 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multimodal Transformer for InSAR-based ground deformation forecasting with cross-site generalization across Europe
Dec 30, 2025Near-real-time regional-scale monitoring of ground deformation is increasingly required to support urban planning, critical infrastructure management, and natural hazard mitigation. While Interferometric Synthetic Aperture Radar (InSAR) and continental-scale services such as the European Ground Motion Service (EGMS) provide dense observations of past motion, predicting the next observation remains challenging due to the superposition of long-term trends, seasonal cycles, and occasional abrupt discontinuities (e.g., co-seismic steps), together with strong spatial heterogeneity. In this study we propose a multimodal patch-based Transformer for single-step, fixed-interval next-epoch nowcasting of displacement maps from EGMS time series (resampled to a 64x64 grid over 100 km x 100 km tiles). The model ingests recent displacement snapshots together with (i) static kinematic indicators (mean velocity, acceleration, seasonal amplitude) computed in a leakage-safe manner from the training window only, and (ii) harmonic day-of-year encodings. On the eastern Ireland tile (E32N34), the STGCN is strongest in the displacement-only setting, whereas the multimodal Transformer clearly outperforms CNN-LSTM, CNN-LSTM+Attn, and multimodal STGCN when all models receive the same multimodal inputs, achieving RMSE = 0.90 mm and $R^2$ = 0.97 on the test set with the best threshold accuracies.
Segregation and Context Aggregation Network for Real-time Cloud Segmentation
Apr 19, 2025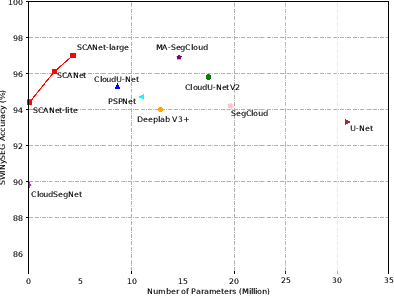
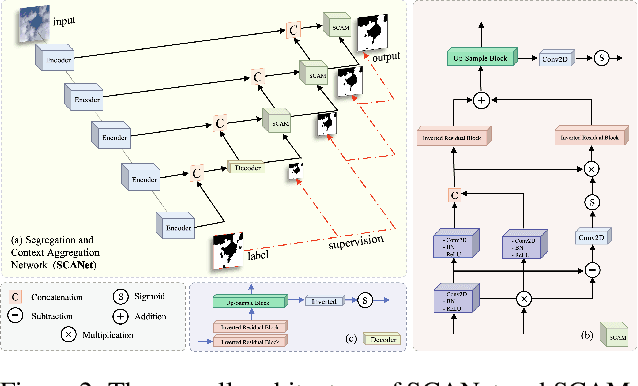
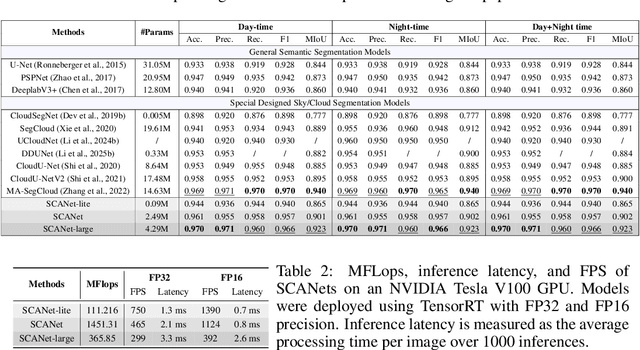

Cloud segmentation from intensity images is a pivotal task in atmospheric science and computer vision, aiding weather forecasting and climate analysis. Ground-based sky/cloud segmentation extracts clouds from images for further feature analysis. Existing methods struggle to balance segmentation accuracy and computational efficiency, limiting real-world deployment on edge devices, so we introduce SCANet, a novel lightweight cloud segmentation model featuring Segregation and Context Aggregation Module (SCAM), which refines rough segmentation maps into weighted sky and cloud features processed separately. SCANet achieves state-of-the-art performance while drastically reducing computational complexity. SCANet-large (4.29M) achieves comparable accuracy to state-of-the-art methods with 70.9% fewer parameters. Meanwhile, SCANet-lite (90K) delivers 1390 fps in FP16, surpassing real-time standards. Additionally, we propose an efficient pre-training strategy that enhances performance even without ImageNet pre-training.
TrafficKAN-GCN: Graph Convolutional-based Kolmogorov-Arnold Network for Traffic Flow Optimization
Mar 05, 2025Urban traffic optimization is critical for improving transportation efficiency and alleviating congestion, particularly in large-scale dynamic networks. Traditional methods, such as Dijkstra's and Floyd's algorithms, provide effective solutions in static settings, but they struggle with the spatial-temporal complexity of real-world traffic flows. In this work, we propose TrafficKAN-GCN, a hybrid deep learning framework combining Kolmogorov-Arnold Networks (KAN) with Graph Convolutional Networks (GCN), designed to enhance urban traffic flow optimization. By integrating KAN's adaptive nonlinear function approximation with GCN's spatial graph learning capabilities, TrafficKAN-GCN captures both complex traffic patterns and topological dependencies. We evaluate the proposed framework using real-world traffic data from the Baltimore Metropolitan area. Compared with baseline models such as MLP-GCN, standard GCN, and Transformer-based approaches, TrafficKAN-GCN achieves competitive prediction accuracy while demonstrating improved robustness in handling noisy and irregular traffic data. Our experiments further highlight the framework's ability to redistribute traffic flow, mitigate congestion, and adapt to disruptive events, such as the Francis Scott Key Bridge collapse. This study contributes to the growing body of work on hybrid graph learning for intelligent transportation systems, highlighting the potential of combining KAN and GCN for real-time traffic optimization. Future work will focus on reducing computational overhead and integrating Transformer-based temporal modeling for enhanced long-term traffic prediction. The proposed TrafficKAN-GCN framework offers a promising direction for data-driven urban mobility management, balancing predictive accuracy, robustness, and computational efficiency.
RAINER: A Robust Ensemble Learning Grid Search-Tuned Framework for Rainfall Patterns Prediction
Jan 28, 2025



Rainfall prediction remains a persistent challenge due to the highly nonlinear and complex nature of meteorological data. Existing approaches lack systematic utilization of grid search for optimal hyperparameter tuning, relying instead on heuristic or manual selection, frequently resulting in sub-optimal results. Additionally, these methods rarely incorporate newly constructed meteorological features such as differences between temperature and humidity to capture critical weather dynamics. Furthermore, there is a lack of systematic evaluation of ensemble learning techniques and limited exploration of diverse advanced models introduced in the past one or two years. To address these limitations, we propose a robust ensemble learning grid search-tuned framework (RAINER) for rainfall prediction. RAINER incorporates a comprehensive feature engineering pipeline, including outlier removal, imputation of missing values, feature reconstruction, and dimensionality reduction via Principal Component Analysis (PCA). The framework integrates novel meteorological features to capture dynamic weather patterns and systematically evaluates non-learning mathematical-based methods and a variety of machine learning models, from weak classifiers to advanced neural networks such as Kolmogorov-Arnold Networks (KAN). By leveraging grid search for hyperparameter tuning and ensemble voting techniques, RAINER achieves promising results within real-world datasets.
CP2M: Clustered-Patch-Mixed Mosaic Augmentation for Aerial Image Segmentation
Jan 26, 2025



Remote sensing image segmentation is pivotal for earth observation, underpinning applications such as environmental monitoring and urban planning. Due to the limited annotation data available in remote sensing images, numerous studies have focused on data augmentation as a means to alleviate overfitting in deep learning networks. However, some existing data augmentation strategies rely on simple transformations that may not sufficiently enhance data diversity or model generalization capabilities. This paper proposes a novel augmentation strategy, Clustered-Patch-Mixed Mosaic (CP2M), designed to address these limitations. CP2M integrates a Mosaic augmentation phase with a clustered patch mix phase. The former stage constructs a new sample from four random samples, while the latter phase uses the connected component labeling algorithm to ensure the augmented data maintains spatial coherence and avoids introducing irrelevant semantics when pasting random patches. Our experiments on the ISPRS Potsdam dataset demonstrate that CP2M substantially mitigates overfitting, setting new benchmarks for segmentation accuracy and model robustness in remote sensing tasks.
DDUNet: Dual Dynamic U-Net for Highly-Efficient Cloud Segmentation
Jan 26, 2025



Cloud segmentation amounts to separating cloud pixels from non-cloud pixels in an image. Current deep learning methods for cloud segmentation suffer from three issues. (a) Constrain on their receptive field due to the fixed size of the convolution kernel. (b) Lack of robustness towards different scenarios. (c) Requirement of a large number of parameters and limitations for real-time implementation. To address these issues, we propose a Dual Dynamic U-Net (DDUNet) for supervised cloud segmentation. The DDUNet adheres to a U-Net architecture and integrates two crucial modules: the dynamic multi-scale convolution (DMSC), improving merging features under different reception fields, and the dynamic weights and bias generator (DWBG) in classification layers to enhance generalization ability. More importantly, owing to the use of depth-wise convolution, the DDUNet is a lightweight network that can achieve 95.3% accuracy on the SWINySEG dataset with only 0.33M parameters, and achieve superior performance over three different configurations of the SWINySEg dataset in both accuracy and efficiency.
UCloudNet: A Residual U-Net with Deep Supervision for Cloud Image Segmentation
Jan 11, 2025



Recent advancements in meteorology involve the use of ground-based sky cameras for cloud observation. Analyzing images from these cameras helps in calculating cloud coverage and understanding atmospheric phenomena. Traditionally, cloud image segmentation relied on conventional computer vision techniques. However, with the advent of deep learning, convolutional neural networks (CNNs) are increasingly applied for this purpose. Despite their effectiveness, CNNs often require many epochs to converge, posing challenges for real-time processing in sky camera systems. In this paper, we introduce a residual U-Net with deep supervision for cloud segmentation which provides better accuracy than previous approaches, and with less training consumption. By utilizing residual connection in encoders of UCloudNet, the feature extraction ability is further improved.
* 6 pages, 4 figures
Interpreting a Semantic Segmentation Model for Coastline Detection
May 19, 2024We interpret a deep-learning semantic segmentation model used to classify coastline satellite images into land and water. This is to build trust in the model and gain new insight into the process of coastal water body extraction. Specifically, we seek to understand which spectral bands are important for predicting segmentation masks. This is done using a permutation importance approach. Results show that the NIR is the most important spectral band. Permuting this band lead to a decrease in accuracy of 38.12 percentage points. This is followed by Water Vapour, SWIR 1, and Blue bands with 2.58, 0.78 and 0.19 respectively. Water Vapour is not typically used in water indices and these results suggest it may be useful for water body extraction. Permuting, the Coastal Aerosol, Green, Red, RE1, RE2, RE3, RE4, and SWIR 2 bands did not decrease accuracy. This suggests they could be excluded from future model builds reducing complexity and computational requirements.
The Effectiveness of Edge Detection Evaluation Metrics for Automated Coastline Detection
May 19, 2024We analyse the effectiveness of RMSE, PSNR, SSIM and FOM for evaluating edge detection algorithms used for automated coastline detection. Typically, the accuracy of detected coastlines is assessed visually. This can be impractical on a large scale leading to the need for objective evaluation metrics. Hence, we conduct an experiment to find reliable metrics. We apply Canny edge detection to 95 coastline satellite images across 49 testing locations. We vary the Hysteresis thresholds and compare metric values to a visual analysis of detected edges. We found that FOM was the most reliable metric for selecting the best threshold. It could select a better threshold 92.6% of the time and the best threshold 66.3% of the time. This is compared RMSE, PSNR and SSIM which could select the best threshold 6.3%, 6.3% and 11.6% of the time respectively. We provide a reason for these results by reformulating RMSE, PSNR and SSIM in terms of confusion matrix measures. This suggests these metrics not only fail for this experiment but are not useful for evaluating edge detection in general.
Automated Coastline Extraction Using Edge Detection Algorithms
May 19, 2024We analyse the effectiveness of edge detection algorithms for the purpose of automatically extracting coastlines from satellite images. Four algorithms - Canny, Sobel, Scharr and Prewitt are compared visually and using metrics. With an average SSIM of 0.8, Canny detected edges that were closest to the reference edges. However, the algorithm had difficulty distinguishing noisy edges, e.g. due to development, from coastline edges. In addition, histogram equalization and Gaussian blur were shown to improve the effectiveness of the edge detection algorithms by up to 1.5 and 1.6 times respectively.