 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Convolution Meets Visual Attention
Mar 05, 2025Designing an efficient and effective neural network has remained a prominent topic in computer vision research. Depthwise onvolution (DWConv) is widely used in efficient CNNs or ViTs, but it needs frequent memory access during inference, which leads to low throughput. FasterNet attempts to introduce partial convolution (PConv) as an alternative to DWConv but compromises the accuracy due to underutilized channels. To remedy this shortcoming and consider the redundancy between feature map channels, we introduce a novel Partial visual ATtention mechanism (PAT) that can efficiently combine PConv with visual attention. Our exploration indicates that the partial attention mechanism can completely replace the full attention mechanism and reduce model parameters and FLOPs. Our PAT can derive three types of blocks: Partial Channel-Attention block (PAT_ch), Partial Spatial-Attention block (PAT_sp) and Partial Self-Attention block (PAT_sf). First, PAT_ch integrates the enhanced Gaussian channel attention mechanism to infuse global distribution information into the untouched channels of PConv. Second, we introduce the spatial-wise attention to the MLP layer to further improve model accuracy. Finally, we replace PAT_ch in the last stage with the self-attention mechanism to extend the global receptive field. Building upon PAT, we propose a novel hybrid network family, named PATNet, which achieves superior top-1 accuracy and inference speed compared to FasterNet on ImageNet-1K classification and excel in both detection and segmentation on the COCO dataset. Particularly, our PATNet-T2 achieves 1.3% higher accuracy than FasterNet-T2, while exhibiting 25% higher GPU throughput and 24% lower CPU latency.
Jakiro: Boosting Speculative Decoding with Decoupled Multi-Head via MoE
Feb 10, 2025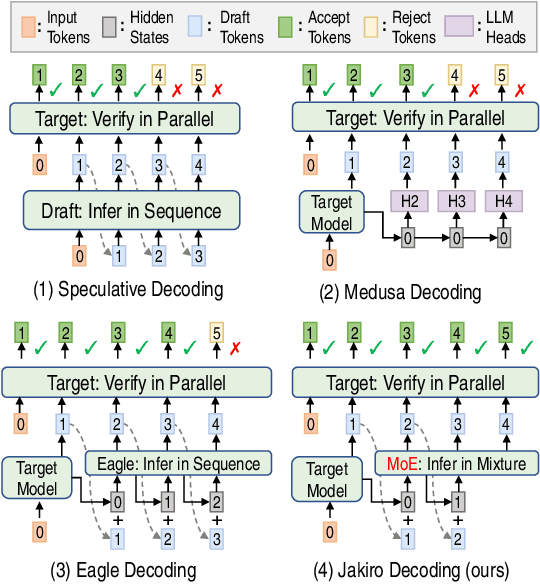
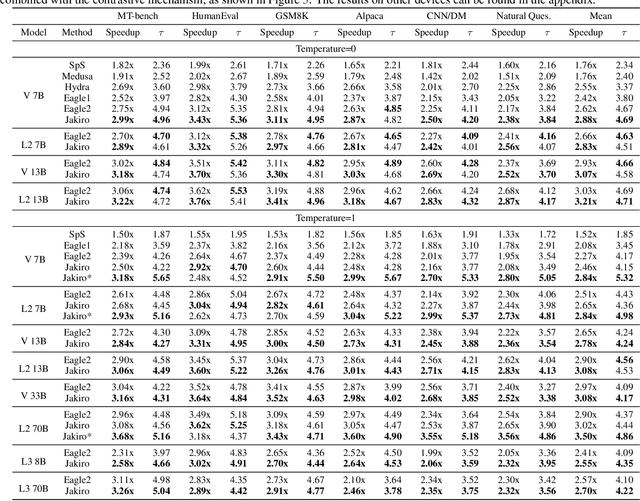
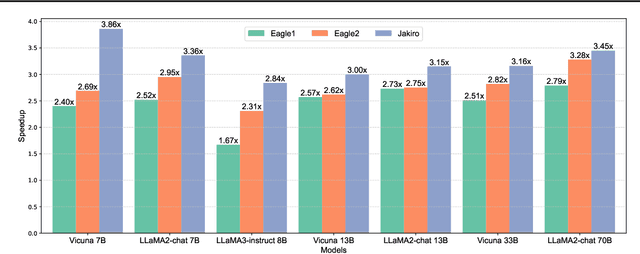
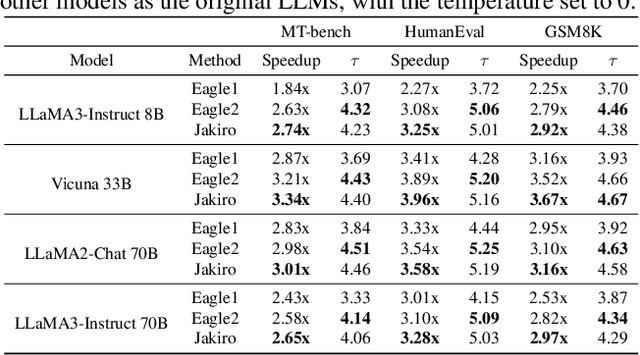
Speculative decoding (SD) accelerates large language model inference by using a smaller draft model to predict multiple tokens, which are then verified in parallel by the larger target model. However, the limited capacity of the draft model often necessitates tree-based sampling to improve prediction accuracy, where multiple candidates are generated at each step. We identify a key limitation in this approach: the candidates at the same step are derived from the same representation, limiting diversity and reducing overall effectiveness. To address this, we propose Jakiro, leveraging Mixture of Experts (MoE), where independent experts generate diverse predictions, effectively decoupling correlations among candidates. Furthermore, we introduce a hybrid inference strategy, combining autoregressive decoding for initial tokens with parallel decoding for subsequent stages, and enhance the latter with contrastive mechanism in features to improve accuracy. Our method significantly boosts prediction accuracy and achieves higher inference speedups. Extensive experiments across diverse models validate the effectiveness and robustness of our approach, establishing a new SOTA in speculative decoding. Our codes are available at https://github.com/haiduo/Jakiro.
FTP: A Fine-grained Token-wise Pruner for Large Language Models via Token Routing
Dec 16, 2024Recently, large language models (LLMs) have demonstrated superior performance across various tasks by adhering to scaling laws, which significantly increase model size. However, the huge computation overhead during inference hinders the deployment in industrial applications. Many works leverage traditional compression approaches to boost model inference, but these always introduce additional training costs to restore the performance and the pruning results typically show noticeable performance drops compared to the original model when aiming for a specific level of acceleration. To address these issues, we propose a fine-grained token-wise pruning approach for the LLMs, which presents a learnable router to adaptively identify the less important tokens and skip them across model blocks to reduce computational cost during inference. To construct the router efficiently, we present a search-based sparsity scheduler for pruning sparsity allocation, a trainable router combined with our proposed four low-dimensional factors as input and three proposed losses. We conduct extensive experiments across different benchmarks on different LLMs to demonstrate the superiority of our method. Our approach achieves state-of-the-art (SOTA) pruning results, surpassing other existing pruning methods. For instance, our method outperforms BlockPruner and ShortGPT by approximately 10 points on both LLaMA2-7B and Qwen1.5-7B in accuracy retention at comparable token sparsity levels.