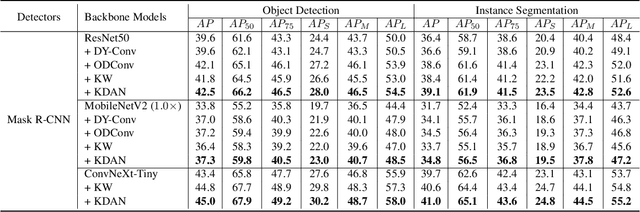
Dynamic convolution enhances model capacity by adaptively combining multiple kernels, yet faces critical trade-offs: prior works either (1) incur significant parameter overhead by scaling kernel numbers linearly, (2) compromise inference speed through complex kernel interactions, or (3) struggle to jointly optimize dynamic attention and static kernels. We also observe that pre-trained Convolutional Neural Networks (CNNs) exhibit inter-layer redundancy akin to that in Large Language Models (LLMs). Specifically, dense convolutional layers can be efficiently replaced by derived ``child" layers generated from a shared ``parent" convolutional kernel through an adapter. To address these limitations and implement the weight-sharing mechanism, we propose a lightweight convolution kernel plug-in, named KernelDNA. It decouples kernel adaptation into input-dependent dynamic routing and pre-trained static modulation, ensuring both parameter efficiency and hardware-friendly inference. Unlike existing dynamic convolutions that expand parameters via multi-kernel ensembles, our method leverages cross-layer weight sharing and adapter-based modulation, enabling dynamic kernel specialization without altering the standard convolution structure. This design preserves the native computational efficiency of standard convolutions while enhancing representation power through input-adaptive kernel adjustments. Experiments on image classification and dense prediction tasks demonstrate that KernelDNA achieves state-of-the-art accuracy-efficiency balance among dynamic convolution variants. Our codes are available at https://github.com/haiduo/KernelDNA.
Partial Convolution Meets Visual Attention
Mar 05, 2025Designing an efficient and effective neural network has remained a prominent topic in computer vision research. Depthwise onvolution (DWConv) is widely used in efficient CNNs or ViTs, but it needs frequent memory access during inference, which leads to low throughput. FasterNet attempts to introduce partial convolution (PConv) as an alternative to DWConv but compromises the accuracy due to underutilized channels. To remedy this shortcoming and consider the redundancy between feature map channels, we introduce a novel Partial visual ATtention mechanism (PAT) that can efficiently combine PConv with visual attention. Our exploration indicates that the partial attention mechanism can completely replace the full attention mechanism and reduce model parameters and FLOPs. Our PAT can derive three types of blocks: Partial Channel-Attention block (PAT_ch), Partial Spatial-Attention block (PAT_sp) and Partial Self-Attention block (PAT_sf). First, PAT_ch integrates the enhanced Gaussian channel attention mechanism to infuse global distribution information into the untouched channels of PConv. Second, we introduce the spatial-wise attention to the MLP layer to further improve model accuracy. Finally, we replace PAT_ch in the last stage with the self-attention mechanism to extend the global receptive field. Building upon PAT, we propose a novel hybrid network family, named PATNet, which achieves superior top-1 accuracy and inference speed compared to FasterNet on ImageNet-1K classification and excel in both detection and segmentation on the COCO dataset. Particularly, our PATNet-T2 achieves 1.3% higher accuracy than FasterNet-T2, while exhibiting 25% higher GPU throughput and 24% lower CPU latency.
Jakiro: Boosting Speculative Decoding with Decoupled Multi-Head via MoE
Feb 10, 2025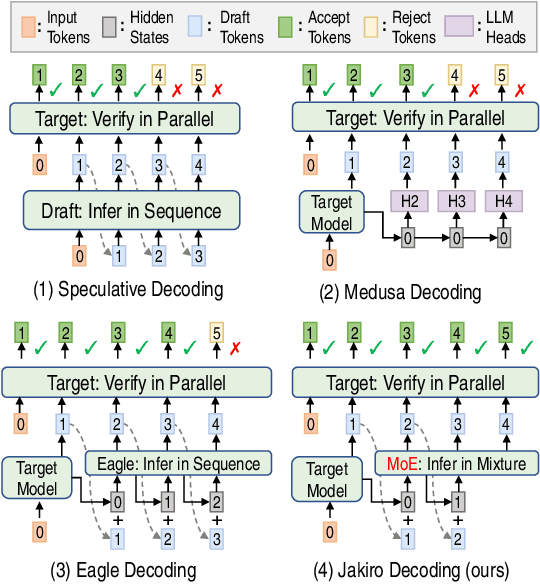
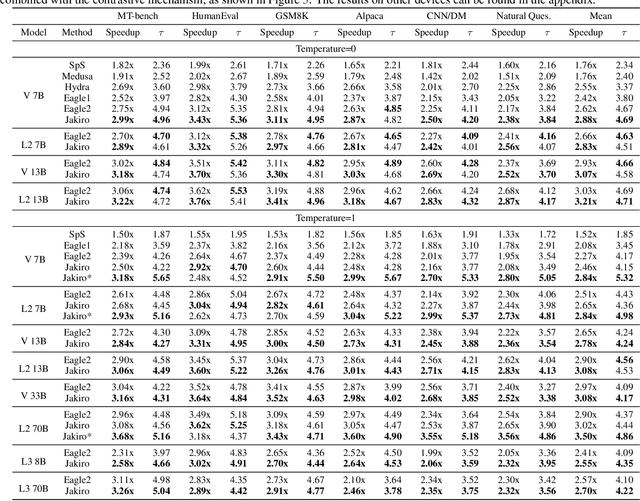
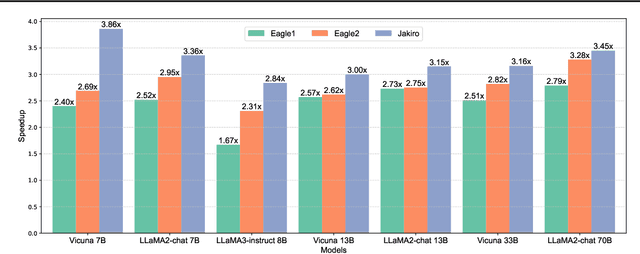
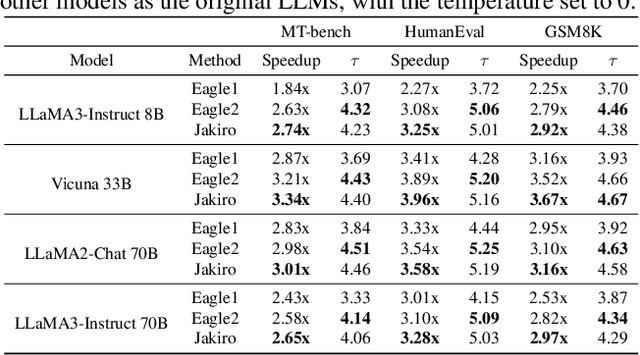
Speculative decoding (SD) accelerates large language model inference by using a smaller draft model to predict multiple tokens, which are then verified in parallel by the larger target model. However, the limited capacity of the draft model often necessitates tree-based sampling to improve prediction accuracy, where multiple candidates are generated at each step. We identify a key limitation in this approach: the candidates at the same step are derived from the same representation, limiting diversity and reducing overall effectiveness. To address this, we propose Jakiro, leveraging Mixture of Experts (MoE), where independent experts generate diverse predictions, effectively decoupling correlations among candidates. Furthermore, we introduce a hybrid inference strategy, combining autoregressive decoding for initial tokens with parallel decoding for subsequent stages, and enhance the latter with contrastive mechanism in features to improve accuracy. Our method significantly boosts prediction accuracy and achieves higher inference speedups. Extensive experiments across diverse models validate the effectiveness and robustness of our approach, establishing a new SOTA in speculative decoding. Our codes are available at https://github.com/haiduo/Jakiro.
Partial Channel Network: Compute Fewer, Perform Better
Feb 03, 2025Designing a module or mechanism that enables a network to maintain low parameters and FLOPs without sacrificing accuracy and throughput remains a challenge. To address this challenge and exploit the redundancy within feature map channels, we propose a new solution: partial channel mechanism (PCM). Specifically, through the split operation, the feature map channels are divided into different parts, with each part corresponding to different operations, such as convolution, attention, pooling, and identity mapping. Based on this assumption, we introduce a novel partial attention convolution (PATConv) that can efficiently combine convolution with visual attention. Our exploration indicates that the PATConv can completely replace both the regular convolution and the regular visual attention while reducing model parameters and FLOPs. Moreover, PATConv can derive three new types of blocks: Partial Channel-Attention block (PAT_ch), Partial Spatial-Attention block (PAT_sp), and Partial Self-Attention block (PAT_sf). In addition, we propose a novel dynamic partial convolution (DPConv) that can adaptively learn the proportion of split channels in different layers to achieve better trade-offs. Building on PATConv and DPConv, we propose a new hybrid network family, named PartialNet, which achieves superior top-1 accuracy and inference speed compared to some SOTA models on ImageNet-1K classification and excels in both detection and segmentation on the COCO dataset. Our code is available at https://github.com/haiduo/PartialNet.
Nearly Lossless Adaptive Bit Switching
Feb 03, 2025



Model quantization is widely applied for compressing and accelerating deep neural networks (DNNs). However, conventional Quantization-Aware Training (QAT) focuses on training DNNs with uniform bit-width. The bit-width settings vary across different hardware and transmission demands, which induces considerable training and storage costs. Hence, the scheme of one-shot joint training multiple precisions is proposed to address this issue. Previous works either store a larger FP32 model to switch between different precision models for higher accuracy or store a smaller INT8 model but compromise accuracy due to using shared quantization parameters. In this paper, we introduce the Double Rounding quantization method, which fully utilizes the quantized representation range to accomplish nearly lossless bit-switching while reducing storage by using the highest integer precision instead of full precision. Furthermore, we observe a competitive interference among different precisions during one-shot joint training, primarily due to inconsistent gradients of quantization scales during backward propagation. To tackle this problem, we propose an Adaptive Learning Rate Scaling (ALRS) technique that dynamically adapts learning rates for various precisions to optimize the training process. Additionally, we extend our Double Rounding to one-shot mixed precision training and develop a Hessian-Aware Stochastic Bit-switching (HASB) strategy. Experimental results on the ImageNet-1K classification demonstrate that our methods have enough advantages to state-of-the-art one-shot joint QAT in both multi-precision and mixed-precision. We also validate the feasibility of our method on detection and segmentation tasks, as well as on LLMs task. Our codes are available at https://github.com/haiduo/Double-Rounding.
AdaBin: Improving Binary Neural Networks with Adaptive Binary Sets
Aug 17, 2022



This paper studies the Binary Neural Networks (BNNs) in which weights and activations are both binarized into 1-bit values, thus greatly reducing the memory usage and computational complexity. Since the modern deep neural networks are of sophisticated design with complex architecture for the accuracy reason, the diversity on distributions of weights and activations is very high. Therefore, the conventional sign function cannot be well used for effectively binarizing full-precision values in BNNs. To this end, we present a simple yet effective approach called AdaBin to adaptively obtain the optimal binary sets $\{b_1, b_2\}$ ($b_1, b_2\in \mathbb{R}$) of weights and activations for each layer instead of a fixed set (i.e., $\{-1, +1\}$). In this way, the proposed method can better fit different distributions and increase the representation ability of binarized features. In practice, we use the center position and distance of 1-bit values to define a new binary quantization function. For the weights, we propose an equalization method to align the symmetrical center of binary distribution to real-valued distribution, and minimize the Kullback-Leibler divergence of them. Meanwhile, we introduce a gradient-based optimization method to get these two parameters for activations, which are jointly trained in an end-to-end manner. Experimental results on benchmark models and datasets demonstrate that the proposed AdaBin is able to achieve state-of-the-art performance. For instance, we obtain a 66.4\% Top-1 accuracy on the ImageNet using ResNet-18 architecture, and a 69.4 mAP on PASCAL VOC using SSD300.
Error Loss Networks
Jun 08, 2021



A novel model called error loss network (ELN) is proposed to build an error loss function for supervised learning. The ELN is in structure similar to a radial basis function (RBF) neural network, but its input is an error sample and output is a loss corresponding to that error sample. That means the nonlinear input-output mapper of ELN creates an error loss function. The proposed ELN provides a unified model for a large class of error loss functions, which includes some information theoretic learning (ITL) loss functions as special cases. The activation function, weight parameters and network size of the ELN can be predetermined or learned from the error samples. On this basis, we propose a new machine learning paradigm where the learning process is divided into two stages: first, learning a loss function using an ELN; second, using the learned loss function to continue to perform the learning. Experimental results are presented to demonstrate the desirable performance of the new method.