 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMENTOR: Multi-level Self-supervised Learning for Multimodal Recommendation
Paper and Code
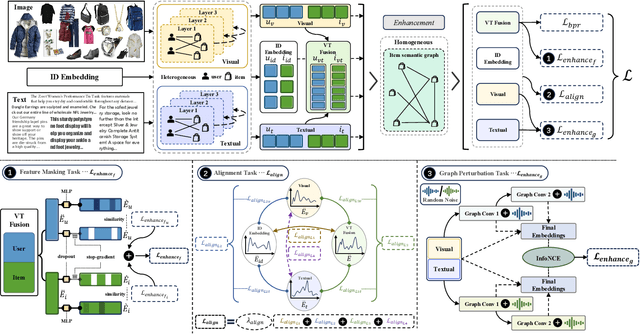
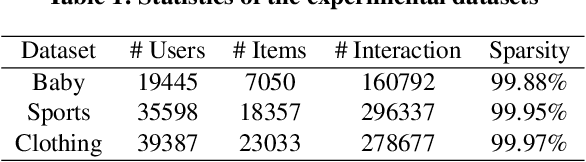
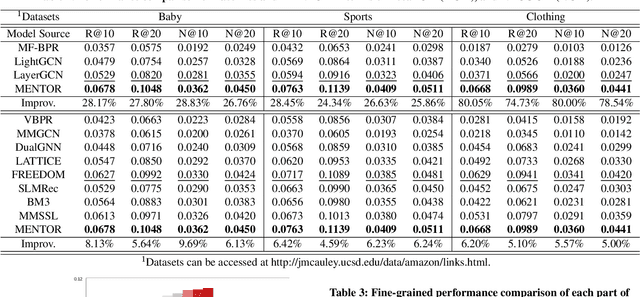
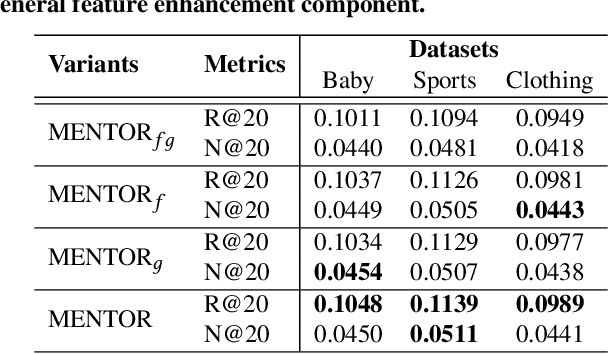
With the increasing multimedia information, multimodal recommendation has received extensive attention. It utilizes multimodal information to alleviate the data sparsity problem in recommendation systems, thus improving recommendation accuracy. However, the reliance on labeled data severely limits the performance of multimodal recommendation models. Recently, self-supervised learning has been used in multimodal recommendations to mitigate the label sparsity problem. Nevertheless, the state-of-the-art methods cannot avoid the modality noise when aligning multimodal information due to the large differences in the distributions of different modalities. To this end, we propose a Multi-level sElf-supervised learNing for mulTimOdal Recommendation (MENTOR) method to address the label sparsity problem and the modality alignment problem. Specifically, MENTOR first enhances the specific features of each modality using the graph convolutional network (GCN) and fuses the visual and textual modalities. It then enhances the item representation via the item semantic graph for all modalities, including the fused modality. Then, it introduces two multilevel self-supervised tasks: the multilevel cross-modal alignment task and the general feature enhancement task. The multilevel cross-modal alignment task aligns each modality under the guidance of the ID embedding from multiple levels while maintaining the historical interaction information. The general feature enhancement task enhances the general feature from both the graph and feature perspectives to improve the robustness of our model. Extensive experiments on three publicly available datasets demonstrate the effectiveness of our method. Our code is publicly available at https://github.com/Jinfeng-Xu/MENTOR.