 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalkPhoto: A Versatile Training-Free Conversational Assistant for Intelligent Image Editing
Jan 05, 2026Thanks to the powerful language comprehension capabilities of Large Language Models (LLMs), existing instruction-based image editing methods have introduced Multimodal Large Language Models (MLLMs) to promote information exchange between instructions and images, ensuring the controllability and flexibility of image editing. However, these frameworks often build a multi-instruction dataset to train the model to handle multiple editing tasks, which is not only time-consuming and labor-intensive but also fails to achieve satisfactory results. In this paper, we present TalkPhoto, a versatile training-free image editing framework that facilitates precise image manipulation through conversational interaction. We instruct the open-source LLM with a specially designed prompt template to analyze user needs after receiving instructions and hierarchically invoke existing advanced editing methods, all without additional training. Moreover, we implement a plug-and-play and efficient invocation of image editing methods, allowing complex and unseen editing tasks to be integrated into the current framework, achieving stable and high-quality editing results. Extensive experiments demonstrate that our method not only provides more accurate invocation with fewer token consumption but also achieves higher editing quality across various image editing tasks.
Face2Face: Label-driven Facial Retouching Restoration
Apr 22, 2024



With the popularity of social media platforms such as Instagram and TikTok, and the widespread availability and convenience of retouching tools, an increasing number of individuals are utilizing these tools to beautify their facial photographs. This poses challenges for fields that place high demands on the authenticity of photographs, such as identity verification and social media. By altering facial images, users can easily create deceptive images, leading to the dissemination of false information. This may pose challenges to the reliability of identity verification systems and social media, and even lead to online fraud. To address this issue, some work has proposed makeup removal methods, but they still lack the ability to restore images involving geometric deformations caused by retouching. To tackle the problem of facial retouching restoration, we propose a framework, dubbed Face2Face, which consists of three components: a facial retouching detector, an image restoration model named FaceR, and a color correction module called Hierarchical Adaptive Instance Normalization (H-AdaIN). Firstly, the facial retouching detector predicts a retouching label containing three integers, indicating the retouching methods and their corresponding degrees. Then FaceR restores the retouched image based on the predicted retouching label. Finally, H-AdaIN is applied to address the issue of color shift arising from diffusion models. Extensive experiments demonstrate the effectiveness of our framework and each module.
GAN Prior based Null-Space Learning for Consistent Super-Resolution
Nov 24, 2022Consistency and realness have always been the two critical issues of image super-resolution. While the realness has been dramatically improved with the use of GAN prior, the state-of-the-art methods still suffer inconsistencies in local structures and colors (e.g., tooth and eyes). In this paper, we show that these inconsistencies can be analytically eliminated by learning only the null-space component while fixing the range-space part. Further, we design a pooling-based decomposition (PD), a universal range-null space decomposition for super-resolution tasks, which is concise, fast, and parameter-free. PD can be easily applied to state-of-the-art GAN Prior based SR methods to eliminate their inconsistencies, neither compromising the realness nor bringing extra parameters or computational costs. Besides, our ablation studies reveal that PD can replace pixel-wise losses for training and achieve better generalization performance when facing unseen downsamplings or even real-world degradation. Experiments show that the use of PD refreshes state-of-the-art SR performance and speeds up the convergence of training up to 2~10 times.
Panini-Net: GAN Prior Based Degradation-Aware Feature Interpolation for Face Restoration
Mar 16, 2022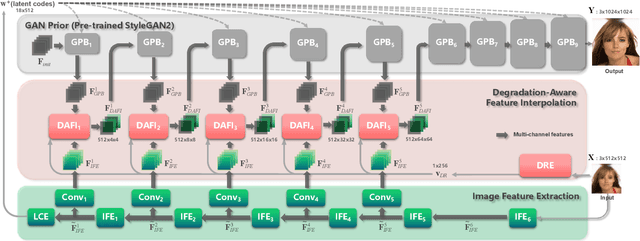


Emerging high-quality face restoration (FR) methods often utilize pre-trained GAN models (\textit{i.e.}, StyleGAN2) as GAN Prior. However, these methods usually struggle to balance realness and fidelity when facing various degradation levels. Besides, there is still a noticeable visual quality gap compared with pre-trained GAN models. In this paper, we propose a novel GAN Prior based degradation-aware feature interpolation network, dubbed Panini-Net, for FR tasks by explicitly learning the abstract representations to distinguish various degradations. Specifically, an unsupervised degradation representation learning (UDRL) strategy is first developed to extract degradation representations (DR) of the input degraded images. Then, a degradation-aware feature interpolation (DAFI) module is proposed to dynamically fuse the two types of informative features (\textit{i.e.}, features from input images and features from GAN Prior) with flexible adaption to various degradations based on DR. Ablation studies reveal the working mechanism of DAFI and its potential for editable FR. Extensive experiments demonstrate that our Panini-Net achieves state-of-the-art performance for multi-degradation face restoration and face super-resolution. The source code is available at https://github.com/jianzhangcs/panini.
NeRFocus: Neural Radiance Field for 3D Synthetic Defocus
Mar 10, 2022



Neural radiance fields (NeRF) bring a new wave for 3D interactive experiences. However, as an important part of the immersive experiences, the defocus effects have not been fully explored within NeRF. Some recent NeRF-based methods generate 3D defocus effects in a post-process fashion by utilizing multiplane technology. Still, they are either time-consuming or memory-consuming. This paper proposes a novel thin-lens-imaging-based NeRF framework that can directly render various 3D defocus effects, dubbed NeRFocus. Unlike the pinhole, the thin lens refracts rays of a scene point, so its imaging on the sensor plane is scattered as a circle of confusion (CoC). A direct solution sampling enough rays to approximate this process is computationally expensive. Instead, we propose to inverse the thin lens imaging to explicitly model the beam path for each point on the sensor plane and generalize this paradigm to the beam path of each pixel, then use the frustum-based volume rendering to render each pixel's beam path. We further design an efficient probabilistic training (p-training) strategy to simplify the training process vastly. Extensive experiments demonstrate that our NeRFocus can achieve various 3D defocus effects with adjustable camera pose, focus distance, and aperture size. Existing NeRF can be regarded as our special case by setting aperture size as zero to render large depth-of-field images. Despite such merits, NeRFocus does not sacrifice NeRF's original performance (e.g., training and inference time, parameter consumption, rendering quality), which implies its great potential for broader application and further improvement.