 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising, Fast and Slow: Difficulty-Aware Adaptive Sampling for Image Generation
Apr 21, 2026Diffusion- and flow-based models usually allocate compute uniformly across space, updating all patches with the same timestep and number of function evaluations. While convenient, this ignores the heterogeneity of natural images: some regions are easy to denoise, whereas others benefit from more refinement or additional context. Motivated by this, we explore patch-level noise scales for image synthesis. We find that naively varying timesteps across image tokens performs poorly, as it exposes the model to overly informative training states that do not occur at inference. We therefore introduce a timestep sampler that explicitly controls the maximum patch-level information available during training, and show that moving from global to patch-level timesteps already improves image generation over standard baselines. By further augmenting the model with a lightweight per-patch difficulty head, we enable adaptive samplers that allocate compute dynamically where it is most needed. Combined with noise levels varying over both space and diffusion time, this yields Patch Forcing (PF), a framework that advances easier regions earlier so they can provide context for harder ones. PF achieves superior results on class-conditional ImageNet, remains orthogonal to representation alignment and guidance methods, and scales to text-to-image synthesis. Our results suggest that patch-level denoising schedules provide a promising foundation for adaptive image generation.
Guiding Token-Sparse Diffusion Models
Jan 04, 2026Diffusion models deliver high quality in image synthesis but remain expensive during training and inference. Recent works have leveraged the inherent redundancy in visual content to make training more affordable by training only on a subset of visual information. While these methods were successful in providing cheaper and more effective training, sparsely trained diffusion models struggle in inference. This is due to their lacking response to Classifier-free Guidance (CFG) leading to underwhelming performance during inference. To overcome this, we propose Sparse Guidance (SG). Instead of using conditional dropout as a signal to guide diffusion models, SG uses token-level sparsity. As a result, SG preserves the high-variance of the conditional prediction better, achieving good quality and high variance outputs. Leveraging token-level sparsity at inference, SG improves fidelity at lower compute, achieving 1.58 FID on the commonly used ImageNet-256 benchmark with 25% fewer FLOPs, and yields up to 58% FLOP savings at matched baseline quality. To demonstrate the effectiveness of Sparse Guidance, we train a 2.5B text-to-image diffusion model using training time sparsity and leverage SG during inference. SG achieves improvements in composition and human preference score while increasing throughput at the same time.
TREAD: Token Routing for Efficient Architecture-agnostic Diffusion Training
Jan 08, 2025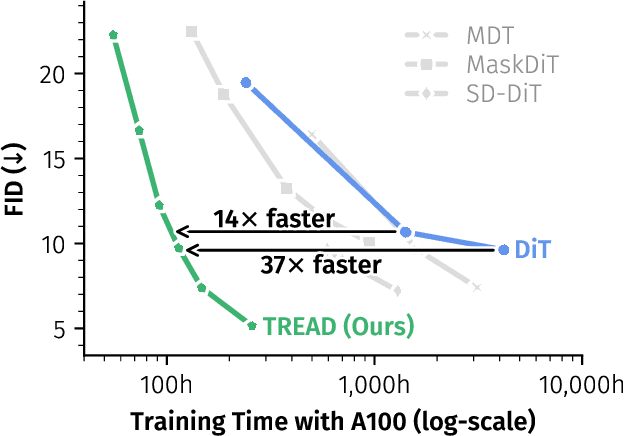
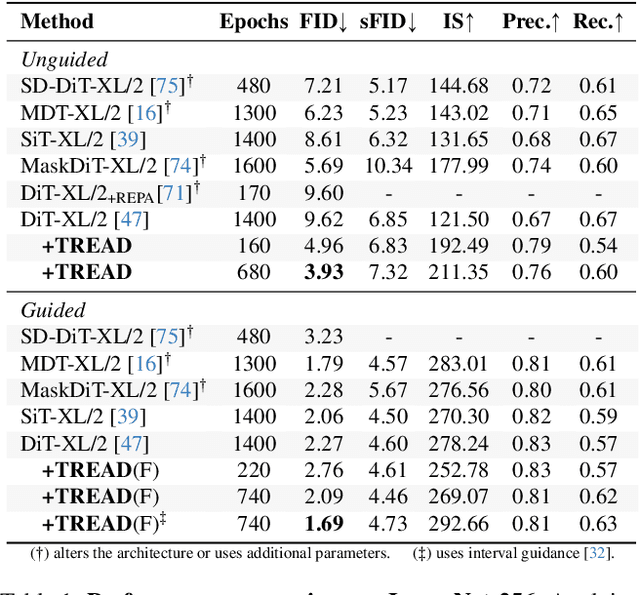

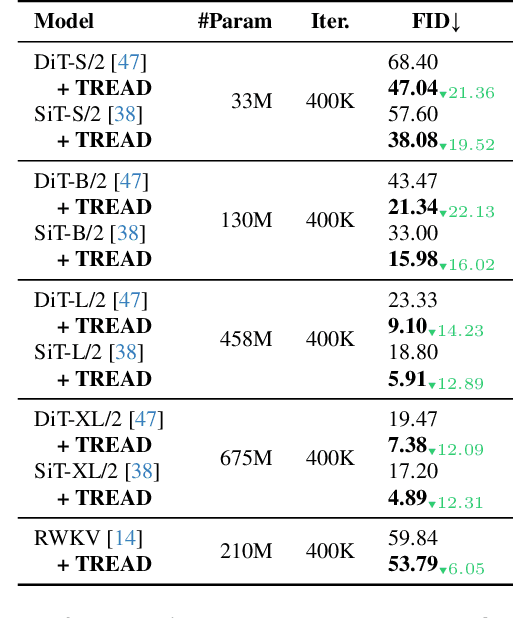
Diffusion models have emerged as the mainstream approach for visual generation. However, these models usually suffer from sample inefficiency and high training costs. This issue is particularly pronounced in the standard diffusion transformer architecture due to its quadratic complexity relative to input length. Recent works have addressed this by reducing the number of tokens processed in the model, often through masking. In contrast, this work aims to improve the training efficiency of the diffusion backbone by using predefined routes that store this information until it is reintroduced to deeper layers of the model, rather than discarding these tokens entirely. Further, we combine multiple routes and introduce an adapted auxiliary loss that accounts for all applied routes. Our method is not limited to the common transformer-based model - it can also be applied to state-space models. Unlike most current approaches, TREAD achieves this without architectural modifications. Finally, we show that our method reduces the computational cost and simultaneously boosts model performance on the standard benchmark ImageNet-1K 256 x 256 in class-conditional synthesis. Both of these benefits multiply to a convergence speedup of 9.55x at 400K training iterations compared to DiT and 25.39x compared to the best benchmark performance of DiT at 7M training iterations.
Continuous, Subject-Specific Attribute Control in T2I Models by Identifying Semantic Directions
Mar 25, 2024In recent years, advances in text-to-image (T2I) diffusion models have substantially elevated the quality of their generated images. However, achieving fine-grained control over attributes remains a challenge due to the limitations of natural language prompts (such as no continuous set of intermediate descriptions existing between ``person'' and ``old person''). Even though many methods were introduced that augment the model or generation process to enable such control, methods that do not require a fixed reference image are limited to either enabling global fine-grained attribute expression control or coarse attribute expression control localized to specific subjects, not both simultaneously. We show that there exist directions in the commonly used token-level CLIP text embeddings that enable fine-grained subject-specific control of high-level attributes in text-to-image models. Based on this observation, we introduce one efficient optimization-free and one robust optimization-based method to identify these directions for specific attributes from contrastive text prompts. We demonstrate that these directions can be used to augment the prompt text input with fine-grained control over attributes of specific subjects in a compositional manner (control over multiple attributes of a single subject) without having to adapt the diffusion model. Project page: https://compvis.github.io/attribute-control. Code is available at https://github.com/CompVis/attribute-control.
DRAC: Diabetic Retinopathy Analysis Challenge with Ultra-Wide Optical Coherence Tomography Angiography Images
Apr 05, 2023



Computer-assisted automatic analysis of diabetic retinopathy (DR) is of great importance in reducing the risks of vision loss and even blindness. Ultra-wide optical coherence tomography angiography (UW-OCTA) is a non-invasive and safe imaging modality in DR diagnosis system, but there is a lack of publicly available benchmarks for model development and evaluation. To promote further research and scientific benchmarking for diabetic retinopathy analysis using UW-OCTA images, we organized a challenge named "DRAC - Diabetic Retinopathy Analysis Challenge" in conjunction with the 25th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2022). The challenge consists of three tasks: segmentation of DR lesions, image quality assessment and DR grading. The scientific community responded positively to the challenge, with 11, 12, and 13 teams from geographically diverse institutes submitting different solutions in these three tasks, respectively. This paper presents a summary and analysis of the top-performing solutions and results for each task of the challenge. The obtained results from top algorithms indicate the importance of data augmentation, model architecture and ensemble of networks in improving the performance of deep learning models. These findings have the potential to enable new developments in diabetic retinopathy analysis. The challenge remains open for post-challenge registrations and submissions for benchmarking future methodology developments.