 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisionDirector: Vision-Language Guided Closed-Loop Refinement for Generative Image Synthesis
Dec 22, 2025Generative models can now produce photorealistic imagery, yet they still struggle with the long, multi-goal prompts that professional designers issue. To expose this gap and better evaluate models' performance in real-world settings, we introduce Long Goal Bench (LGBench), a 2,000-task suite (1,000 T2I and 1,000 I2I) whose average instruction contains 18 to 22 tightly coupled goals spanning global layout, local object placement, typography, and logo fidelity. We find that even state-of-the-art models satisfy fewer than 72 percent of the goals and routinely miss localized edits, confirming the brittleness of current pipelines. To address this, we present VisionDirector, a training-free vision-language supervisor that (i) extracts structured goals from long instructions, (ii) dynamically decides between one-shot generation and staged edits, (iii) runs micro-grid sampling with semantic verification and rollback after every edit, and (iv) logs goal-level rewards. We further fine-tune the planner with Group Relative Policy Optimization, yielding shorter edit trajectories (3.1 versus 4.2 steps) and stronger alignment. VisionDirector achieves new state of the art on GenEval (plus 7 percent overall) and ImgEdit (plus 0.07 absolute) while producing consistent qualitative improvements on typography, multi-object scenes, and pose editing.
MMMamba: A Versatile Cross-Modal In Context Fusion Framework for Pan-Sharpening and Zero-Shot Image Enhancement
Dec 17, 2025Pan-sharpening aims to generate high-resolution multispectral (HRMS) images by integrating a high-resolution panchromatic (PAN) image with its corresponding low-resolution multispectral (MS) image. To achieve effective fusion, it is crucial to fully exploit the complementary information between the two modalities. Traditional CNN-based methods typically rely on channel-wise concatenation with fixed convolutional operators, which limits their adaptability to diverse spatial and spectral variations. While cross-attention mechanisms enable global interactions, they are computationally inefficient and may dilute fine-grained correspondences, making it difficult to capture complex semantic relationships. Recent advances in the Multimodal Diffusion Transformer (MMDiT) architecture have demonstrated impressive success in image generation and editing tasks. Unlike cross-attention, MMDiT employs in-context conditioning to facilitate more direct and efficient cross-modal information exchange. In this paper, we propose MMMamba, a cross-modal in-context fusion framework for pan-sharpening, with the flexibility to support image super-resolution in a zero-shot manner. Built upon the Mamba architecture, our design ensures linear computational complexity while maintaining strong cross-modal interaction capacity. Furthermore, we introduce a novel multimodal interleaved (MI) scanning mechanism that facilitates effective information exchange between the PAN and MS modalities. Extensive experiments demonstrate the superior performance of our method compared to existing state-of-the-art (SOTA) techniques across multiple tasks and benchmarks.
A Survey of Interactive Generative Video
Apr 30, 2025
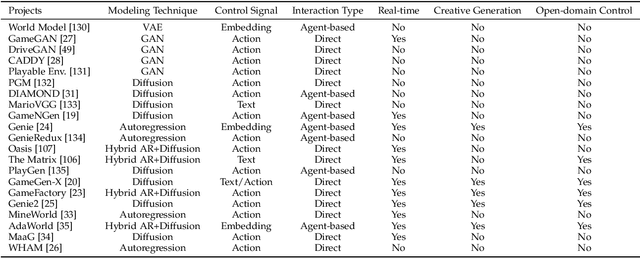


Interactive Generative Video (IGV) has emerged as a crucial technology in response to the growing demand for high-quality, interactive video content across various domains. In this paper, we define IGV as a technology that combines generative capabilities to produce diverse high-quality video content with interactive features that enable user engagement through control signals and responsive feedback. We survey the current landscape of IGV applications, focusing on three major domains: 1) gaming, where IGV enables infinite exploration in virtual worlds; 2) embodied AI, where IGV serves as a physics-aware environment synthesizer for training agents in multimodal interaction with dynamically evolving scenes; and 3) autonomous driving, where IGV provides closed-loop simulation capabilities for safety-critical testing and validation. To guide future development, we propose a comprehensive framework that decomposes an ideal IGV system into five essential modules: Generation, Control, Memory, Dynamics, and Intelligence. Furthermore, we systematically analyze the technical challenges and future directions in realizing each component for an ideal IGV system, such as achieving real-time generation, enabling open-domain control, maintaining long-term coherence, simulating accurate physics, and integrating causal reasoning. We believe that this systematic analysis will facilitate future research and development in the field of IGV, ultimately advancing the technology toward more sophisticated and practical applications.
Position: Interactive Generative Video as Next-Generation Game Engine
Mar 21, 2025Modern game development faces significant challenges in creativity and cost due to predetermined content in traditional game engines. Recent breakthroughs in video generation models, capable of synthesizing realistic and interactive virtual environments, present an opportunity to revolutionize game creation. In this position paper, we propose Interactive Generative Video (IGV) as the foundation for Generative Game Engines (GGE), enabling unlimited novel content generation in next-generation gaming. GGE leverages IGV's unique strengths in unlimited high-quality content synthesis, physics-aware world modeling, user-controlled interactivity, long-term memory capabilities, and causal reasoning. We present a comprehensive framework detailing GGE's core modules and a hierarchical maturity roadmap (L0-L4) to guide its evolution. Our work charts a new course for game development in the AI era, envisioning a future where AI-powered generative systems fundamentally reshape how games are created and experienced.
GameGen-X: Interactive Open-world Game Video Generation
Nov 01, 2024



We introduce GameGen-X, the first diffusion transformer model specifically designed for both generating and interactively controlling open-world game videos. This model facilitates high-quality, open-domain generation by simulating an extensive array of game engine features, such as innovative characters, dynamic environments, complex actions, and diverse events. Additionally, it provides interactive controllability, predicting and altering future content based on the current clip, thus allowing for gameplay simulation. To realize this vision, we first collected and built an Open-World Video Game Dataset from scratch. It is the first and largest dataset for open-world game video generation and control, which comprises over a million diverse gameplay video clips sampling from over 150 games with informative captions from GPT-4o. GameGen-X undergoes a two-stage training process, consisting of foundation model pre-training and instruction tuning. Firstly, the model was pre-trained via text-to-video generation and video continuation, endowing it with the capability for long-sequence, high-quality open-domain game video generation. Further, to achieve interactive controllability, we designed InstructNet to incorporate game-related multi-modal control signal experts. This allows the model to adjust latent representations based on user inputs, unifying character interaction and scene content control for the first time in video generation. During instruction tuning, only the InstructNet is updated while the pre-trained foundation model is frozen, enabling the integration of interactive controllability without loss of diversity and quality of generated video content.
Rethinking Self-training for Semi-supervised Landmark Detection: A Selection-free Approach
Apr 06, 2024



Self-training is a simple yet effective method for semi-supervised learning, during which pseudo-label selection plays an important role for handling confirmation bias. Despite its popularity, applying self-training to landmark detection faces three problems: 1) The selected confident pseudo-labels often contain data bias, which may hurt model performance; 2) It is not easy to decide a proper threshold for sample selection as the localization task can be sensitive to noisy pseudo-labels; 3) coordinate regression does not output confidence, making selection-based self-training infeasible. To address the above issues, we propose Self-Training for Landmark Detection (STLD), a method that does not require explicit pseudo-label selection. Instead, STLD constructs a task curriculum to deal with confirmation bias, which progressively transitions from more confident to less confident tasks over the rounds of self-training. Pseudo pretraining and shrink regression are two essential components for such a curriculum, where the former is the first task of the curriculum for providing a better model initialization and the latter is further added in the later rounds to directly leverage the pseudo-labels in a coarse-to-fine manner. Experiments on three facial and one medical landmark detection benchmark show that STLD outperforms the existing methods consistently in both semi- and omni-supervised settings.
Unpaired Optical Coherence Tomography Angiography Image Super-Resolution via Frequency-Aware Inverse-Consistency GAN
Sep 29, 2023For optical coherence tomography angiography (OCTA) images, a limited scanning rate leads to a trade-off between field-of-view (FOV) and imaging resolution. Although larger FOV images may reveal more parafoveal vascular lesions, their application is greatly hampered due to lower resolution. To increase the resolution, previous works only achieved satisfactory performance by using paired data for training, but real-world applications are limited by the challenge of collecting large-scale paired images. Thus, an unpaired approach is highly demanded. Generative Adversarial Network (GAN) has been commonly used in the unpaired setting, but it may struggle to accurately preserve fine-grained capillary details, which are critical biomarkers for OCTA. In this paper, our approach aspires to preserve these details by leveraging the frequency information, which represents details as high-frequencies ($\textbf{hf}$) and coarse-grained backgrounds as low-frequencies ($\textbf{lf}$). In general, we propose a GAN-based unpaired super-resolution method for OCTA images and exceptionally emphasize $\textbf{hf}$ fine capillaries through a dual-path generator. To facilitate a precise spectrum of the reconstructed image, we also propose a frequency-aware adversarial loss for the discriminator and introduce a frequency-aware focal consistency loss for end-to-end optimization. Experiments show that our method outperforms other state-of-the-art unpaired methods both quantitatively and visually.
Unsupervised Domain Adaptation for Anatomical Landmark Detection
Aug 25, 2023



Recently, anatomical landmark detection has achieved great progresses on single-domain data, which usually assumes training and test sets are from the same domain. However, such an assumption is not always true in practice, which can cause significant performance drop due to domain shift. To tackle this problem, we propose a novel framework for anatomical landmark detection under the setting of unsupervised domain adaptation (UDA), which aims to transfer the knowledge from labeled source domain to unlabeled target domain. The framework leverages self-training and domain adversarial learning to address the domain gap during adaptation. Specifically, a self-training strategy is proposed to select reliable landmark-level pseudo-labels of target domain data with dynamic thresholds, which makes the adaptation more effective. Furthermore, a domain adversarial learning module is designed to handle the unaligned data distributions of two domains by learning domain-invariant features via adversarial training. Our experiments on cephalometric and lung landmark detection show the effectiveness of the method, which reduces the domain gap by a large margin and outperforms other UDA methods consistently. The code is available at https://github.com/jhb86253817/UDA_Med_Landmark.
PromptMRG: Diagnosis-Driven Prompts for Medical Report Generation
Aug 24, 2023



Automatic medical report generation (MRG) is of great research value as it has the potential to relieve radiologists from the heavy burden of report writing. Despite recent advancements, accurate MRG remains challenging due to the need for precise clinical understanding and the identification of clinical findings. Moreover, the imbalanced distribution of diseases makes the challenge even more pronounced, as rare diseases are underrepresented in training data, making their diagnostic performance unreliable. To address these challenges, we propose diagnosis-driven prompts for medical report generation (PromptMRG), a novel framework that aims to improve the diagnostic accuracy of MRG with the guidance of diagnosis-aware prompts. Specifically, PromptMRG is based on encoder-decoder architecture with an extra disease classification branch. When generating reports, the diagnostic results from the classification branch are converted into token prompts to explicitly guide the generation process. To further improve the diagnostic accuracy, we design cross-modal feature enhancement, which retrieves similar reports from the database to assist the diagnosis of a query image by leveraging the knowledge from a pre-trained CLIP. Moreover, the disease imbalanced issue is addressed by applying an adaptive logit-adjusted loss to the classification branch based on the individual learning status of each disease, which overcomes the barrier of text decoder's inability to manipulate disease distributions. Experiments on two MRG benchmarks show the effectiveness of the proposed method, where it obtains state-of-the-art clinical efficacy performance on both datasets.
Towards Generalizable Diabetic Retinopathy Grading in Unseen Domains
Jul 21, 2023Diabetic Retinopathy (DR) is a common complication of diabetes and a leading cause of blindness worldwide. Early and accurate grading of its severity is crucial for disease management. Although deep learning has shown great potential for automated DR grading, its real-world deployment is still challenging due to distribution shifts among source and target domains, known as the domain generalization problem. Existing works have mainly attributed the performance degradation to limited domain shifts caused by simple visual discrepancies, which cannot handle complex real-world scenarios. Instead, we present preliminary evidence suggesting the existence of three-fold generalization issues: visual and degradation style shifts, diagnostic pattern diversity, and data imbalance. To tackle these issues, we propose a novel unified framework named Generalizable Diabetic Retinopathy Grading Network (GDRNet). GDRNet consists of three vital components: fundus visual-artifact augmentation (FundusAug), dynamic hybrid-supervised loss (DahLoss), and domain-class-aware re-balancing (DCR). FundusAug generates realistic augmented images via visual transformation and image degradation, while DahLoss jointly leverages pixel-level consistency and image-level semantics to capture the diverse diagnostic patterns and build generalizable feature representations. Moreover, DCR mitigates the data imbalance from a domain-class view and avoids undesired over-emphasis on rare domain-class pairs. Finally, we design a publicly available benchmark for fair evaluations. Extensive comparison experiments against advanced methods and exhaustive ablation studies demonstrate the effectiveness and generalization ability of GDRNet.