 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecureGS: Boosting the Security and Fidelity of 3D Gaussian Splatting Steganography
Mar 08, 2025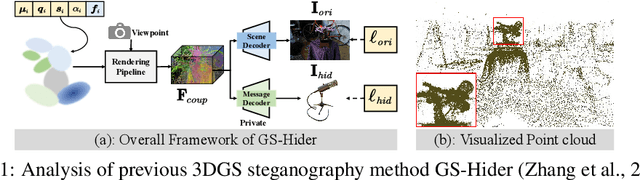
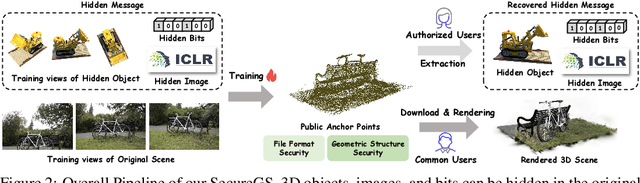
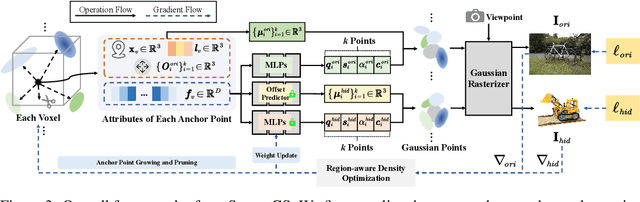

3D Gaussian Splatting (3DGS) has emerged as a premier method for 3D representation due to its real-time rendering and high-quality outputs, underscoring the critical need to protect the privacy of 3D assets. Traditional NeRF steganography methods fail to address the explicit nature of 3DGS since its point cloud files are publicly accessible. Existing GS steganography solutions mitigate some issues but still struggle with reduced rendering fidelity, increased computational demands, and security flaws, especially in the security of the geometric structure of the visualized point cloud. To address these demands, we propose a SecureGS, a secure and efficient 3DGS steganography framework inspired by Scaffold-GS's anchor point design and neural decoding. SecureGS uses a hybrid decoupled Gaussian encryption mechanism to embed offsets, scales, rotations, and RGB attributes of the hidden 3D Gaussian points in anchor point features, retrievable only by authorized users through privacy-preserving neural networks. To further enhance security, we propose a density region-aware anchor growing and pruning strategy that adaptively locates optimal hiding regions without exposing hidden information. Extensive experiments show that SecureGS significantly surpasses existing GS steganography methods in rendering fidelity, speed, and security.
Fourier123: One Image to High-Quality 3D Object Generation with Hybrid Fourier Score Distillation
May 31, 2024Single image-to-3D generation is pivotal for crafting controllable 3D assets. Given its underconstrained nature, we leverage geometric priors from a 3D novel view generation diffusion model and appearance priors from a 2D image generation method to guide the optimization process. We note that a disparity exists between the training datasets of 2D and 3D diffusion models, leading to their outputs showing marked differences in appearance. Specifically, 2D models tend to deliver more detailed visuals, whereas 3D models produce consistent yet over-smooth results across different views. Hence, we optimize a set of 3D Gaussians using 3D priors in spatial domain to ensure geometric consistency, while exploiting 2D priors in the frequency domain through Fourier transform for higher visual quality. This 2D-3D hybrid Fourier Score Distillation objective function (dubbed hy-FSD), can be integrated into existing 3D generation methods, yielding significant performance improvements. With this technique, we further develop an image-to-3D generation pipeline to create high-quality 3D objects within one minute, named Fourier123. Extensive experiments demonstrate that Fourier123 excels in efficient generation with rapid convergence speed and visual-friendly generation results.
Mirror-3DGS: Incorporating Mirror Reflections into 3D Gaussian Splatting
Apr 01, 2024
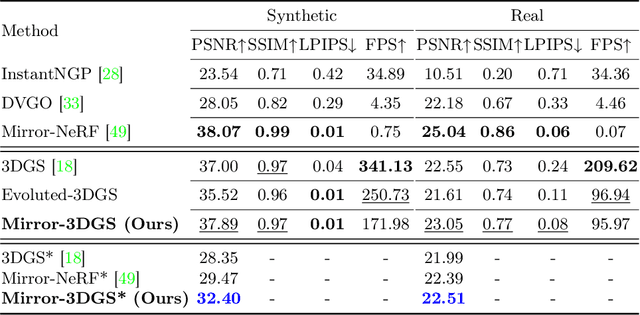
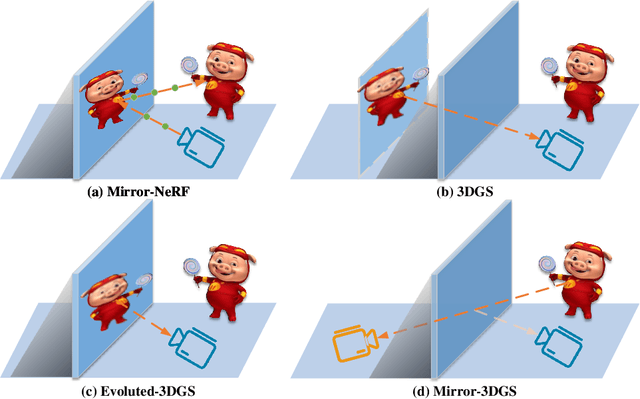
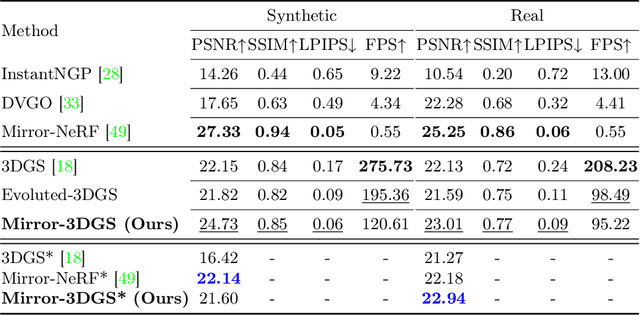
3D Gaussian Splatting (3DGS) has marked a significant breakthrough in the realm of 3D scene reconstruction and novel view synthesis. However, 3DGS, much like its predecessor Neural Radiance Fields (NeRF), struggles to accurately model physical reflections, particularly in mirrors that are ubiquitous in real-world scenes. This oversight mistakenly perceives reflections as separate entities that physically exist, resulting in inaccurate reconstructions and inconsistent reflective properties across varied viewpoints. To address this pivotal challenge, we introduce Mirror-3DGS, an innovative rendering framework devised to master the intricacies of mirror geometries and reflections, paving the way for the generation of realistically depicted mirror reflections. By ingeniously incorporating mirror attributes into the 3DGS and leveraging the principle of plane mirror imaging, Mirror-3DGS crafts a mirrored viewpoint to observe from behind the mirror, enriching the realism of scene renderings. Extensive assessments, spanning both synthetic and real-world scenes, showcase our method's ability to render novel views with enhanced fidelity in real-time, surpassing the state-of-the-art Mirror-NeRF specifically within the challenging mirror regions. Our code will be made publicly available for reproducible research.
Selective Hourglass Mapping for Universal Image Restoration Based on Diffusion Model
Mar 17, 2024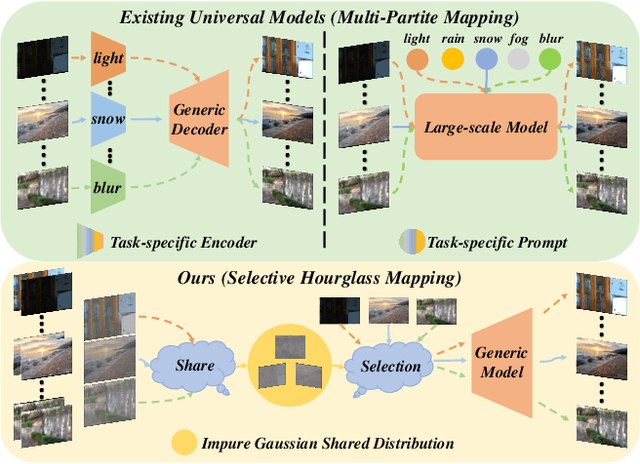



Universal image restoration is a practical and potential computer vision task for real-world applications. The main challenge of this task is handling the different degradation distributions at once. Existing methods mainly utilize task-specific conditions (e.g., prompt) to guide the model to learn different distributions separately, named multi-partite mapping. However, it is not suitable for universal model learning as it ignores the shared information between different tasks. In this work, we propose an advanced selective hourglass mapping strategy based on diffusion model, termed DiffUIR. Two novel considerations make our DiffUIR non-trivial. Firstly, we equip the model with strong condition guidance to obtain accurate generation direction of diffusion model (selective). More importantly, DiffUIR integrates a flexible shared distribution term (SDT) into the diffusion algorithm elegantly and naturally, which gradually maps different distributions into a shared one. In the reverse process, combined with SDT and strong condition guidance, DiffUIR iteratively guides the shared distribution to the task-specific distribution with high image quality (hourglass). Without bells and whistles, by only modifying the mapping strategy, we achieve state-of-the-art performance on five image restoration tasks, 22 benchmarks in the universal setting and zero-shot generalization setting. Surprisingly, by only using a lightweight model (only 0.89M), we could achieve outstanding performance. The source code and pre-trained models are available at https://github.com/iSEE-Laboratory/DiffUIR
ScribFormer: Transformer Makes CNN Work Better for Scribble-based Medical Image Segmentation
Feb 03, 2024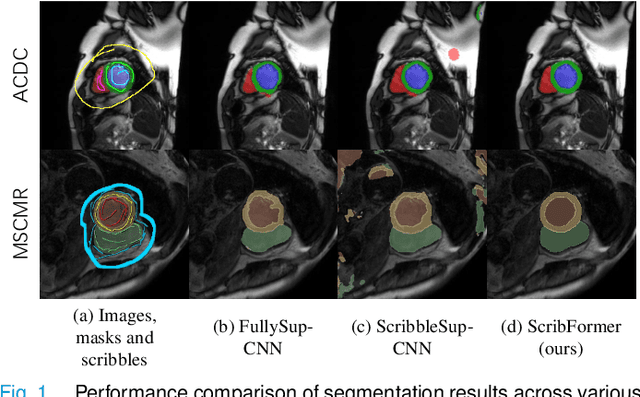
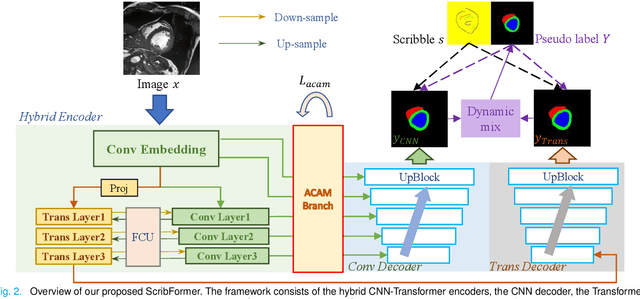
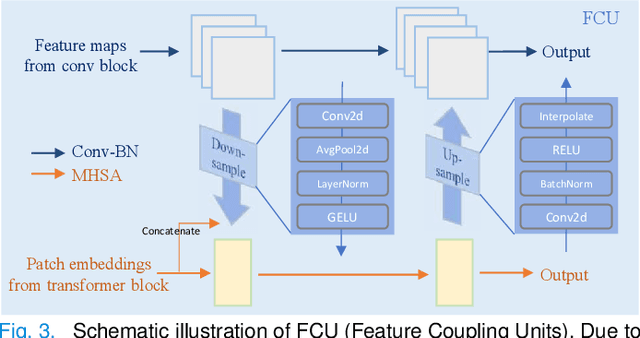
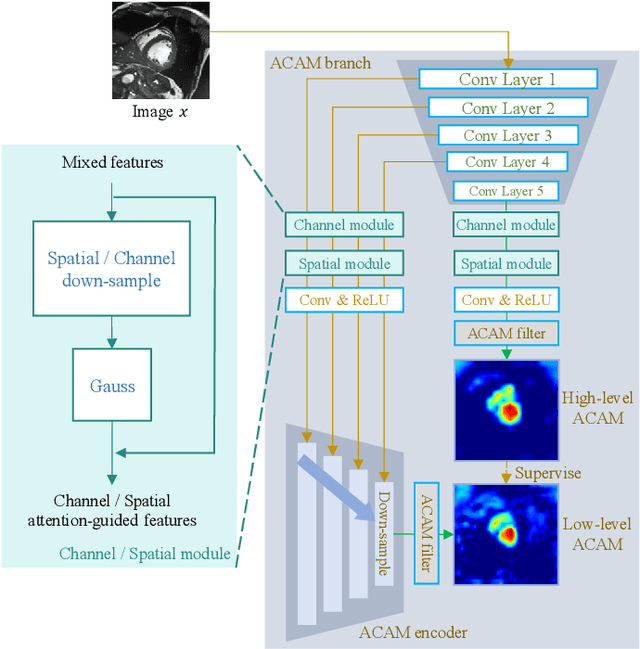
Most recent scribble-supervised segmentation methods commonly adopt a CNN framework with an encoder-decoder architecture. Despite its multiple benefits, this framework generally can only capture small-range feature dependency for the convolutional layer with the local receptive field, which makes it difficult to learn global shape information from the limited information provided by scribble annotations. To address this issue, this paper proposes a new CNN-Transformer hybrid solution for scribble-supervised medical image segmentation called ScribFormer. The proposed ScribFormer model has a triple-branch structure, i.e., the hybrid of a CNN branch, a Transformer branch, and an attention-guided class activation map (ACAM) branch. Specifically, the CNN branch collaborates with the Transformer branch to fuse the local features learned from CNN with the global representations obtained from Transformer, which can effectively overcome limitations of existing scribble-supervised segmentation methods. Furthermore, the ACAM branch assists in unifying the shallow convolution features and the deep convolution features to improve model's performance further. Extensive experiments on two public datasets and one private dataset show that our ScribFormer has superior performance over the state-of-the-art scribble-supervised segmentation methods, and achieves even better results than the fully-supervised segmentation methods. The code is released at https://github.com/HUANGLIZI/ScribFormer.
Neural Video Fields Editing
Dec 12, 2023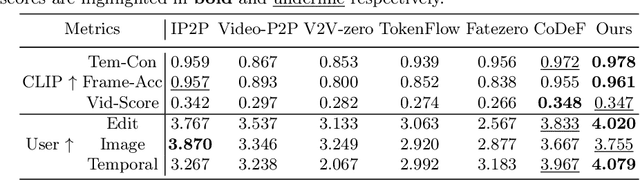
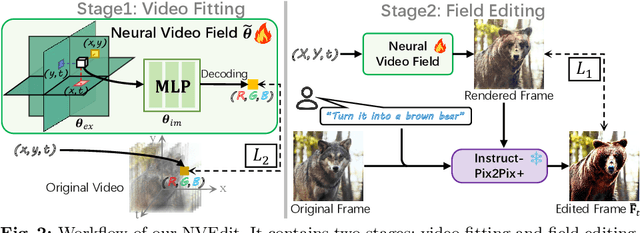


Diffusion models have revolutionized text-driven video editing. However, applying these methods to real-world editing encounters two significant challenges: (1) the rapid increase in graphics memory demand as the number of frames grows, and (2) the inter-frame inconsistency in edited videos. To this end, we propose NVEdit, a novel text-driven video editing framework designed to mitigate memory overhead and improve consistent editing for real-world long videos. Specifically, we construct a neural video field, powered by tri-plane and sparse grid, to enable encoding long videos with hundreds of frames in a memory-efficient manner. Next, we update the video field through off-the-shelf Text-to-Image (T2I) models to impart text-driven editing effects. A progressive optimization strategy is developed to preserve original temporal priors. Importantly, both the neural video field and T2I model are adaptable and replaceable, thus inspiring future research. Experiments demonstrate that our approach successfully edits hundreds of frames with impressive inter-frame consistency.
DiffLLE: Diffusion-guided Domain Calibration for Unsupervised Low-light Image Enhancement
Aug 18, 2023



Existing unsupervised low-light image enhancement methods lack enough effectiveness and generalization in practical applications. We suppose this is because of the absence of explicit supervision and the inherent gap between real-world scenarios and the training data domain. In this paper, we develop Diffusion-based domain calibration to realize more robust and effective unsupervised Low-Light Enhancement, called DiffLLE. Since the diffusion model performs impressive denoising capability and has been trained on massive clean images, we adopt it to bridge the gap between the real low-light domain and training degradation domain, while providing efficient priors of real-world content for unsupervised models. Specifically, we adopt a naive unsupervised enhancement algorithm to realize preliminary restoration and design two zero-shot plug-and-play modules based on diffusion model to improve generalization and effectiveness. The Diffusion-guided Degradation Calibration (DDC) module narrows the gap between real-world and training low-light degradation through diffusion-based domain calibration and a lightness enhancement curve, which makes the enhancement model perform robustly even in sophisticated wild degradation. Due to the limited enhancement effect of the unsupervised model, we further develop the Fine-grained Target domain Distillation (FTD) module to find a more visual-friendly solution space. It exploits the priors of the pre-trained diffusion model to generate pseudo-references, which shrinks the preliminary restored results from a coarse normal-light domain to a finer high-quality clean field, addressing the lack of strong explicit supervision for unsupervised methods. Benefiting from these, our approach even outperforms some supervised methods by using only a simple unsupervised baseline. Extensive experiments demonstrate the superior effectiveness of the proposed DiffLLE.
Contrastive Learning Based Recursive Dynamic Multi-Scale Network for Image Deraining
May 29, 2023Rain streaks significantly decrease the visibility of captured images and are also a stumbling block that restricts the performance of subsequent computer vision applications. The existing deep learning-based image deraining methods employ manually crafted networks and learn a straightforward projection from rainy images to clear images. In pursuit of better deraining performance, they focus on elaborating a more complicated architecture rather than exploiting the intrinsic properties of the positive and negative information. In this paper, we propose a contrastive learning-based image deraining method that investigates the correlation between rainy and clear images and leverages a contrastive prior to optimize the mutual information of the rainy and restored counterparts. Given the complex and varied real-world rain patterns, we develop a recursive mechanism. It involves multi-scale feature extraction and dynamic cross-level information recruitment modules. The former advances the portrayal of diverse rain patterns more precisely, while the latter can selectively compensate high-level features for shallow-level information. We term the proposed recursive dynamic multi-scale network with a contrastive prior, RDMC. Extensive experiments on synthetic benchmarks and real-world images demonstrate that the proposed RDMC delivers strong performance on the depiction of rain streaks and outperforms the state-of-the-art methods. Moreover, a practical evaluation of object detection and semantic segmentation shows the effectiveness of the proposed method.
Implicit Neural Representation for Cooperative Low-light Image Enhancement
Mar 21, 2023The following three factors restrict the application of existing low-light image enhancement methods: unpredictable brightness degradation and noise, inherent gap between metric-favorable and visual-friendly versions, and the limited paired training data. To address these limitations, we propose an implicit Neural Representation method for Cooperative low-light image enhancement, dubbed NeRCo. It robustly recovers perceptual-friendly results in an unsupervised manner. Concretely, NeRCo unifies the diverse degradation factors of real-world scenes with a controllable fitting function, leading to better robustness. In addition, for the output results, we introduce semantic-orientated supervision with priors from the pre-trained vision-language model. Instead of merely following reference images, it encourages results to meet subjective expectations, finding more visual-friendly solutions. Further, to ease the reliance on paired data and reduce solution space, we develop a dual-closed-loop constrained enhancement module. It is trained cooperatively with other affiliated modules in a self-supervised manner. Finally, extensive experiments demonstrate the robustness and superior effectiveness of our proposed NeRCo. Our code is available at https://github.com/Ysz2022/NeRCo.
NeRFocus: Neural Radiance Field for 3D Synthetic Defocus
Mar 10, 2022



Neural radiance fields (NeRF) bring a new wave for 3D interactive experiences. However, as an important part of the immersive experiences, the defocus effects have not been fully explored within NeRF. Some recent NeRF-based methods generate 3D defocus effects in a post-process fashion by utilizing multiplane technology. Still, they are either time-consuming or memory-consuming. This paper proposes a novel thin-lens-imaging-based NeRF framework that can directly render various 3D defocus effects, dubbed NeRFocus. Unlike the pinhole, the thin lens refracts rays of a scene point, so its imaging on the sensor plane is scattered as a circle of confusion (CoC). A direct solution sampling enough rays to approximate this process is computationally expensive. Instead, we propose to inverse the thin lens imaging to explicitly model the beam path for each point on the sensor plane and generalize this paradigm to the beam path of each pixel, then use the frustum-based volume rendering to render each pixel's beam path. We further design an efficient probabilistic training (p-training) strategy to simplify the training process vastly. Extensive experiments demonstrate that our NeRFocus can achieve various 3D defocus effects with adjustable camera pose, focus distance, and aperture size. Existing NeRF can be regarded as our special case by setting aperture size as zero to render large depth-of-field images. Despite such merits, NeRFocus does not sacrifice NeRF's original performance (e.g., training and inference time, parameter consumption, rendering quality), which implies its great potential for broader application and further improvement.