 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanX: Toward Agile and Generalizable Humanoid Interaction Skills from Human Videos
Feb 02, 2026Enabling humanoid robots to perform agile and adaptive interactive tasks has long been a core challenge in robotics. Current approaches are bottlenecked by either the scarcity of realistic interaction data or the need for meticulous, task-specific reward engineering, which limits their scalability. To narrow this gap, we present HumanX, a full-stack framework that compiles human video into generalizable, real-world interaction skills for humanoids, without task-specific rewards. HumanX integrates two co-designed components: XGen, a data generation pipeline that synthesizes diverse and physically plausible robot interaction data from video while supporting scalable data augmentation; and XMimic, a unified imitation learning framework that learns generalizable interaction skills. Evaluated across five distinct domains--basketball, football, badminton, cargo pickup, and reactive fighting--HumanX successfully acquires 10 different skills and transfers them zero-shot to a physical Unitree G1 humanoid. The learned capabilities include complex maneuvers such as pump-fake turnaround fadeaway jumpshots without any external perception, as well as interactive tasks like sustained human-robot passing sequences over 10 consecutive cycles--learned from a single video demonstration. Our experiments show that HumanX achieves over 8 times higher generalization success than prior methods, demonstrating a scalable and task-agnostic pathway for learning versatile, real-world robot interactive skills.
Learning Generalizable Hand-Object Tracking from Synthetic Demonstrations
Dec 22, 2025We present a system for learning generalizable hand-object tracking controllers purely from synthetic data, without requiring any human demonstrations. Our approach makes two key contributions: (1) HOP, a Hand-Object Planner, which can synthesize diverse hand-object trajectories; and (2) HOT, a Hand-Object Tracker that bridges synthetic-to-physical transfer through reinforcement learning and interaction imitation learning, delivering a generalizable controller conditioned on target hand-object states. Our method extends to diverse object shapes and hand morphologies. Through extensive evaluations, we show that our approach enables dexterous hands to track challenging, long-horizon sequences including object re-arrangement and agile in-hand reorientation. These results represent a significant step toward scalable foundation controllers for manipulation that can learn entirely from synthetic data, breaking the data bottleneck that has long constrained progress in dexterous manipulation.
SkillMimic-V2: Learning Robust and Generalizable Interaction Skills from Sparse and Noisy Demonstrations
May 04, 2025We address a fundamental challenge in Reinforcement Learning from Interaction Demonstration (RLID): demonstration noise and coverage limitations. While existing data collection approaches provide valuable interaction demonstrations, they often yield sparse, disconnected, and noisy trajectories that fail to capture the full spectrum of possible skill variations and transitions. Our key insight is that despite noisy and sparse demonstrations, there exist infinite physically feasible trajectories that naturally bridge between demonstrated skills or emerge from their neighboring states, forming a continuous space of possible skill variations and transitions. Building upon this insight, we present two data augmentation techniques: a Stitched Trajectory Graph (STG) that discovers potential transitions between demonstration skills, and a State Transition Field (STF) that establishes unique connections for arbitrary states within the demonstration neighborhood. To enable effective RLID with augmented data, we develop an Adaptive Trajectory Sampling (ATS) strategy for dynamic curriculum generation and a historical encoding mechanism for memory-dependent skill learning. Our approach enables robust skill acquisition that significantly generalizes beyond the reference demonstrations. Extensive experiments across diverse interaction tasks demonstrate substantial improvements over state-of-the-art methods in terms of convergence stability, generalization capability, and recovery robustness.
PhysHOI: Physics-Based Imitation of Dynamic Human-Object Interaction
Dec 07, 2023
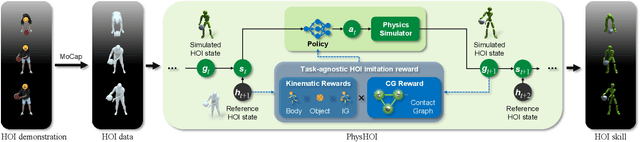

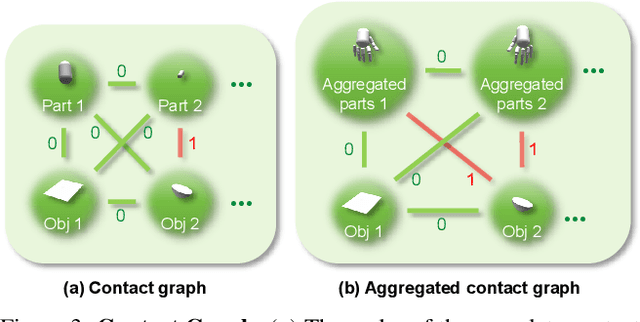
Humans interact with objects all the time. Enabling a humanoid to learn human-object interaction (HOI) is a key step for future smart animation and intelligent robotics systems. However, recent progress in physics-based HOI requires carefully designed task-specific rewards, making the system unscalable and labor-intensive. This work focuses on dynamic HOI imitation: teaching humanoid dynamic interaction skills through imitating kinematic HOI demonstrations. It is quite challenging because of the complexity of the interaction between body parts and objects and the lack of dynamic HOI data. To handle the above issues, we present PhysHOI, the first physics-based whole-body HOI imitation approach without task-specific reward designs. Except for the kinematic HOI representations of humans and objects, we introduce the contact graph to model the contact relations between body parts and objects explicitly. A contact graph reward is also designed, which proved to be critical for precise HOI imitation. Based on the key designs, PhysHOI can imitate diverse HOI tasks simply yet effectively without prior knowledge. To make up for the lack of dynamic HOI scenarios in this area, we introduce the BallPlay dataset that contains eight whole-body basketball skills. We validate PhysHOI on diverse HOI tasks, including whole-body grasping and basketball skills.
DiffLLE: Diffusion-guided Domain Calibration for Unsupervised Low-light Image Enhancement
Aug 18, 2023



Existing unsupervised low-light image enhancement methods lack enough effectiveness and generalization in practical applications. We suppose this is because of the absence of explicit supervision and the inherent gap between real-world scenarios and the training data domain. In this paper, we develop Diffusion-based domain calibration to realize more robust and effective unsupervised Low-Light Enhancement, called DiffLLE. Since the diffusion model performs impressive denoising capability and has been trained on massive clean images, we adopt it to bridge the gap between the real low-light domain and training degradation domain, while providing efficient priors of real-world content for unsupervised models. Specifically, we adopt a naive unsupervised enhancement algorithm to realize preliminary restoration and design two zero-shot plug-and-play modules based on diffusion model to improve generalization and effectiveness. The Diffusion-guided Degradation Calibration (DDC) module narrows the gap between real-world and training low-light degradation through diffusion-based domain calibration and a lightness enhancement curve, which makes the enhancement model perform robustly even in sophisticated wild degradation. Due to the limited enhancement effect of the unsupervised model, we further develop the Fine-grained Target domain Distillation (FTD) module to find a more visual-friendly solution space. It exploits the priors of the pre-trained diffusion model to generate pseudo-references, which shrinks the preliminary restored results from a coarse normal-light domain to a finer high-quality clean field, addressing the lack of strong explicit supervision for unsupervised methods. Benefiting from these, our approach even outperforms some supervised methods by using only a simple unsupervised baseline. Extensive experiments demonstrate the superior effectiveness of the proposed DiffLLE.
FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model
Mar 17, 2023Recently, conditional diffusion models have gained popularity in numerous applications due to their exceptional generation ability. However, many existing methods are training-required. They need to train a time-dependent classifier or a condition-dependent score estimator, which increases the cost of constructing conditional diffusion models and is inconvenient to transfer across different conditions. Some current works aim to overcome this limitation by proposing training-free solutions, but most can only be applied to a specific category of tasks and not to more general conditions. In this work, we propose a training-Free conditional Diffusion Model (FreeDoM) used for various conditions. Specifically, we leverage off-the-shelf pre-trained networks, such as a face detection model, to construct time-independent energy functions, which guide the generation process without requiring training. Furthermore, because the construction of the energy function is very flexible and adaptable to various conditions, our proposed FreeDoM has a broader range of applications than existing training-free methods. FreeDoM is advantageous in its simplicity, effectiveness, and low cost. Experiments demonstrate that FreeDoM is effective for various conditions and suitable for diffusion models of diverse data domains, including image and latent code domains.
Unlimited-Size Diffusion Restoration
Mar 01, 2023



Recently, using diffusion models for zero-shot image restoration (IR) has become a new hot paradigm. This type of method only needs to use the pre-trained off-the-shelf diffusion models, without any finetuning, and can directly handle various IR tasks. The upper limit of the restoration performance depends on the pre-trained diffusion models, which are in rapid evolution. However, current methods only discuss how to deal with fixed-size images, but dealing with images of arbitrary sizes is very important for practical applications. This paper focuses on how to use those diffusion-based zero-shot IR methods to deal with any size while maintaining the excellent characteristics of zero-shot. A simple way to solve arbitrary size is to divide it into fixed-size patches and solve each patch independently. But this may yield significant artifacts since it neither considers the global semantics of all patches nor the local information of adjacent patches. Inspired by the Range-Null space Decomposition, we propose the Mask-Shift Restoration to address local incoherence and propose the Hierarchical Restoration to alleviate out-of-domain issues. Our simple, parameter-free approaches can be used not only for image restoration but also for image generation of unlimited sizes, with the potential to be a general tool for diffusion models. Code: https://github.com/wyhuai/DDNM/tree/main/hq_demo
Position Embedding Needs an Independent Layer Normalization
Dec 22, 2022



The Position Embedding (PE) is critical for Vision Transformers (VTs) due to the permutation-invariance of self-attention operation. By analyzing the input and output of each encoder layer in VTs using reparameterization and visualization, we find that the default PE joining method (simply adding the PE and patch embedding together) operates the same affine transformation to token embedding and PE, which limits the expressiveness of PE and hence constrains the performance of VTs. To overcome this limitation, we propose a simple, effective, and robust method. Specifically, we provide two independent layer normalizations for token embeddings and PE for each layer, and add them together as the input of each layer's Muti-Head Self-Attention module. Since the method allows the model to adaptively adjust the information of PE for different layers, we name it as Layer-adaptive Position Embedding, abbreviated as LaPE. Extensive experiments demonstrate that LaPE can improve various VTs with different types of PE and make VTs robust to PE types. For example, LaPE improves 0.94% accuracy for ViT-Lite on Cifar10, 0.98% for CCT on Cifar100, and 1.72% for DeiT on ImageNet-1K, which is remarkable considering the negligible extra parameters, memory and computational cost brought by LaPE. The code is publicly available at https://github.com/Ingrid725/LaPE.
Zero-Shot Image Restoration Using Denoising Diffusion Null-Space Model
Dec 07, 2022



Most existing Image Restoration (IR) models are task-specific, which can not be generalized to different degradation operators. In this work, we propose the Denoising Diffusion Null-Space Model (DDNM), a novel zero-shot framework for arbitrary linear IR problems, including but not limited to image super-resolution, colorization, inpainting, compressed sensing, and deblurring. DDNM only needs a pre-trained off-the-shelf diffusion model as the generative prior, without any extra training or network modifications. By refining only the null-space contents during the reverse diffusion process, we can yield diverse results satisfying both data consistency and realness. We further propose an enhanced and robust version, dubbed DDNM+, to support noisy restoration and improve restoration quality for hard tasks. Our experiments on several IR tasks reveal that DDNM outperforms other state-of-the-art zero-shot IR methods. We also demonstrate that DDNM+ can solve complex real-world applications, e.g., old photo restoration.
GAN Prior based Null-Space Learning for Consistent Super-Resolution
Nov 24, 2022Consistency and realness have always been the two critical issues of image super-resolution. While the realness has been dramatically improved with the use of GAN prior, the state-of-the-art methods still suffer inconsistencies in local structures and colors (e.g., tooth and eyes). In this paper, we show that these inconsistencies can be analytically eliminated by learning only the null-space component while fixing the range-space part. Further, we design a pooling-based decomposition (PD), a universal range-null space decomposition for super-resolution tasks, which is concise, fast, and parameter-free. PD can be easily applied to state-of-the-art GAN Prior based SR methods to eliminate their inconsistencies, neither compromising the realness nor bringing extra parameters or computational costs. Besides, our ablation studies reveal that PD can replace pixel-wise losses for training and achieve better generalization performance when facing unseen downsamplings or even real-world degradation. Experiments show that the use of PD refreshes state-of-the-art SR performance and speeds up the convergence of training up to 2~10 times.