 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrafficKAN-GCN: Graph Convolutional-based Kolmogorov-Arnold Network for Traffic Flow Optimization
Mar 05, 2025Urban traffic optimization is critical for improving transportation efficiency and alleviating congestion, particularly in large-scale dynamic networks. Traditional methods, such as Dijkstra's and Floyd's algorithms, provide effective solutions in static settings, but they struggle with the spatial-temporal complexity of real-world traffic flows. In this work, we propose TrafficKAN-GCN, a hybrid deep learning framework combining Kolmogorov-Arnold Networks (KAN) with Graph Convolutional Networks (GCN), designed to enhance urban traffic flow optimization. By integrating KAN's adaptive nonlinear function approximation with GCN's spatial graph learning capabilities, TrafficKAN-GCN captures both complex traffic patterns and topological dependencies. We evaluate the proposed framework using real-world traffic data from the Baltimore Metropolitan area. Compared with baseline models such as MLP-GCN, standard GCN, and Transformer-based approaches, TrafficKAN-GCN achieves competitive prediction accuracy while demonstrating improved robustness in handling noisy and irregular traffic data. Our experiments further highlight the framework's ability to redistribute traffic flow, mitigate congestion, and adapt to disruptive events, such as the Francis Scott Key Bridge collapse. This study contributes to the growing body of work on hybrid graph learning for intelligent transportation systems, highlighting the potential of combining KAN and GCN for real-time traffic optimization. Future work will focus on reducing computational overhead and integrating Transformer-based temporal modeling for enhanced long-term traffic prediction. The proposed TrafficKAN-GCN framework offers a promising direction for data-driven urban mobility management, balancing predictive accuracy, robustness, and computational efficiency.
ScribFormer: Transformer Makes CNN Work Better for Scribble-based Medical Image Segmentation
Feb 03, 2024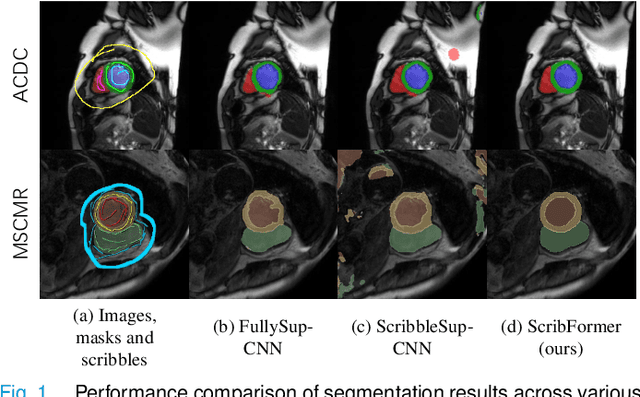
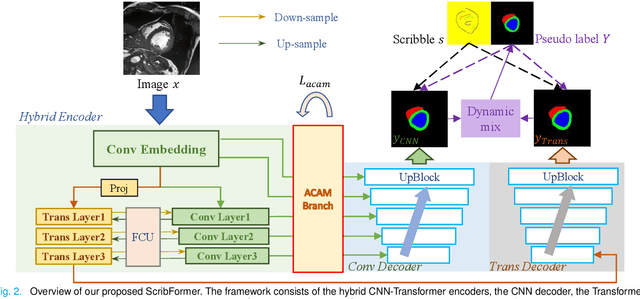
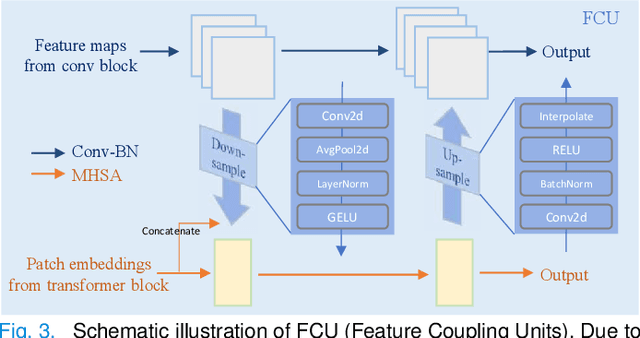
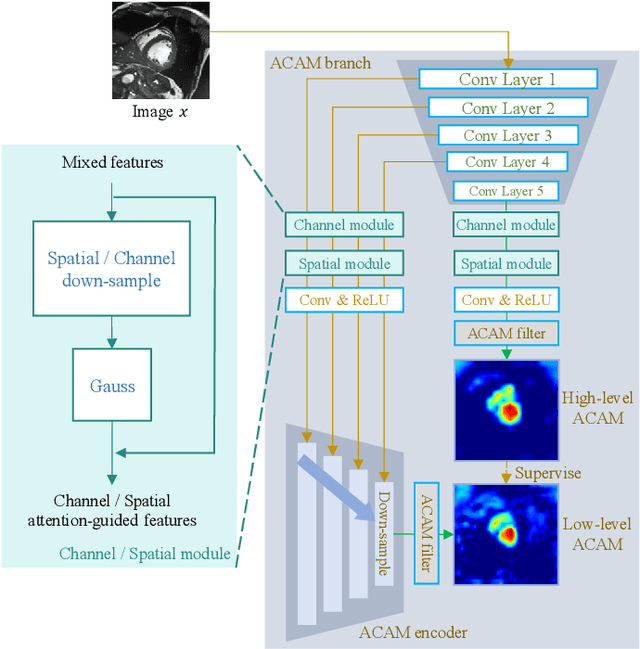
Most recent scribble-supervised segmentation methods commonly adopt a CNN framework with an encoder-decoder architecture. Despite its multiple benefits, this framework generally can only capture small-range feature dependency for the convolutional layer with the local receptive field, which makes it difficult to learn global shape information from the limited information provided by scribble annotations. To address this issue, this paper proposes a new CNN-Transformer hybrid solution for scribble-supervised medical image segmentation called ScribFormer. The proposed ScribFormer model has a triple-branch structure, i.e., the hybrid of a CNN branch, a Transformer branch, and an attention-guided class activation map (ACAM) branch. Specifically, the CNN branch collaborates with the Transformer branch to fuse the local features learned from CNN with the global representations obtained from Transformer, which can effectively overcome limitations of existing scribble-supervised segmentation methods. Furthermore, the ACAM branch assists in unifying the shallow convolution features and the deep convolution features to improve model's performance further. Extensive experiments on two public datasets and one private dataset show that our ScribFormer has superior performance over the state-of-the-art scribble-supervised segmentation methods, and achieves even better results than the fully-supervised segmentation methods. The code is released at https://github.com/HUANGLIZI/ScribFormer.
Semantic Communications with Explicit Semantic Base for Image Transmission
Aug 12, 2023



Semantic communications, aiming at ensuring the successful delivery of the meaning of information, are expected to be one of the potential techniques for the next generation communications. However, the knowledge forming and synchronizing mechanism that enables semantic communication systems to extract and interpret the semantics of information according to the communication intents is still immature. In this paper, we propose a semantic image transmission framework with explicit semantic base (Seb), where Sebs are generated and employed as the knowledge shared between the transmitter and the receiver with flexible granularity. To represent images with Sebs, a novel Seb-based reference image generator is proposed to generate Sebs and then decompose the transmitted images. To further encode/decode the residual information for precise image reconstruction, a Seb-based image encoder/decoder is proposed. The key components of the proposed framework are optimized jointly by end-to-end (E2E) training, where the loss function is dedicated designed to tackle the problem of nondifferentiable operation in Seb-based reference image generator by introducing a gradient approximation mechanism. Extensive experiments show that the proposed framework outperforms state-of-art works by 0.5 - 1.5 dB in peak signal-to-noise ratio (PSNR) w.r.t. different signal-to-noise ratio (SNR).
ScribbleVC: Scribble-supervised Medical Image Segmentation with Vision-Class Embedding
Jul 30, 2023Medical image segmentation plays a critical role in clinical decision-making, treatment planning, and disease monitoring. However, accurate segmentation of medical images is challenging due to several factors, such as the lack of high-quality annotation, imaging noise, and anatomical differences across patients. In addition, there is still a considerable gap in performance between the existing label-efficient methods and fully-supervised methods. To address the above challenges, we propose ScribbleVC, a novel framework for scribble-supervised medical image segmentation that leverages vision and class embeddings via the multimodal information enhancement mechanism. In addition, ScribbleVC uniformly utilizes the CNN features and Transformer features to achieve better visual feature extraction. The proposed method combines a scribble-based approach with a segmentation network and a class-embedding module to produce accurate segmentation masks. We evaluate ScribbleVC on three benchmark datasets and compare it with state-of-the-art methods. The experimental results demonstrate that our method outperforms existing approaches in terms of accuracy, robustness, and efficiency. The datasets and code are released on GitHub.
PSGformer: Enhancing 3D Point Cloud Instance Segmentation via Precise Semantic Guidance
Jul 15, 2023Most existing 3D instance segmentation methods are derived from 3D semantic segmentation models. However, these indirect approaches suffer from certain limitations. They fail to fully leverage global and local semantic information for accurate prediction, which hampers the overall performance of the 3D instance segmentation framework. To address these issues, this paper presents PSGformer, a novel 3D instance segmentation network. PSGformer incorporates two key advancements to enhance the performance of 3D instance segmentation. Firstly, we propose a Multi-Level Semantic Aggregation Module, which effectively captures scene features by employing foreground point filtering and multi-radius aggregation. This module enables the acquisition of more detailed semantic information from global and local perspectives. Secondly, PSGformer introduces a Parallel Feature Fusion Transformer Module that independently processes super-point features and aggregated features using transformers. The model achieves a more comprehensive feature representation by the features which connect global and local features. We conducted extensive experiments on the ScanNetv2 dataset. Notably, PSGformer exceeds compared state-of-the-art methods by 2.2% on ScanNetv2 hidden test set in terms of mAP. Our code and models will be publicly released.
Pose-Aided Video-based Person Re-Identification via Recurrent Graph Convolutional Network
Sep 23, 2022

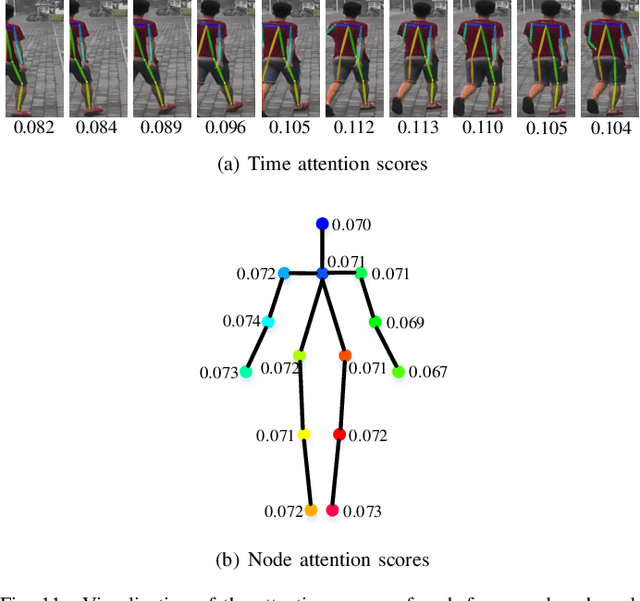
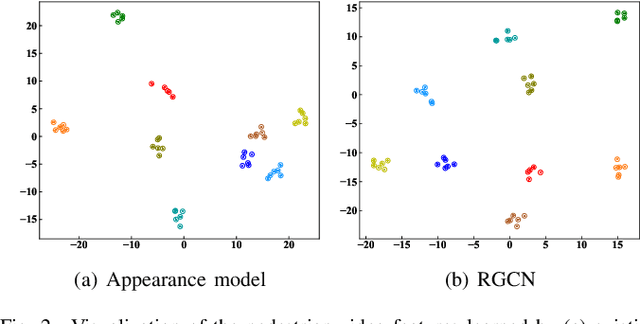
Existing methods for video-based person re-identification (ReID) mainly learn the appearance feature of a given pedestrian via a feature extractor and a feature aggregator. However, the appearance models would fail when different pedestrians have similar appearances. Considering that different pedestrians have different walking postures and body proportions, we propose to learn the discriminative pose feature beyond the appearance feature for video retrieval. Specifically, we implement a two-branch architecture to separately learn the appearance feature and pose feature, and then concatenate them together for inference. To learn the pose feature, we first detect the pedestrian pose in each frame through an off-the-shelf pose detector, and construct a temporal graph using the pose sequence. We then exploit a recurrent graph convolutional network (RGCN) to learn the node embeddings of the temporal pose graph, which devises a global information propagation mechanism to simultaneously achieve the neighborhood aggregation of intra-frame nodes and message passing among inter-frame graphs. Finally, we propose a dual-attention method consisting of node-attention and time-attention to obtain the temporal graph representation from the node embeddings, where the self-attention mechanism is employed to learn the importance of each node and each frame. We verify the proposed method on three video-based ReID datasets, i.e., Mars, DukeMTMC and iLIDS-VID, whose experimental results demonstrate that the learned pose feature can effectively improve the performance of existing appearance models.
Homotopy Based Reinforcement Learning with Maximum Entropy for Autonomous Air Combat
Dec 01, 2021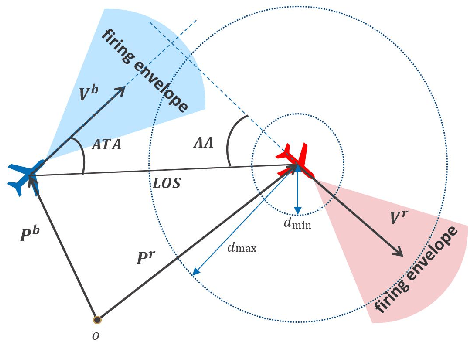
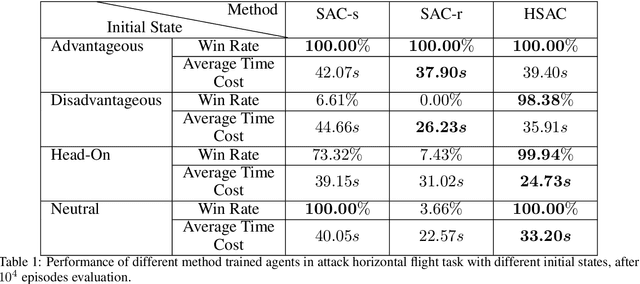
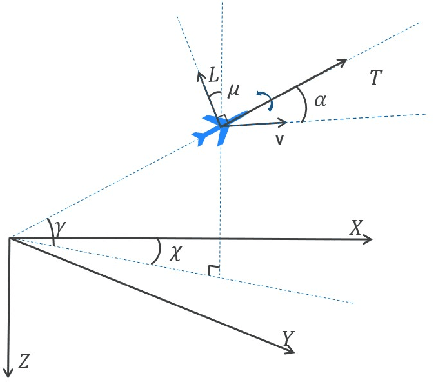

The Intelligent decision of the unmanned combat aerial vehicle (UCAV) has long been a challenging problem. The conventional search method can hardly satisfy the real-time demand during high dynamics air combat scenarios. The reinforcement learning (RL) method can significantly shorten the decision time via using neural networks. However, the sparse reward problem limits its convergence speed and the artificial prior experience reward can easily deviate its optimal convergent direction of the original task, which raises great difficulties for the RL air combat application. In this paper, we propose a homotopy-based soft actor-critic method (HSAC) which focuses on addressing these problems via following the homotopy path between the original task with sparse reward and the auxiliary task with artificial prior experience reward. The convergence and the feasibility of this method are also proved in this paper. To confirm our method feasibly, we construct a detailed 3D air combat simulation environment for the RL-based methods training firstly, and we implement our method in both the attack horizontal flight UCAV task and the self-play confrontation task. Experimental results show that our method performs better than the methods only utilizing the sparse reward or the artificial prior experience reward. The agent trained by our method can reach more than 98.3% win rate in the attack horizontal flight UCAV task and average 67.4% win rate when confronted with the agents trained by the other two methods.
Energy-Efficient Online Data Sensing and Processing in Wireless Powered Edge Computing Systems
Nov 04, 2021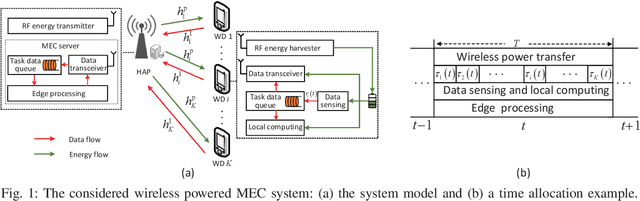
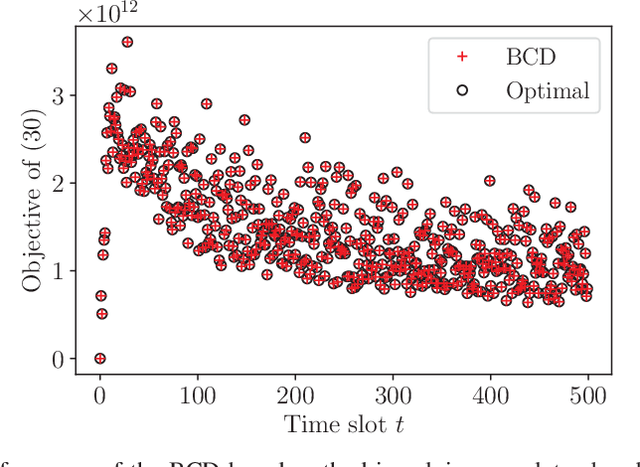
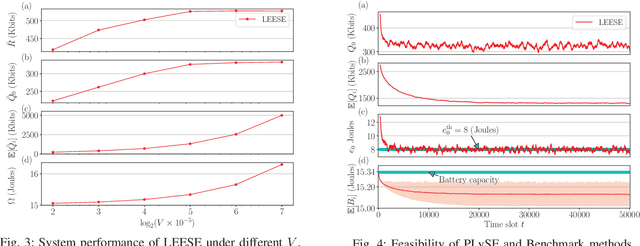
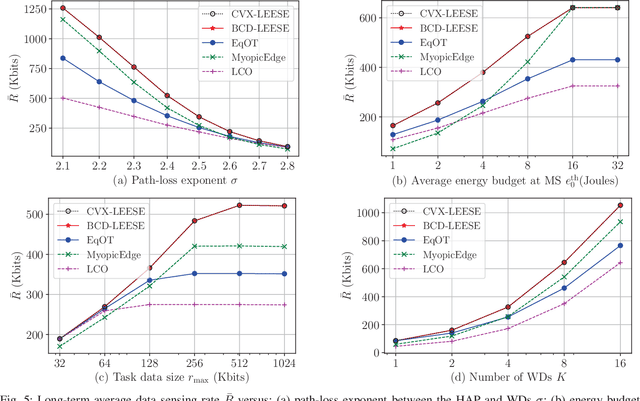
This paper focuses on developing energy-efficient online data processing strategy of wireless powered MEC systems under stochastic fading channels. In particular, we consider a hybrid access point (HAP) transmitting RF energy to and processing the sensing data offloaded from multiple WDs. Under an average power constraint of the HAP, we aim to maximize the long-term average data sensing rate of the WDs while maintaining task data queue stability. We formulate the problem as a multi-stage stochastic optimization to control the energy transfer and task data processing in sequential time slots. Without the knowledge of future channel fading, it is very challenging to determine the sequential control actions that are tightly coupled by the battery and data buffer dynamics. To solve the problem, we propose an online algorithm named LEESE that applies the perturbed Lyapunov optimization technique to decompose the multi-stage stochastic problem into per-slot deterministic optimization problems. We show that each per-slot problem can be equivalently transformed into a convex optimization problem. To facilitate online implementation in large-scale MEC systems, instead of solving the per-slot problem with off-the-shelf convex algorithms, we propose a block coordinate descent (BCD)-based method that produces close-to-optimal solution in less than 0.04\% of the computation delay. Simulation results demonstrate that the proposed LEESE algorithm can provide 21.9\% higher data sensing rate than the representative benchmark methods considered, while incurring sub-millisecond computation delay suitable for real-time control under fading channel.
Real-Time Cardiac Cine MRI with Residual Convolutional Recurrent Neural Network
Aug 20, 2020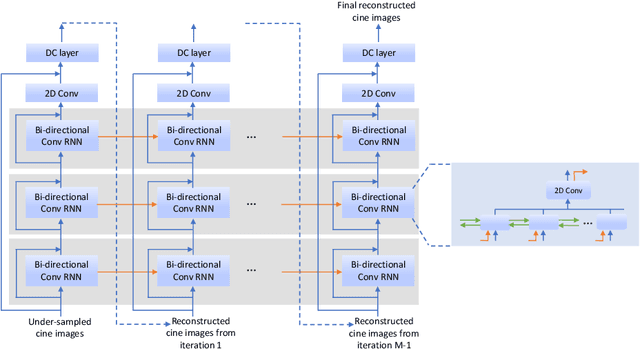
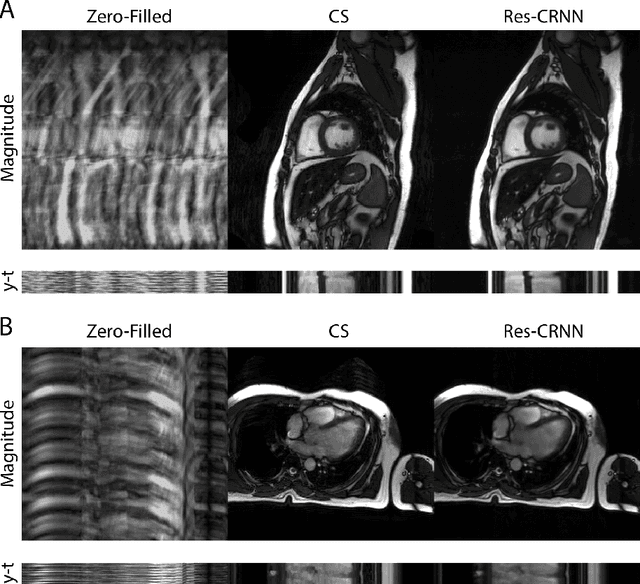
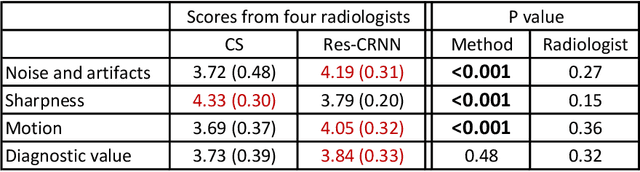

Real-time cardiac cine MRI does not require ECG gating in the data acquisition and is more useful for patients who can not hold their breaths or have abnormal heart rhythms. However, to achieve fast image acquisition, real-time cine commonly acquires highly undersampled data, which imposes a significant challenge for MRI image reconstruction. We propose a residual convolutional RNN for real-time cardiac cine reconstruction. To the best of our knowledge, this is the first work applying deep learning approach to Cartesian real-time cardiac cine reconstruction. Based on the evaluation from radiologists, our deep learning model shows superior performance than compressed sensing.