 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWell Begun is Half Done: Training-Free and Model-Agnostic Semantically Guaranteed User Representation Initialization for Multimodal Recommendation
Apr 16, 2026Recent advancements in multimodal recommendations, which leverage diverse modality information to mitigate data sparsity and improve recommendation accuracy, have gained significant attention. However, existing multimodal recommendations overlook the critical role of user representation initialization. Unlike items, which are naturally associated with rich modality information, users lack such inherent information. Consequently, item representations initialized based on meaningful modality information and user representations initialized randomly exhibit a significant semantic gap. To this end, we propose a Semantically Guaranteed User Representation Initialization (SG-URInit). SG-URInit constructs the initial representation for each user by integrating both the modality features of the items they have interacted with and the global features of their corresponding clusters. SG-URInit enables the initialization of semantically enriched user representations that effectively capture both local (item-level) and global (cluster-level) semantics. Our SG-URInit is training-free and model-agnostic, meaning it can be seamlessly integrated into existing multimodal recommendation models without incurring any additional computational overhead during training. Extensive experiments on multiple real-world datasets demonstrate that incorporating SG-URInit into advanced multimodal recommendation models significantly enhances recommendation performance. Furthermore, the results show that SG-URInit can further alleviate the item cold-start problem and also accelerate model convergence, making it an efficient and practical solution for multimodal recommendations.
Specification-Driven Generation and Evaluation of Discrete-Event World Models via the DEVS Formalism
Mar 04, 2026World models are essential for planning and evaluation in agentic systems, yet existing approaches lie at two extremes: hand-engineered simulators that offer consistency and reproducibility but are costly to adapt, and implicit neural models that are flexible but difficult to constrain, verify, and debug over long horizons. We seek a principled middle ground that combines the reliability of explicit simulators with the flexibility of learned models, allowing world models to be adapted during online execution. By targeting a broad class of environments whose dynamics are governed by the ordering, timing, and causality of discrete events, such as queueing and service operations, embodied task planning, and message-mediated multi-agent coordination, we advocate explicit, executable discrete-event world models synthesized directly from natural-language specifications. Our approach adopts the DEVS formalism and introduces a staged LLM-based generation pipeline that separates structural inference of component interactions from component-level event and timing logic. To evaluate generated models without a unique ground truth, simulators emit structured event traces that are validated against specification-derived temporal and semantic constraints, enabling reproducible verification and localized diagnostics. Together, these contributions produce world models that are consistent over long-horizon rollouts, verifiable from observable behavior, and efficient to synthesize on demand during online execution.
CAMMSR: Category-Guided Attentive Mixture of Experts for Multimodal Sequential Recommendation
Mar 04, 2026The explosion of multimedia data in information-rich environments has intensified the challenges of personalized content discovery, positioning recommendation systems as an essential form of passive data management. Multimodal sequential recommendation, which leverages diverse item information such as text and images, has shown great promise in enriching item representations and deepening the understanding of user interests. However, most existing models rely on heuristic fusion strategies that fail to capture the dynamic and context-sensitive nature of user-modal interactions. In real-world scenarios, user preferences for modalities vary not only across individuals but also within the same user across different items or categories. Moreover, the synergistic effects between modalities-where combined signals trigger user interest in ways isolated modalities cannot-remain largely underexplored. To this end, we propose CAMMSR, a Category-guided Attentive Mixture of Experts model for Multimodal Sequential Recommendation. At its core, CAMMSR introduces a category-guided attentive mixture of experts (CAMoE) module, which learns specialized item representations from multiple perspectives and explicitly models inter-modal synergies. This component dynamically allocates modality weights guided by an auxiliary category prediction task, enabling adaptive fusion of multimodal signals. Additionally, we design a modality swap contrastive learning task to enhance cross-modal representation alignment through sequence-level augmentation. Extensive experiments on four public datasets demonstrate that CAMMSR consistently outperforms state-of-the-art baselines, validating its effectiveness in achieving adaptive, synergistic, and user-centric multimodal sequential recommendation.
Learning and Editing Universal Graph Prompt Tuning via Reinforcement Learning
Dec 09, 2025Early graph prompt tuning approaches relied on task-specific designs for Graph Neural Networks (GNNs), limiting their adaptability across diverse pre-training strategies. In contrast, another promising line of research has investigated universal graph prompt tuning, which operates directly in the input graph's feature space and builds a theoretical foundation that universal graph prompt tuning can theoretically achieve an equivalent effect of any prompting function, eliminating dependence on specific pre-training strategies. Recent works propose selective node-based graph prompt tuning to pursue more ideal prompts. However, we argue that selective node-based graph prompt tuning inevitably compromises the theoretical foundation of universal graph prompt tuning. In this paper, we strengthen the theoretical foundation of universal graph prompt tuning by introducing stricter constraints, demonstrating that adding prompts to all nodes is a necessary condition for achieving the universality of graph prompts. To this end, we propose a novel model and paradigm, Learning and Editing Universal GrAph Prompt Tuning (LEAP), which preserves the theoretical foundation of universal graph prompt tuning while pursuing more ideal prompts. Specifically, we first build the basic universal graph prompts to preserve the theoretical foundation and then employ actor-critic reinforcement learning to select nodes and edit prompts. Extensive experiments on graph- and node-level tasks across various pre-training strategies in both full-shot and few-shot scenarios show that LEAP consistently outperforms fine-tuning and other prompt-based approaches.
VI-MMRec: Similarity-Aware Training Cost-free Virtual User-Item Interactions for Multimodal Recommendation
Dec 09, 2025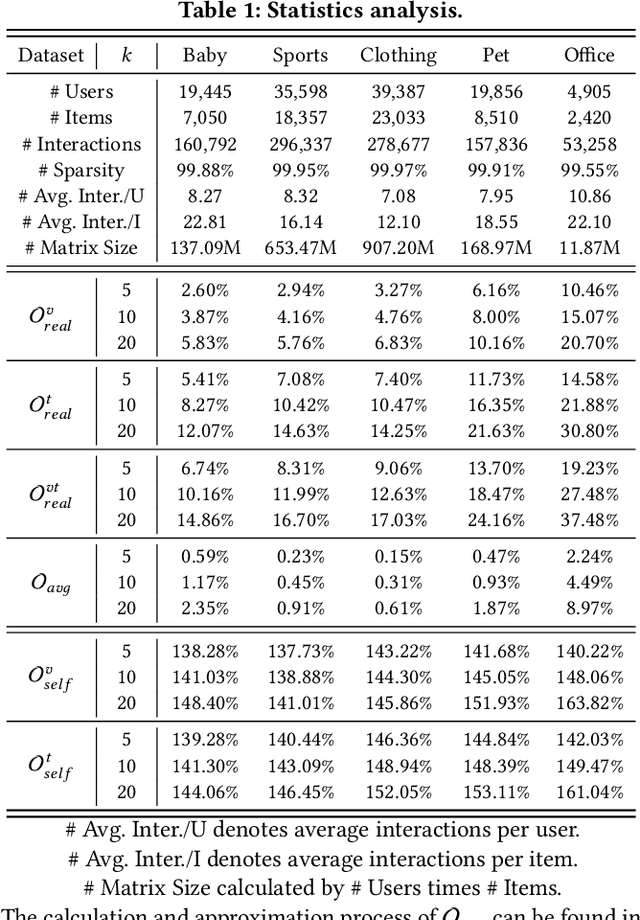
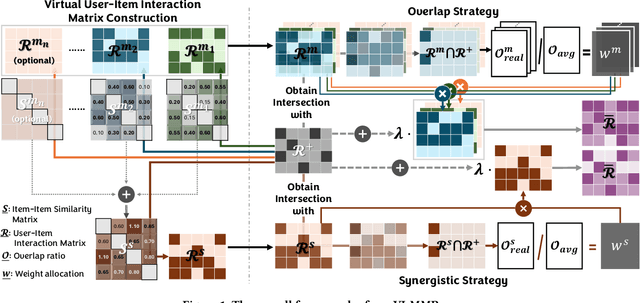
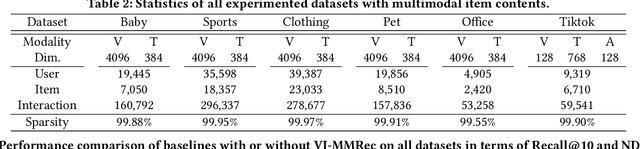
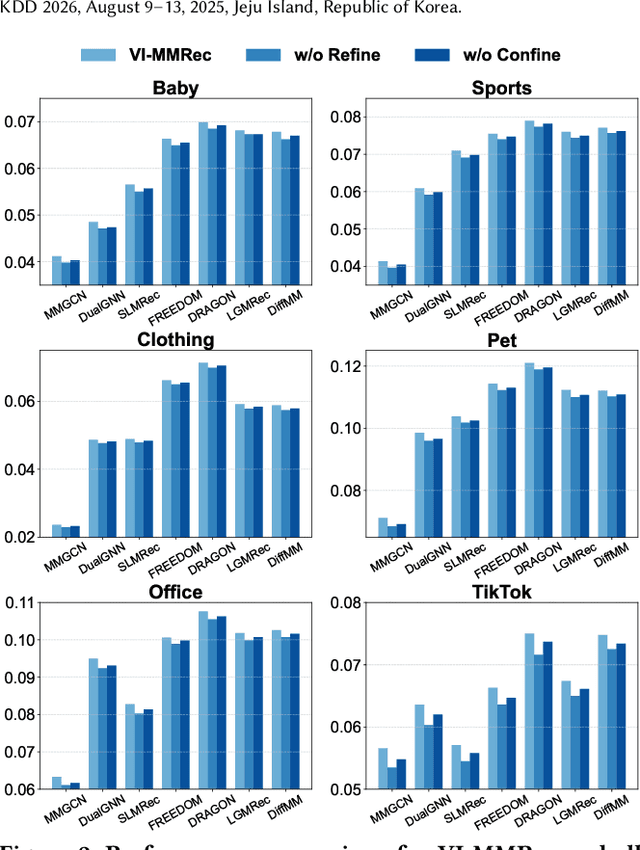
Although existing multimodal recommendation models have shown promising performance, their effectiveness continues to be limited by the pervasive data sparsity problem. This problem arises because users typically interact with only a small subset of available items, leading existing models to arbitrarily treat unobserved items as negative samples. To this end, we propose VI-MMRec, a model-agnostic and training cost-free framework that enriches sparse user-item interactions via similarity-aware virtual user-item interactions. These virtual interactions are constructed based on modality-specific feature similarities of user-interacted items. Specifically, VI-MMRec introduces two different strategies: (1) Overlay, which independently aggregates modality-specific similarities to preserve modality-specific user preferences, and (2) Synergistic, which holistically fuses cross-modal similarities to capture complementary user preferences. To ensure high-quality augmentation, we design a statistically informed weight allocation mechanism that adaptively assigns weights to virtual user-item interactions based on dataset-specific modality relevance. As a plug-and-play framework, VI-MMRec seamlessly integrates with existing models to enhance their performance without modifying their core architecture. Its flexibility allows it to be easily incorporated into various existing models, maximizing performance with minimal implementation effort. Moreover, VI-MMRec introduces no additional overhead during training, making it significantly advantageous for practical deployment. Comprehensive experiments conducted on six real-world datasets using seven state-of-the-art multimodal recommendation models validate the effectiveness of our VI-MMRec.
Multi-modal Dynamic Proxy Learning for Personalized Multiple Clustering
Nov 10, 2025Multiple clustering aims to discover diverse latent structures from different perspectives, yet existing methods generate exhaustive clusterings without discerning user interest, necessitating laborious manual screening. Current multi-modal solutions suffer from static semantic rigidity: predefined candidate words fail to adapt to dataset-specific concepts, and fixed fusion strategies ignore evolving feature interactions. To overcome these limitations, we propose Multi-DProxy, a novel multi-modal dynamic proxy learning framework that leverages cross-modal alignment through learnable textual proxies. Multi-DProxy introduces 1) gated cross-modal fusion that synthesizes discriminative joint representations by adaptively modeling feature interactions. 2) dual-constraint proxy optimization where user interest constraints enforce semantic consistency with domain concepts while concept constraints employ hard example mining to enhance cluster discrimination. 3) dynamic candidate management that refines textual proxies through iterative clustering feedback. Therefore, Multi-DProxy not only effectively captures a user's interest through proxies but also enables the identification of relevant clusterings with greater precision. Extensive experiments demonstrate state-of-the-art performance with significant improvements over existing methods across a broad set of multi-clustering benchmarks.
Think Socially via Cognitive Reasoning
Sep 26, 2025LLMs trained for logical reasoning excel at step-by-step deduction to reach verifiable answers. However, this paradigm is ill-suited for navigating social situations, which induce an interpretive process of analyzing ambiguous cues that rarely yield a definitive outcome. To bridge this gap, we introduce Cognitive Reasoning, a paradigm modeled on human social cognition. It formulates the interpretive process into a structured cognitive flow of interconnected cognitive units (e.g., observation or attribution), which combine adaptively to enable effective social thinking and responses. We then propose CogFlow, a complete framework that instills this capability in LLMs. CogFlow first curates a dataset of cognitive flows by simulating the associative and progressive nature of human thought via tree-structured planning. After instilling the basic cognitive reasoning capability via supervised fine-tuning, CogFlow adopts reinforcement learning to enable the model to improve itself via trial and error, guided by a multi-objective reward that optimizes both cognitive flow and response quality. Extensive experiments show that CogFlow effectively enhances the social cognitive capabilities of LLMs, and even humans, leading to more effective social decision-making.
NLGCL: Naturally Existing Neighbor Layers Graph Contrastive Learning for Recommendation
Jul 10, 2025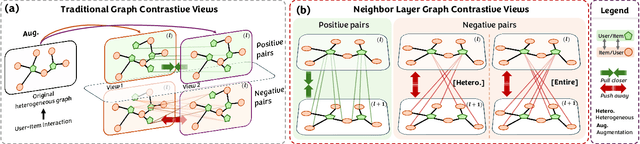
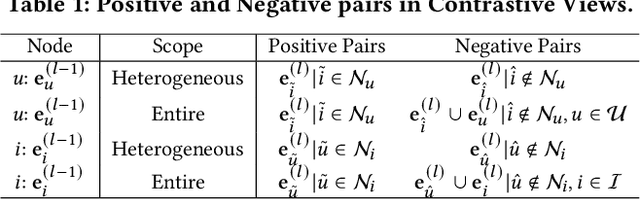
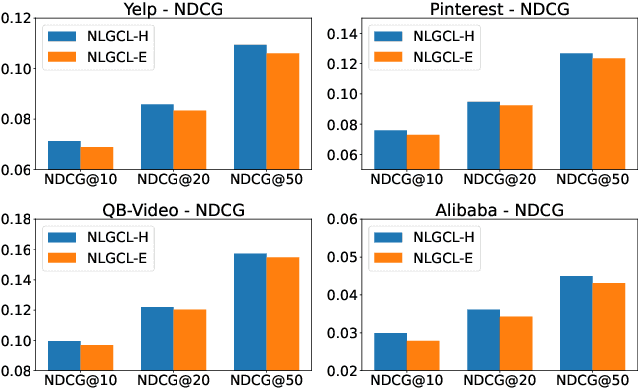
Graph Neural Networks (GNNs) are widely used in collaborative filtering to capture high-order user-item relationships. To address the data sparsity problem in recommendation systems, Graph Contrastive Learning (GCL) has emerged as a promising paradigm that maximizes mutual information between contrastive views. However, existing GCL methods rely on augmentation techniques that introduce semantically irrelevant noise and incur significant computational and storage costs, limiting effectiveness and efficiency. To overcome these challenges, we propose NLGCL, a novel contrastive learning framework that leverages naturally contrastive views between neighbor layers within GNNs. By treating each node and its neighbors in the next layer as positive pairs, and other nodes as negatives, NLGCL avoids augmentation-based noise while preserving semantic relevance. This paradigm eliminates costly view construction and storage, making it computationally efficient and practical for real-world scenarios. Extensive experiments on four public datasets demonstrate that NLGCL outperforms state-of-the-art baselines in effectiveness and efficiency.
MDVT: Enhancing Multimodal Recommendation with Model-Agnostic Multimodal-Driven Virtual Triplets
May 22, 2025The data sparsity problem significantly hinders the performance of recommender systems, as traditional models rely on limited historical interactions to learn user preferences and item properties. While incorporating multimodal information can explicitly represent these preferences and properties, existing works often use it only as side information, failing to fully leverage its potential. In this paper, we propose MDVT, a model-agnostic approach that constructs multimodal-driven virtual triplets to provide valuable supervision signals, effectively mitigating the data sparsity problem in multimodal recommendation systems. To ensure high-quality virtual triplets, we introduce three tailored warm-up threshold strategies: static, dynamic, and hybrid. The static warm-up threshold strategy exhaustively searches for the optimal number of warm-up epochs but is time-consuming and computationally intensive. The dynamic warm-up threshold strategy adjusts the warm-up period based on loss trends, improving efficiency but potentially missing optimal performance. The hybrid strategy combines both, using the dynamic strategy to find the approximate optimal number of warm-up epochs and then refining it with the static strategy in a narrow hyper-parameter space. Once the warm-up threshold is satisfied, the virtual triplets are used for joint model optimization by our enhanced pair-wise loss function without causing significant gradient skew. Extensive experiments on multiple real-world datasets demonstrate that integrating MDVT into advanced multimodal recommendation models effectively alleviates the data sparsity problem and improves recommendation performance, particularly in sparse data scenarios.
Squeeze and Excitation: A Weighted Graph Contrastive Learning for Collaborative Filtering
Apr 06, 2025



Contrastive Learning (CL) has recently emerged as a powerful technique in recommendation systems, particularly for its capability to harness self-supervised signals from perturbed views to mitigate the persistent challenge of data sparsity. The process of constructing perturbed views of the user-item bipartite graph and performing contrastive learning between perturbed views in a graph convolutional network (GCN) is called graph contrastive learning (GCL), which aims to enhance the robustness of representation learning. Although existing GCL-based models are effective, the weight assignment method for perturbed views has not been fully explored. A critical problem in existing GCL-based models is the irrational allocation of feature attention. This problem limits the model's ability to effectively leverage crucial features, resulting in suboptimal performance. To address this, we propose a Weighted Graph Contrastive Learning framework (WeightedGCL). Specifically, WeightedGCL applies a robust perturbation strategy, which perturbs only the view of the final GCN layer. In addition, WeightedGCL incorporates a squeeze and excitation network (SENet) to dynamically weight the features of the perturbed views. Our WeightedGCL strengthens the model's focus on crucial features and reduces the impact of less relevant information. Extensive experiments on widely used datasets demonstrate that our WeightedGCL achieves significant accuracy improvements compared to competitive baselines.