 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Guided Sequence-Based Generative Framework for Acoustic Metamaterial Inverse Design
Jun 08, 2026Acoustic metamaterial (AMM) inverse design is particularly challenging for broadband target responses due to acoustic dispersion: a structure that matches the desired response at one frequency may deviate at others, and modifying geometry to improve one sub-band often perturbs neighboring sub-bands. Yet existing broadband inverse-design approaches are either constrained by predefined templates, or rely on image representations that fail to preserve the geometric precision and structural connectivity required by acoustic structures. We present MetaSeq, a physics-guided, sequence-based generative framework for acoustic metamaterial inverse design. At its core, MetaSeq introduces a language that represents each AMM as a structured sequence, rather than as a pixel grid or fixed template. This representation preserves precise geometry, explicitly encodes connectivity, and casts inverse design as a sequence-to-sequence task from target response to structure sequence. MetaSeq further constructs a balanced, high-fidelity dataset with efficient calibration and complexity-based sampling. To address the one-to-many nature of inverse design, MetaSeq combines supervised pretraining with reinforcement learning fine-tuning guided by a physics-based solver and validity checker. Extensive evaluations against COMSOL and five baselines show that MetaSeq reduces response error by 45% over the best baseline.
Tractogram foundation model
Jun 03, 2026Diffusion MRI (dMRI) tractography is the only noninvasive approach for mapping white-matter pathways in the living human brain. It represents each brain as a tractogram: a large, unordered set of three-dimensional streamlines that includes information about both local streamline geometry and whole-brain anatomical organization. This structure makes tractograms a natural but challenging target for representation learning. Existing methods treat streamline classification and subject-level prediction as separate problems: streamline classifiers focus on geometric patterns, whereas subject-level prediction often depends on hand-crafted features. As a result, current methods do not learn reusable representations that connect streamline anatomy with whole-brain inter-subject variation. Here we introduce TractFM, a tractogram foundation model that learns reusable representations directly from whole-brain streamline sets. TractFM combines a local streamline encoder with a permutation-equivariant tractogram encoder, allowing all streamlines from a subject to be contextualized jointly in a single forward pass. Pretraining on dense anatomical tract parcellation, i.e., assigning anatomical labels to individual streamlines, yields two complementary representations: contextualized streamline-level embeddings for tract parcellation and compact subject-level descriptors for downstream prediction of subject phenotypes. Across three tractography algorithms and five dMRI datasets, TractFM transfers to both streamline-level and subject-level tasks. Its frozen representations achieve accurate tract parcellation and predict age and sex across independent datasets. These results show that whole-brain geometric context, learned once, can generalize across tractography pipelines, datasets, and prediction tasks.
GaMi: Geometry-Agnostic Material Identification via Cross-Modal Subtractive Disentanglement
May 29, 2026Non-contact material identification enables adaptive interaction for embodied intelligence yet faces challenges from geometry-induced variations (e.g., orientation, shape, distance) and single-modality ambiguities. In this paper, we present GaMi, a multimodal material identification system integrating mmWave and acoustic sensing to robustly operate under unconstrained geometric conditions. By leveraging the insight of shared geometric consistency between co-located bimodal sensors, GaMi employs an intra-sample cross-modal subtractive disentanglement framework. By semantically aligning modalities and subtracting the shared geometric context, it isolates intrinsic material features. Furthermore, GaMi incorporates inter-sample contrastive learning to correct the residual interference caused by cross-modal misalignment. Additionally, a pairing-based adaptation strategy between two modalities enables few-shot generalization across devices. Extensive evaluations on 20 materials show that GaMi achieves 95.2% accuracy, outperforming single-modality baselines across unseen geometric conditions.
TractoRC: A Unified Probabilistic Learning Framework for Joint Tractography Registration and Clustering
Mar 11, 2026Diffusion MRI tractography enables in vivo reconstruction of white matter (WM) pathways. Two key tasks in tractography analysis include: 1) tractogram registration that aligns streamlines across individuals, and 2) streamline clustering that groups streamlines into compact fiber bundles. Although both tasks share the goal of capturing geometrically similar structures to characterize consistent WM organization, they are typically performed independently. In this work, we propose TractoRC, a unified probabilistic framework that jointly performs tractogram registration and streamline clustering within a single optimization scheme, enabling the two tasks to leverage complementary information. TractoRC learns a latent embedding space for streamline points, which serves as a shared representation for both tasks. Within this space, both tasks are formulated as probabilistic inference over structural representations: registration learns the distribution of anatomical landmarks as probabilistic keypoints to align tractograms across subjects, and clustering learns streamline structural prototypes that capture geometric similarity to form coherent streamline clusters. To support effective learning of this shared space, we introduce a transformation-equivariant self-supervised strategy to learn geometry-aware and transformation-invariant embeddings. Experiments demonstrate that jointly optimizing registration and clustering significantly improves performance in both tasks over state-of-the-art methods that treat them independently. Code will be made publicly available at https://github.com/yishengpoxiao/TractoRC .
CAMMSR: Category-Guided Attentive Mixture of Experts for Multimodal Sequential Recommendation
Mar 04, 2026The explosion of multimedia data in information-rich environments has intensified the challenges of personalized content discovery, positioning recommendation systems as an essential form of passive data management. Multimodal sequential recommendation, which leverages diverse item information such as text and images, has shown great promise in enriching item representations and deepening the understanding of user interests. However, most existing models rely on heuristic fusion strategies that fail to capture the dynamic and context-sensitive nature of user-modal interactions. In real-world scenarios, user preferences for modalities vary not only across individuals but also within the same user across different items or categories. Moreover, the synergistic effects between modalities-where combined signals trigger user interest in ways isolated modalities cannot-remain largely underexplored. To this end, we propose CAMMSR, a Category-guided Attentive Mixture of Experts model for Multimodal Sequential Recommendation. At its core, CAMMSR introduces a category-guided attentive mixture of experts (CAMoE) module, which learns specialized item representations from multiple perspectives and explicitly models inter-modal synergies. This component dynamically allocates modality weights guided by an auxiliary category prediction task, enabling adaptive fusion of multimodal signals. Additionally, we design a modality swap contrastive learning task to enhance cross-modal representation alignment through sequence-level augmentation. Extensive experiments on four public datasets demonstrate that CAMMSR consistently outperforms state-of-the-art baselines, validating its effectiveness in achieving adaptive, synergistic, and user-centric multimodal sequential recommendation.
BrainSegNet: A Novel Framework for Whole-Brain MRI Parcellation Enhanced by Large Models
Jan 14, 2026Whole-brain parcellation from MRI is a critical yet challenging task due to the complexity of subdividing the brain into numerous small, irregular shaped regions. Traditionally, template-registration methods were used, but recent advances have shifted to deep learning for faster workflows. While large models like the Segment Anything Model (SAM) offer transferable feature representations, they are not tailored for the high precision required in brain parcellation. To address this, we propose BrainSegNet, a novel framework that adapts SAM for accurate whole-brain parcellation into 95 regions. We enhance SAM by integrating U-Net skip connections and specialized modules into its encoder and decoder, enabling fine-grained anatomical precision. Key components include a hybrid encoder combining U-Net skip connections with SAM's transformer blocks, a multi-scale attention decoder with pyramid pooling for varying-sized structures, and a boundary refinement module to sharpen edges. Experimental results on the Human Connectome Project (HCP) dataset demonstrate that BrainSegNet outperforms several state-of-the-art methods, achieving higher accuracy and robustness in complex, multi-label parcellation.
Cross-Population White Matter Atlas Creation for Concurrent Mapping of Brain Connections in Neonates and Adults with Diffusion MRI Tractography
Dec 23, 2025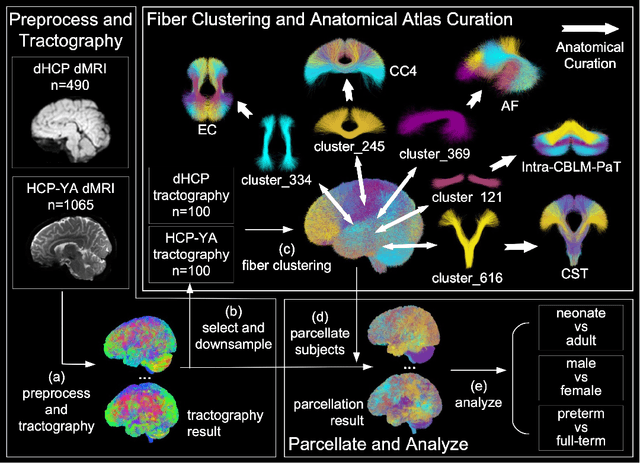
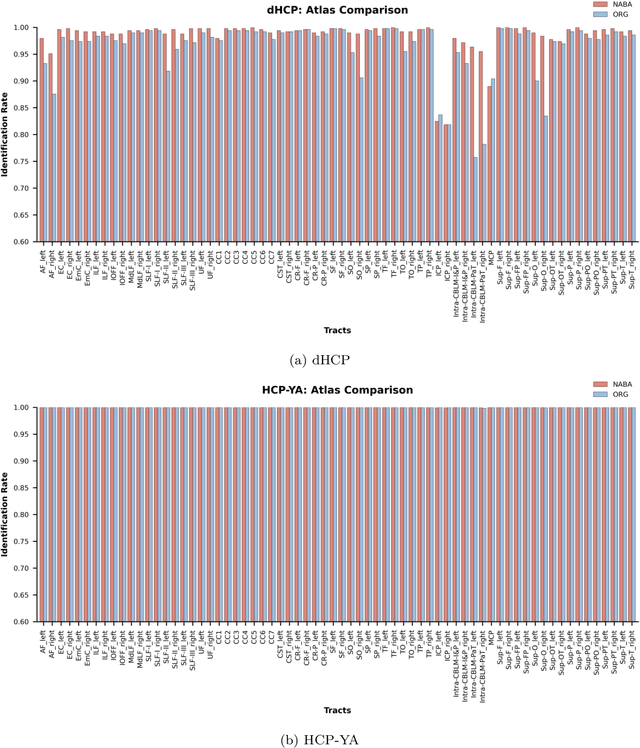
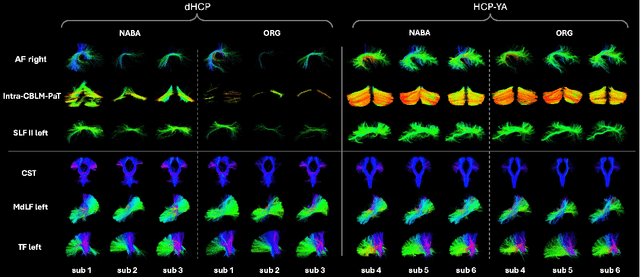
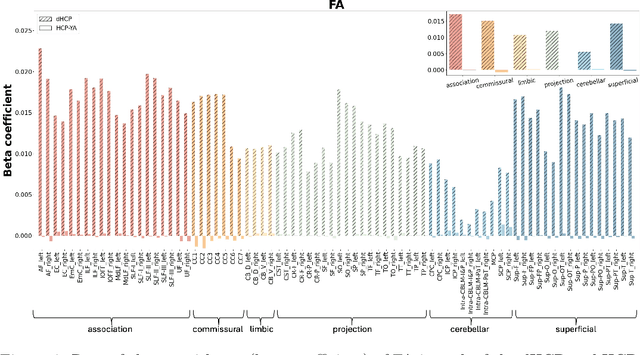
Comparing white matter (WM) connections between adults and neonates using diffusion MRI (dMRI) can advance our understanding of typical brain development and potential biomarkers for neurological disorders. However, existing WM atlases are population-specific (adult or neonatal) and reside in separate spaces, preventing direct cross-population comparisons. A unified WM atlas spanning both neonates and adults is still lacking. In this study, we propose a neonatal/adult brain atlas (NABA), a WM tractography atlas built from dMRI data of both neonates and adults. NABA is constructed using a robust, data-driven fiber clustering pipeline, enabling group-wise WM atlasing across populations despite substantial anatomical variability. The atlas provides a standardized template for WM parcellation, allowing direct comparison of WM tracts between neonates and adults. Using NABA, we conduct four analyses: (1) evaluating the feasibility of joint WM mapping across populations, (2) characterizing WM development across neonatal ages relative to adults, (3) assessing sex-related differences in neonatal WM development, and (4) examining the effects of preterm birth. Our results show that NABA robustly identifies WM tracts in both populations. We observe rapid fractional anisotropy (FA) development in long-range association tracts, including the arcuate fasciculus and superior longitudinal fasciculus II, whereas intra-cerebellar tracts develop more slowly. Neonatal females exhibit faster overall FA development than males. Although preterm neonates show lower overall FA development rates, they demonstrate relatively higher FA growth in specific tracts, including the corticospinal tract, corona radiata-pontine pathway, and intracerebellar tracts. These findings demonstrate that NABA is a useful tool for investigating WM development across neonates and adults.
Learning and Editing Universal Graph Prompt Tuning via Reinforcement Learning
Dec 09, 2025Early graph prompt tuning approaches relied on task-specific designs for Graph Neural Networks (GNNs), limiting their adaptability across diverse pre-training strategies. In contrast, another promising line of research has investigated universal graph prompt tuning, which operates directly in the input graph's feature space and builds a theoretical foundation that universal graph prompt tuning can theoretically achieve an equivalent effect of any prompting function, eliminating dependence on specific pre-training strategies. Recent works propose selective node-based graph prompt tuning to pursue more ideal prompts. However, we argue that selective node-based graph prompt tuning inevitably compromises the theoretical foundation of universal graph prompt tuning. In this paper, we strengthen the theoretical foundation of universal graph prompt tuning by introducing stricter constraints, demonstrating that adding prompts to all nodes is a necessary condition for achieving the universality of graph prompts. To this end, we propose a novel model and paradigm, Learning and Editing Universal GrAph Prompt Tuning (LEAP), which preserves the theoretical foundation of universal graph prompt tuning while pursuing more ideal prompts. Specifically, we first build the basic universal graph prompts to preserve the theoretical foundation and then employ actor-critic reinforcement learning to select nodes and edit prompts. Extensive experiments on graph- and node-level tasks across various pre-training strategies in both full-shot and few-shot scenarios show that LEAP consistently outperforms fine-tuning and other prompt-based approaches.
VI-MMRec: Similarity-Aware Training Cost-free Virtual User-Item Interactions for Multimodal Recommendation
Dec 09, 2025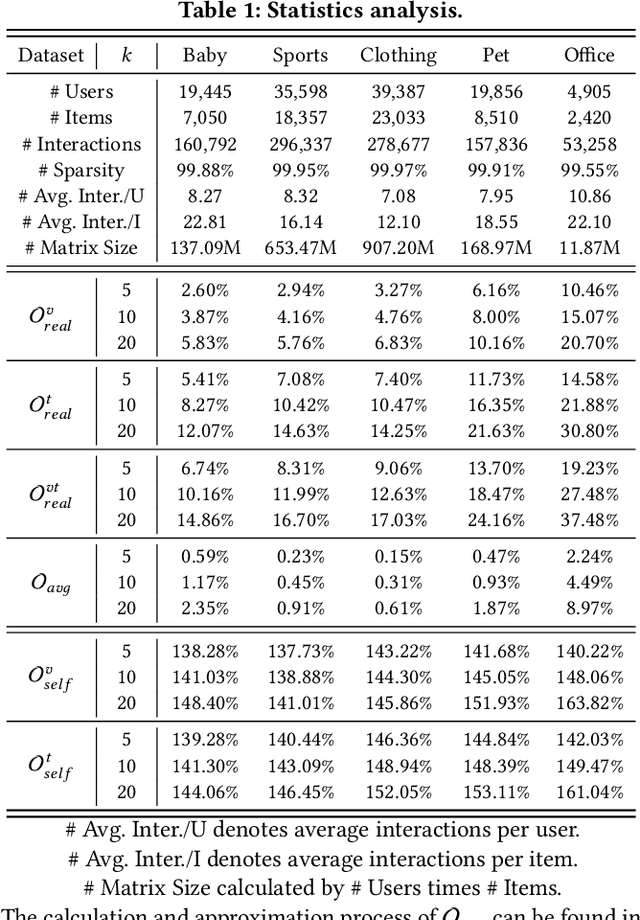
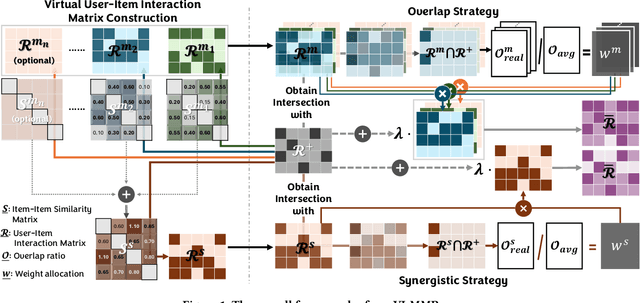
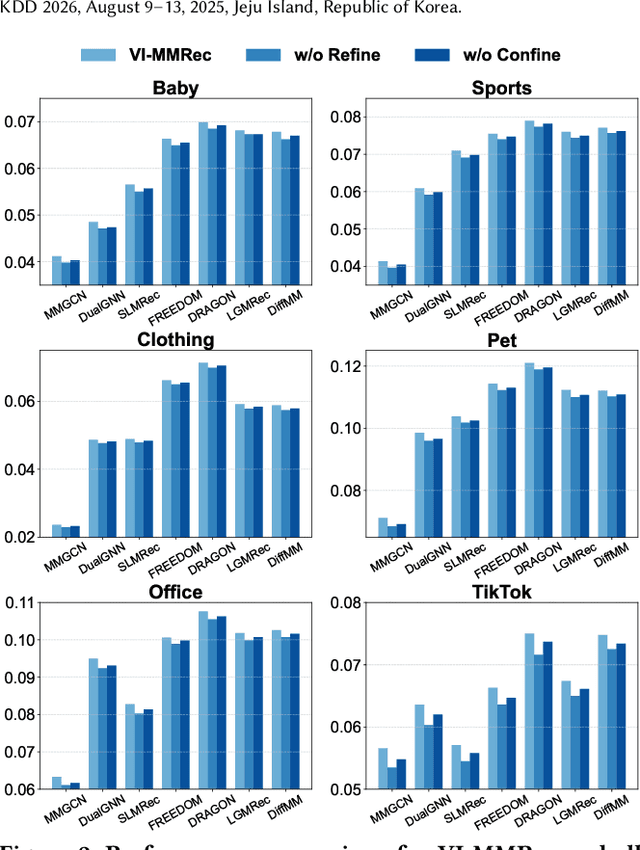
Although existing multimodal recommendation models have shown promising performance, their effectiveness continues to be limited by the pervasive data sparsity problem. This problem arises because users typically interact with only a small subset of available items, leading existing models to arbitrarily treat unobserved items as negative samples. To this end, we propose VI-MMRec, a model-agnostic and training cost-free framework that enriches sparse user-item interactions via similarity-aware virtual user-item interactions. These virtual interactions are constructed based on modality-specific feature similarities of user-interacted items. Specifically, VI-MMRec introduces two different strategies: (1) Overlay, which independently aggregates modality-specific similarities to preserve modality-specific user preferences, and (2) Synergistic, which holistically fuses cross-modal similarities to capture complementary user preferences. To ensure high-quality augmentation, we design a statistically informed weight allocation mechanism that adaptively assigns weights to virtual user-item interactions based on dataset-specific modality relevance. As a plug-and-play framework, VI-MMRec seamlessly integrates with existing models to enhance their performance without modifying their core architecture. Its flexibility allows it to be easily incorporated into various existing models, maximizing performance with minimal implementation effort. Moreover, VI-MMRec introduces no additional overhead during training, making it significantly advantageous for practical deployment. Comprehensive experiments conducted on six real-world datasets using seven state-of-the-art multimodal recommendation models validate the effectiveness of our VI-MMRec.
DDTracking: A Deep Generative Framework for Diffusion MRI Tractography with Streamline Local-Global Spatiotemporal Modeling
Aug 06, 2025This paper presents DDTracking, a novel deep generative framework for diffusion MRI tractography that formulates streamline propagation as a conditional denoising diffusion process. In DDTracking, we introduce a dual-pathway encoding network that jointly models local spatial encoding (capturing fine-scale structural details at each streamline point) and global temporal dependencies (ensuring long-range consistency across the entire streamline). Furthermore, we design a conditional diffusion model module, which leverages the learned local and global embeddings to predict streamline propagation orientations for tractography in an end-to-end trainable manner. We conduct a comprehensive evaluation across diverse, independently acquired dMRI datasets, including both synthetic and clinical data. Experiments on two well-established benchmarks with ground truth (ISMRM Challenge and TractoInferno) demonstrate that DDTracking largely outperforms current state-of-the-art tractography methods. Furthermore, our results highlight DDTracking's strong generalizability across heterogeneous datasets, spanning varying health conditions, age groups, imaging protocols, and scanner types. Collectively, DDTracking offers anatomically plausible and robust tractography, presenting a scalable, adaptable, and end-to-end learnable solution for broad dMRI applications. Code is available at: https://github.com/yishengpoxiao/DDtracking.git