 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniX: From Unified Panoramic Generation and Perception to Graphics-Ready 3D Scenes
Oct 30, 2025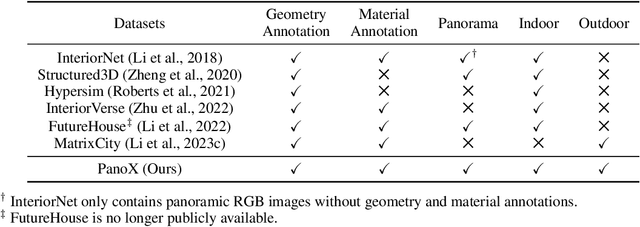

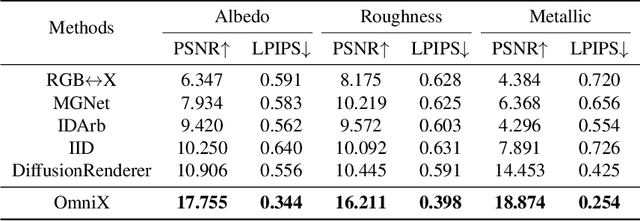
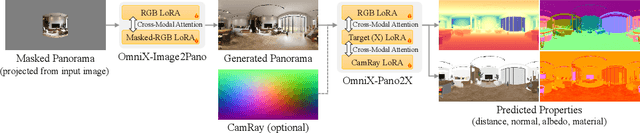
There are two prevalent ways to constructing 3D scenes: procedural generation and 2D lifting. Among them, panorama-based 2D lifting has emerged as a promising technique, leveraging powerful 2D generative priors to produce immersive, realistic, and diverse 3D environments. In this work, we advance this technique to generate graphics-ready 3D scenes suitable for physically based rendering (PBR), relighting, and simulation. Our key insight is to repurpose 2D generative models for panoramic perception of geometry, textures, and PBR materials. Unlike existing 2D lifting approaches that emphasize appearance generation and ignore the perception of intrinsic properties, we present OmniX, a versatile and unified framework. Based on a lightweight and efficient cross-modal adapter structure, OmniX reuses 2D generative priors for a broad range of panoramic vision tasks, including panoramic perception, generation, and completion. Furthermore, we construct a large-scale synthetic panorama dataset containing high-quality multimodal panoramas from diverse indoor and outdoor scenes. Extensive experiments demonstrate the effectiveness of our model in panoramic visual perception and graphics-ready 3D scene generation, opening new possibilities for immersive and physically realistic virtual world generation.
A Survey of Interactive Generative Video
Apr 30, 2025
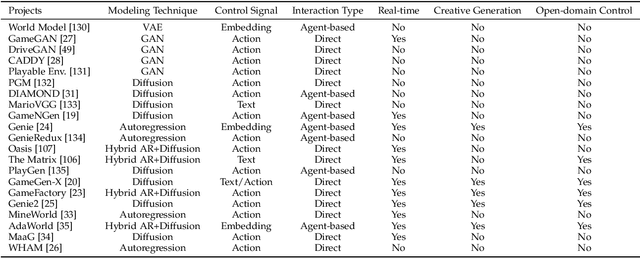


Interactive Generative Video (IGV) has emerged as a crucial technology in response to the growing demand for high-quality, interactive video content across various domains. In this paper, we define IGV as a technology that combines generative capabilities to produce diverse high-quality video content with interactive features that enable user engagement through control signals and responsive feedback. We survey the current landscape of IGV applications, focusing on three major domains: 1) gaming, where IGV enables infinite exploration in virtual worlds; 2) embodied AI, where IGV serves as a physics-aware environment synthesizer for training agents in multimodal interaction with dynamically evolving scenes; and 3) autonomous driving, where IGV provides closed-loop simulation capabilities for safety-critical testing and validation. To guide future development, we propose a comprehensive framework that decomposes an ideal IGV system into five essential modules: Generation, Control, Memory, Dynamics, and Intelligence. Furthermore, we systematically analyze the technical challenges and future directions in realizing each component for an ideal IGV system, such as achieving real-time generation, enabling open-domain control, maintaining long-term coherence, simulating accurate physics, and integrating causal reasoning. We believe that this systematic analysis will facilitate future research and development in the field of IGV, ultimately advancing the technology toward more sophisticated and practical applications.
Position: Interactive Generative Video as Next-Generation Game Engine
Mar 21, 2025Modern game development faces significant challenges in creativity and cost due to predetermined content in traditional game engines. Recent breakthroughs in video generation models, capable of synthesizing realistic and interactive virtual environments, present an opportunity to revolutionize game creation. In this position paper, we propose Interactive Generative Video (IGV) as the foundation for Generative Game Engines (GGE), enabling unlimited novel content generation in next-generation gaming. GGE leverages IGV's unique strengths in unlimited high-quality content synthesis, physics-aware world modeling, user-controlled interactivity, long-term memory capabilities, and causal reasoning. We present a comprehensive framework detailing GGE's core modules and a hierarchical maturity roadmap (L0-L4) to guide its evolution. Our work charts a new course for game development in the AI era, envisioning a future where AI-powered generative systems fundamentally reshape how games are created and experienced.
GameFactory: Creating New Games with Generative Interactive Videos
Jan 14, 2025



Generative game engines have the potential to revolutionize game development by autonomously creating new content and reducing manual workload. However, existing video-based game generation methods fail to address the critical challenge of scene generalization, limiting their applicability to existing games with fixed styles and scenes. In this paper, we present GameFactory, a framework focused on exploring scene generalization in game video generation. To enable the creation of entirely new and diverse games, we leverage pre-trained video diffusion models trained on open-domain video data. To bridge the domain gap between open-domain priors and small-scale game dataset, we propose a multi-phase training strategy that decouples game style learning from action control, preserving open-domain generalization while achieving action controllability. Using Minecraft as our data source, we release GF-Minecraft, a high-quality and diversity action-annotated video dataset for research. Furthermore, we extend our framework to enable autoregressive action-controllable game video generation, allowing the production of unlimited-length interactive game videos. Experimental results demonstrate that GameFactory effectively generates open-domain, diverse, and action-controllable game videos, representing a significant step forward in AI-driven game generation. Our dataset and project page are publicly available at \url{https://vvictoryuki.github.io/gamefactory/}.
WorldSimBench: Towards Video Generation Models as World Simulators
Oct 23, 2024



Recent advancements in predictive models have demonstrated exceptional capabilities in predicting the future state of objects and scenes. However, the lack of categorization based on inherent characteristics continues to hinder the progress of predictive model development. Additionally, existing benchmarks are unable to effectively evaluate higher-capability, highly embodied predictive models from an embodied perspective. In this work, we classify the functionalities of predictive models into a hierarchy and take the first step in evaluating World Simulators by proposing a dual evaluation framework called WorldSimBench. WorldSimBench includes Explicit Perceptual Evaluation and Implicit Manipulative Evaluation, encompassing human preference assessments from the visual perspective and action-level evaluations in embodied tasks, covering three representative embodied scenarios: Open-Ended Embodied Environment, Autonomous, Driving, and Robot Manipulation. In the Explicit Perceptual Evaluation, we introduce the HF-Embodied Dataset, a video assessment dataset based on fine-grained human feedback, which we use to train a Human Preference Evaluator that aligns with human perception and explicitly assesses the visual fidelity of World Simulators. In the Implicit Manipulative Evaluation, we assess the video-action consistency of World Simulators by evaluating whether the generated situation-aware video can be accurately translated into the correct control signals in dynamic environments. Our comprehensive evaluation offers key insights that can drive further innovation in video generation models, positioning World Simulators as a pivotal advancement toward embodied artificial intelligence.
Diffusion-Based Hierarchical Image Steganography
May 19, 2024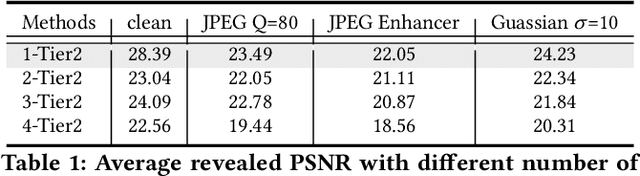
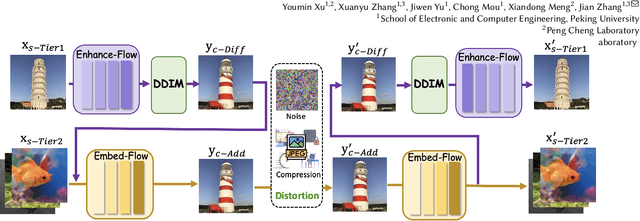


This paper introduces Hierarchical Image Steganography, a novel method that enhances the security and capacity of embedding multiple images into a single container using diffusion models. HIS assigns varying levels of robustness to images based on their importance, ensuring enhanced protection against manipulation. It adaptively exploits the robustness of the Diffusion Model alongside the reversibility of the Flow Model. The integration of Embed-Flow and Enhance-Flow improves embedding efficiency and image recovery quality, respectively, setting HIS apart from conventional multi-image steganography techniques. This innovative structure can autonomously generate a container image, thereby securely and efficiently concealing multiple images and text. Rigorous subjective and objective evaluations underscore our advantage in analytical resistance, robustness, and capacity, illustrating its expansive applicability in content safeguarding and privacy fortification.
V2A-Mark: Versatile Deep Visual-Audio Watermarking for Manipulation Localization and Copyright Protection
Apr 25, 2024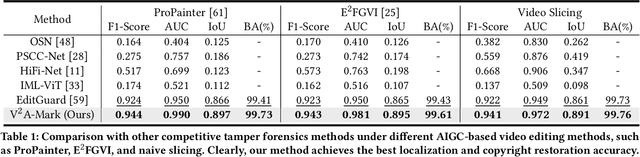
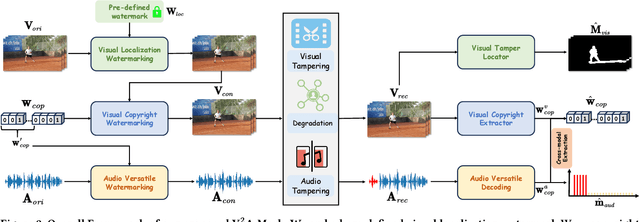
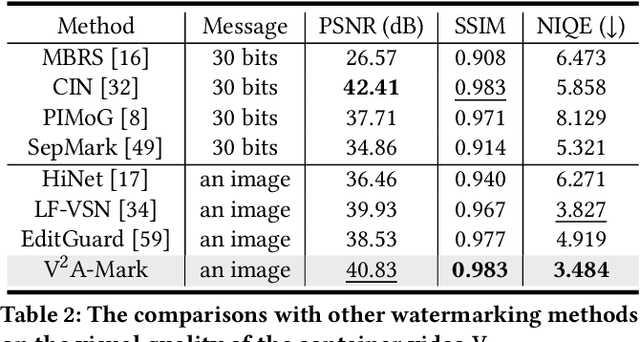
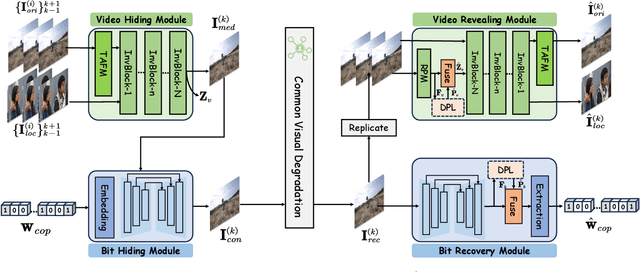
AI-generated video has revolutionized short video production, filmmaking, and personalized media, making video local editing an essential tool. However, this progress also blurs the line between reality and fiction, posing challenges in multimedia forensics. To solve this urgent issue, V2A-Mark is proposed to address the limitations of current video tampering forensics, such as poor generalizability, singular function, and single modality focus. Combining the fragility of video-into-video steganography with deep robust watermarking, our method can embed invisible visual-audio localization watermarks and copyright watermarks into the original video frames and audio, enabling precise manipulation localization and copyright protection. We also design a temporal alignment and fusion module and degradation prompt learning to enhance the localization accuracy and decoding robustness. Meanwhile, we introduce a sample-level audio localization method and a cross-modal copyright extraction mechanism to couple the information of audio and video frames. The effectiveness of V2A-Mark has been verified on a visual-audio tampering dataset, emphasizing its superiority in localization precision and copyright accuracy, crucial for the sustainable development of video editing in the AIGC video era.
Invertible Diffusion Models for Compressed Sensing
Mar 25, 2024While deep neural networks (NN) significantly advance image compressed sensing (CS) by improving reconstruction quality, the necessity of training current CS NNs from scratch constrains their effectiveness and hampers rapid deployment. Although recent methods utilize pre-trained diffusion models for image reconstruction, they struggle with slow inference and restricted adaptability to CS. To tackle these challenges, this paper proposes Invertible Diffusion Models (IDM), a novel efficient, end-to-end diffusion-based CS method. IDM repurposes a large-scale diffusion sampling process as a reconstruction model, and finetunes it end-to-end to recover original images directly from CS measurements, moving beyond the traditional paradigm of one-step noise estimation learning. To enable such memory-intensive end-to-end finetuning, we propose a novel two-level invertible design to transform both (1) the multi-step sampling process and (2) the noise estimation U-Net in each step into invertible networks. As a result, most intermediate features are cleared during training to reduce up to 93.8% GPU memory. In addition, we develop a set of lightweight modules to inject measurements into noise estimator to further facilitate reconstruction. Experiments demonstrate that IDM outperforms existing state-of-the-art CS networks by up to 2.64dB in PSNR. Compared to the recent diffusion model-based approach DDNM, our IDM achieves up to 10.09dB PSNR gain and 14.54 times faster inference.
Neural Video Fields Editing
Dec 12, 2023
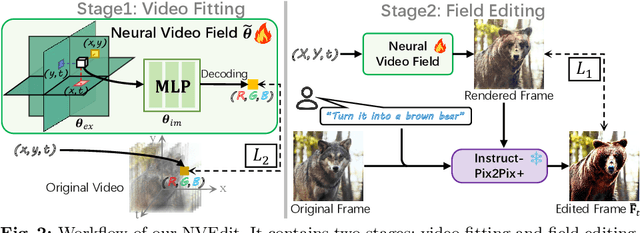


Diffusion models have revolutionized text-driven video editing. However, applying these methods to real-world editing encounters two significant challenges: (1) the rapid increase in graphics memory demand as the number of frames grows, and (2) the inter-frame inconsistency in edited videos. To this end, we propose NVEdit, a novel text-driven video editing framework designed to mitigate memory overhead and improve consistent editing for real-world long videos. Specifically, we construct a neural video field, powered by tri-plane and sparse grid, to enable encoding long videos with hundreds of frames in a memory-efficient manner. Next, we update the video field through off-the-shelf Text-to-Image (T2I) models to impart text-driven editing effects. A progressive optimization strategy is developed to preserve original temporal priors. Importantly, both the neural video field and T2I model are adaptable and replaceable, thus inspiring future research. Experiments demonstrate that our approach successfully edits hundreds of frames with impressive inter-frame consistency.
EditGuard: Versatile Image Watermarking for Tamper Localization and Copyright Protection
Dec 12, 2023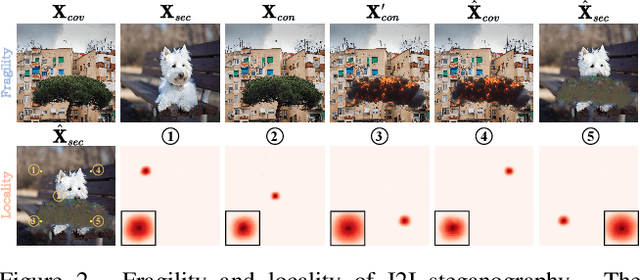
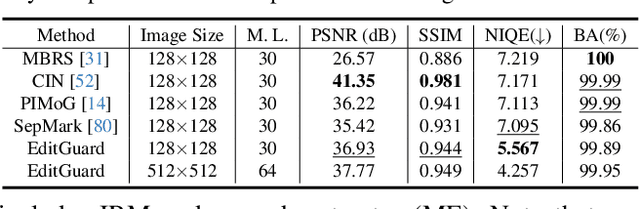
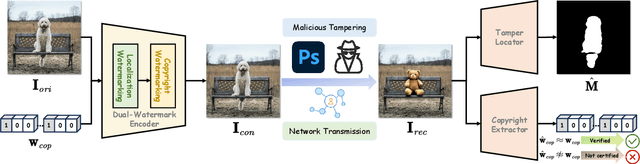
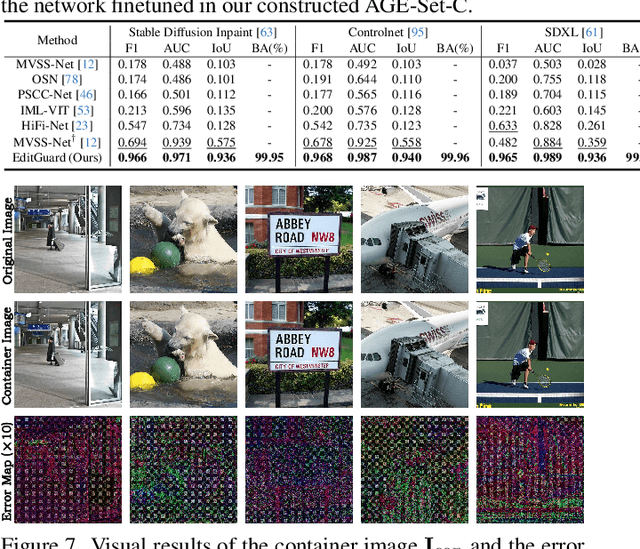
In the era where AI-generated content (AIGC) models can produce stunning and lifelike images, the lingering shadow of unauthorized reproductions and malicious tampering poses imminent threats to copyright integrity and information security. Current image watermarking methods, while widely accepted for safeguarding visual content, can only protect copyright and ensure traceability. They fall short in localizing increasingly realistic image tampering, potentially leading to trust crises, privacy violations, and legal disputes. To solve this challenge, we propose an innovative proactive forensics framework EditGuard, to unify copyright protection and tamper-agnostic localization, especially for AIGC-based editing methods. It can offer a meticulous embedding of imperceptible watermarks and precise decoding of tampered areas and copyright information. Leveraging our observed fragility and locality of image-into-image steganography, the realization of EditGuard can be converted into a united image-bit steganography issue, thus completely decoupling the training process from the tampering types. Extensive experiments demonstrate that our EditGuard balances the tamper localization accuracy, copyright recovery precision, and generalizability to various AIGC-based tampering methods, especially for image forgery that is difficult for the naked eye to detect. The project page is available at https://xuanyuzhang21.github.io/project/editguard/.