 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLATTE: Forecasting Peer Anchored Preference Trajectories for Personalized LLM Generation
May 26, 2026Personalized generation with frozen large language models requires a conditioning signal that is both compact and current. Existing personalization methods typically retrieve or summarize user histories in text, or compress them into static latent profiles and soft prompts. These approaches are efficient, but they treat a user's past behavior as an aggregate profile and therefore mix stable identity, recent drift, and item content in the same representation. We propose LAtent Trajectory Tracking and Extrapolation (LATTE), a framework that represents personalization as forecasting a peer anchored relative preference state. For each historical session, LATTE subtracts a time masked baseline formed from comparable users who responded to the same item, producing a state that measures how the target user differs from peers under a shared item context. A lightweight sequence predictor then forecasts the next state in this trajectory, and a State to Token Bridge injects the forecast into a frozen instruction tuned LLM through a single anchored soft token. We provide a latent factor analysis showing when peer anchoring cancels shared item variation and why temporal forecasting trades off stale averages against noisy recent states. Experiments on Amazon Reviews 2023 and MemoryCD show that LATTE consistently outperforms retrieval, summary memory, static latent profiles, difference aware latent profiles, and soft prompt compression baselines. On Amazon Reviews 2023, LATTE improves average ROUGE-L from 0.219 for a static latent profile and 0.245 for the strongest added latent compression baseline to 0.259. Additional pairwise comparisons and diagnostic analyses suggest that the improvement is mainly due to forecasting user-specific trajectory information, rather than merely adding a soft prompt interface.
Beyond the Target: From Imitation to Collaboration in Speculative Decoding
May 24, 2026Speculative decoding (SPD) accelerates large language model (LLM) inference by letting a smaller draft model propose multiple future tokens that are verified in parallel by a larger target model. The dominant SPD paradigm treats the target model as the sole reliable teacher, accepting a draft token only when it exactly matches the target prediction. This design implicitly assumes that the target is always the better choice at every position. In practice, this assumption does not hold. Although the draft is the weaker model overall, it is not uniformly inferior at the token level. In a meaningful fraction of cases where draft and target disagree, the draft's choice is the one that leads to the correct final answer. Inspired by this, we introduce \textbf{Collaborative Speculative Decoding (CoSpec)}, a generalization of SPD that no longer treats the target model as the sole token-level authority. CoSpec trains an arbitration policy via reinforcement learning to decide whether to accept tokens from the draft or target model, selectively accepting draft tokens at mismatches when doing so is likely to yield a correct final answer. Experimental results show that CoSpec maintains substantial speedups while surpassing target-only performance. By shifting the emphasis from imitation to collaboration, CoSpec suggests a new perspective on speculative decoding.
AcademiClaw: When Students Set Challenges for AI Agents
May 04, 2026Benchmarks within the OpenClaw ecosystem have thus far evaluated exclusively assistant-level tasks, leaving the academic-level capabilities of OpenClaw largely unexamined. We introduce AcademiClaw, a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively. Curated from 230 student-submitted candidates through rigorous expert review, the final task set spans 25+ professional domains, ranging from olympiad-level mathematics and linguistics problems to GPU-intensive reinforcement learning and full-stack system debugging, with 16 tasks requiring CUDA GPU execution. Each task executes in an isolated Docker sandbox and is scored on task completion by multi-dimensional rubrics combining six complementary techniques, with an independent five-category safety audit providing additional behavioral analysis. Experiments on six frontier models show that even the best achieves only a 55\% pass rate. Further analysis uncovers sharp capability boundaries across task domains, divergent behavioral strategies among models, and a disconnect between token consumption and output quality, providing fine-grained diagnostic signals beyond what aggregate metrics reveal. We hope that AcademiClaw and its open-sourced data and code can serve as a useful resource for the OpenClaw community, driving progress toward agents that are more capable and versatile across the full breadth of real-world academic demands. All data and code are available at https://github.com/GAIR-NLP/AcademiClaw.
Well Begun is Half Done: Training-Free and Model-Agnostic Semantically Guaranteed User Representation Initialization for Multimodal Recommendation
Apr 16, 2026Recent advancements in multimodal recommendations, which leverage diverse modality information to mitigate data sparsity and improve recommendation accuracy, have gained significant attention. However, existing multimodal recommendations overlook the critical role of user representation initialization. Unlike items, which are naturally associated with rich modality information, users lack such inherent information. Consequently, item representations initialized based on meaningful modality information and user representations initialized randomly exhibit a significant semantic gap. To this end, we propose a Semantically Guaranteed User Representation Initialization (SG-URInit). SG-URInit constructs the initial representation for each user by integrating both the modality features of the items they have interacted with and the global features of their corresponding clusters. SG-URInit enables the initialization of semantically enriched user representations that effectively capture both local (item-level) and global (cluster-level) semantics. Our SG-URInit is training-free and model-agnostic, meaning it can be seamlessly integrated into existing multimodal recommendation models without incurring any additional computational overhead during training. Extensive experiments on multiple real-world datasets demonstrate that incorporating SG-URInit into advanced multimodal recommendation models significantly enhances recommendation performance. Furthermore, the results show that SG-URInit can further alleviate the item cold-start problem and also accelerate model convergence, making it an efficient and practical solution for multimodal recommendations.
CAMMSR: Category-Guided Attentive Mixture of Experts for Multimodal Sequential Recommendation
Mar 04, 2026The explosion of multimedia data in information-rich environments has intensified the challenges of personalized content discovery, positioning recommendation systems as an essential form of passive data management. Multimodal sequential recommendation, which leverages diverse item information such as text and images, has shown great promise in enriching item representations and deepening the understanding of user interests. However, most existing models rely on heuristic fusion strategies that fail to capture the dynamic and context-sensitive nature of user-modal interactions. In real-world scenarios, user preferences for modalities vary not only across individuals but also within the same user across different items or categories. Moreover, the synergistic effects between modalities-where combined signals trigger user interest in ways isolated modalities cannot-remain largely underexplored. To this end, we propose CAMMSR, a Category-guided Attentive Mixture of Experts model for Multimodal Sequential Recommendation. At its core, CAMMSR introduces a category-guided attentive mixture of experts (CAMoE) module, which learns specialized item representations from multiple perspectives and explicitly models inter-modal synergies. This component dynamically allocates modality weights guided by an auxiliary category prediction task, enabling adaptive fusion of multimodal signals. Additionally, we design a modality swap contrastive learning task to enhance cross-modal representation alignment through sequence-level augmentation. Extensive experiments on four public datasets demonstrate that CAMMSR consistently outperforms state-of-the-art baselines, validating its effectiveness in achieving adaptive, synergistic, and user-centric multimodal sequential recommendation.
Learning and Editing Universal Graph Prompt Tuning via Reinforcement Learning
Dec 09, 2025Early graph prompt tuning approaches relied on task-specific designs for Graph Neural Networks (GNNs), limiting their adaptability across diverse pre-training strategies. In contrast, another promising line of research has investigated universal graph prompt tuning, which operates directly in the input graph's feature space and builds a theoretical foundation that universal graph prompt tuning can theoretically achieve an equivalent effect of any prompting function, eliminating dependence on specific pre-training strategies. Recent works propose selective node-based graph prompt tuning to pursue more ideal prompts. However, we argue that selective node-based graph prompt tuning inevitably compromises the theoretical foundation of universal graph prompt tuning. In this paper, we strengthen the theoretical foundation of universal graph prompt tuning by introducing stricter constraints, demonstrating that adding prompts to all nodes is a necessary condition for achieving the universality of graph prompts. To this end, we propose a novel model and paradigm, Learning and Editing Universal GrAph Prompt Tuning (LEAP), which preserves the theoretical foundation of universal graph prompt tuning while pursuing more ideal prompts. Specifically, we first build the basic universal graph prompts to preserve the theoretical foundation and then employ actor-critic reinforcement learning to select nodes and edit prompts. Extensive experiments on graph- and node-level tasks across various pre-training strategies in both full-shot and few-shot scenarios show that LEAP consistently outperforms fine-tuning and other prompt-based approaches.
VI-MMRec: Similarity-Aware Training Cost-free Virtual User-Item Interactions for Multimodal Recommendation
Dec 09, 2025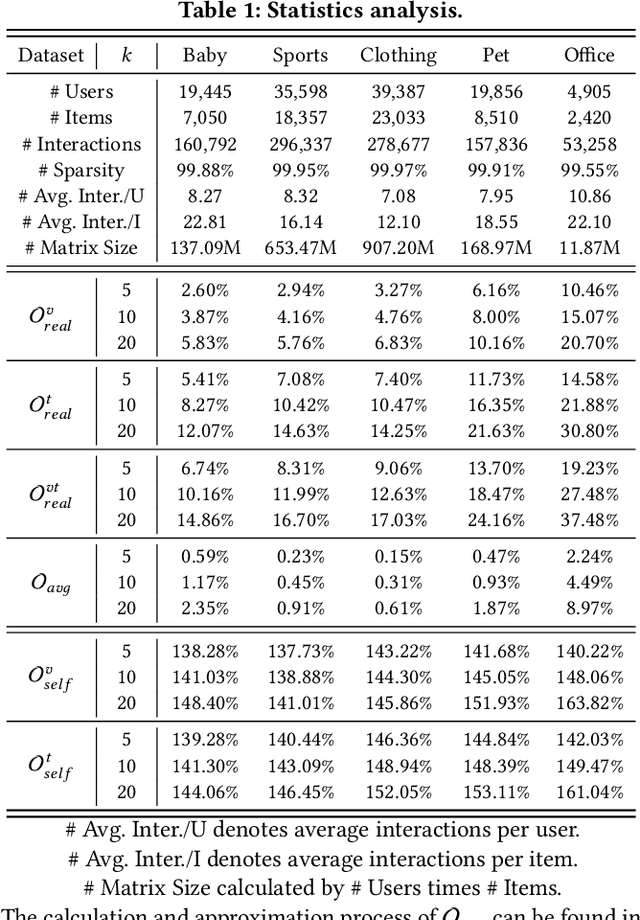
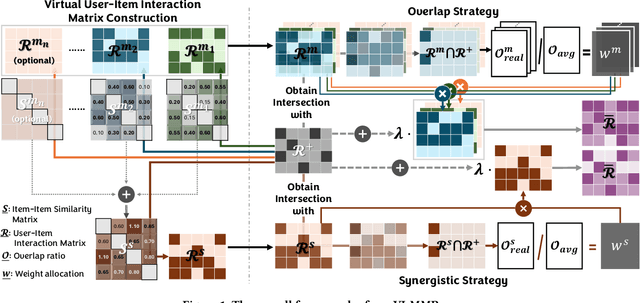
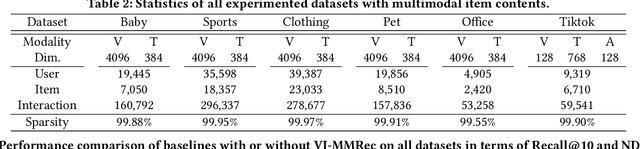
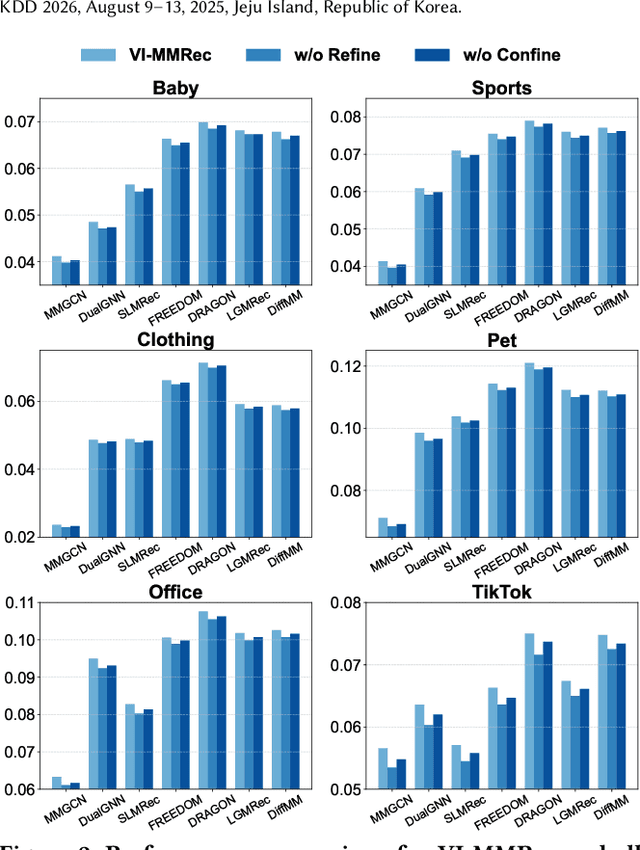
Although existing multimodal recommendation models have shown promising performance, their effectiveness continues to be limited by the pervasive data sparsity problem. This problem arises because users typically interact with only a small subset of available items, leading existing models to arbitrarily treat unobserved items as negative samples. To this end, we propose VI-MMRec, a model-agnostic and training cost-free framework that enriches sparse user-item interactions via similarity-aware virtual user-item interactions. These virtual interactions are constructed based on modality-specific feature similarities of user-interacted items. Specifically, VI-MMRec introduces two different strategies: (1) Overlay, which independently aggregates modality-specific similarities to preserve modality-specific user preferences, and (2) Synergistic, which holistically fuses cross-modal similarities to capture complementary user preferences. To ensure high-quality augmentation, we design a statistically informed weight allocation mechanism that adaptively assigns weights to virtual user-item interactions based on dataset-specific modality relevance. As a plug-and-play framework, VI-MMRec seamlessly integrates with existing models to enhance their performance without modifying their core architecture. Its flexibility allows it to be easily incorporated into various existing models, maximizing performance with minimal implementation effort. Moreover, VI-MMRec introduces no additional overhead during training, making it significantly advantageous for practical deployment. Comprehensive experiments conducted on six real-world datasets using seven state-of-the-art multimodal recommendation models validate the effectiveness of our VI-MMRec.
Multi-modal Dynamic Proxy Learning for Personalized Multiple Clustering
Nov 10, 2025Multiple clustering aims to discover diverse latent structures from different perspectives, yet existing methods generate exhaustive clusterings without discerning user interest, necessitating laborious manual screening. Current multi-modal solutions suffer from static semantic rigidity: predefined candidate words fail to adapt to dataset-specific concepts, and fixed fusion strategies ignore evolving feature interactions. To overcome these limitations, we propose Multi-DProxy, a novel multi-modal dynamic proxy learning framework that leverages cross-modal alignment through learnable textual proxies. Multi-DProxy introduces 1) gated cross-modal fusion that synthesizes discriminative joint representations by adaptively modeling feature interactions. 2) dual-constraint proxy optimization where user interest constraints enforce semantic consistency with domain concepts while concept constraints employ hard example mining to enhance cluster discrimination. 3) dynamic candidate management that refines textual proxies through iterative clustering feedback. Therefore, Multi-DProxy not only effectively captures a user's interest through proxies but also enables the identification of relevant clusterings with greater precision. Extensive experiments demonstrate state-of-the-art performance with significant improvements over existing methods across a broad set of multi-clustering benchmarks.
NLGCL: Naturally Existing Neighbor Layers Graph Contrastive Learning for Recommendation
Jul 10, 2025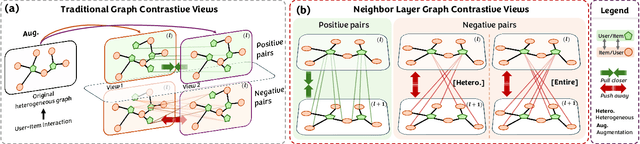
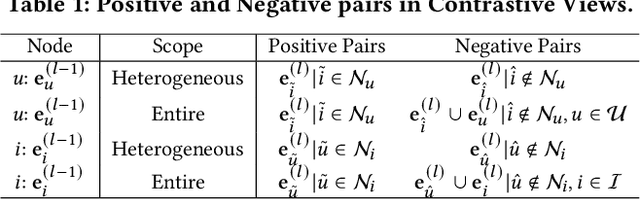
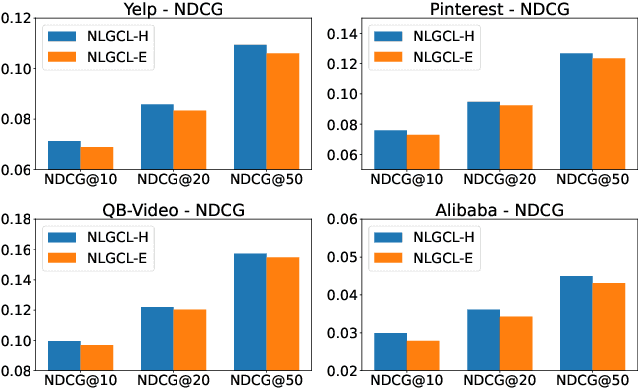
Graph Neural Networks (GNNs) are widely used in collaborative filtering to capture high-order user-item relationships. To address the data sparsity problem in recommendation systems, Graph Contrastive Learning (GCL) has emerged as a promising paradigm that maximizes mutual information between contrastive views. However, existing GCL methods rely on augmentation techniques that introduce semantically irrelevant noise and incur significant computational and storage costs, limiting effectiveness and efficiency. To overcome these challenges, we propose NLGCL, a novel contrastive learning framework that leverages naturally contrastive views between neighbor layers within GNNs. By treating each node and its neighbors in the next layer as positive pairs, and other nodes as negatives, NLGCL avoids augmentation-based noise while preserving semantic relevance. This paradigm eliminates costly view construction and storage, making it computationally efficient and practical for real-world scenarios. Extensive experiments on four public datasets demonstrate that NLGCL outperforms state-of-the-art baselines in effectiveness and efficiency.
RealFactBench: A Benchmark for Evaluating Large Language Models in Real-World Fact-Checking
Jun 14, 2025Large Language Models (LLMs) hold significant potential for advancing fact-checking by leveraging their capabilities in reasoning, evidence retrieval, and explanation generation. However, existing benchmarks fail to comprehensively evaluate LLMs and Multimodal Large Language Models (MLLMs) in realistic misinformation scenarios. To bridge this gap, we introduce RealFactBench, a comprehensive benchmark designed to assess the fact-checking capabilities of LLMs and MLLMs across diverse real-world tasks, including Knowledge Validation, Rumor Detection, and Event Verification. RealFactBench consists of 6K high-quality claims drawn from authoritative sources, encompassing multimodal content and diverse domains. Our evaluation framework further introduces the Unknown Rate (UnR) metric, enabling a more nuanced assessment of models' ability to handle uncertainty and balance between over-conservatism and over-confidence. Extensive experiments on 7 representative LLMs and 4 MLLMs reveal their limitations in real-world fact-checking and offer valuable insights for further research. RealFactBench is publicly available at https://github.com/kalendsyang/RealFactBench.git.