 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Retrieval for Reasoning-Intensive Retrieval
Jan 08, 2026We study leveraging adaptive retrieval to ensure sufficient "bridge" documents are retrieved for reasoning-intensive retrieval. Bridge documents are those that contribute to the reasoning process yet are not directly relevant to the initial query. While existing reasoning-based reranker pipelines attempt to surface these documents in ranking, they suffer from bounded recall. Naive solution with adaptive retrieval into these pipelines often leads to planning error propagation. To address this, we propose REPAIR, a framework that bridges this gap by repurposing reasoning plans as dense feedback signals for adaptive retrieval. Our key distinction is enabling mid-course correction during reranking through selective adaptive retrieval, retrieving documents that support the pivotal plan. Experimental results on reasoning-intensive retrieval and complex QA tasks demonstrate that our method outperforms existing baselines by 5.6%pt.
Relevance to Utility: Process-Supervised Rewrite for RAG
Sep 19, 2025Retrieval-Augmented Generation systems often suffer from a gap between optimizing retrieval relevance and generative utility: retrieved documents may be topically relevant but still lack the content needed for effective reasoning during generation. While existing "bridge" modules attempt to rewrite the retrieved text for better generation, we show how they fail to capture true document utility. In this work, we propose R2U, with a key distinction of directly optimizing to maximize the probability of generating a correct answer through process supervision. As such direct observation is expensive, we also propose approximating an efficient distillation pipeline by scaling the supervision from LLMs, which helps the smaller rewriter model generalize better. We evaluate our method across multiple open-domain question-answering benchmarks. The empirical results demonstrate consistent improvements over strong bridging baselines.
Leveraging Multimodal LLM for Inspirational User Interface Search
Jan 30, 2025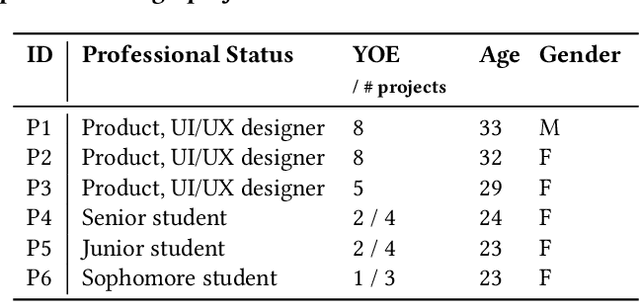
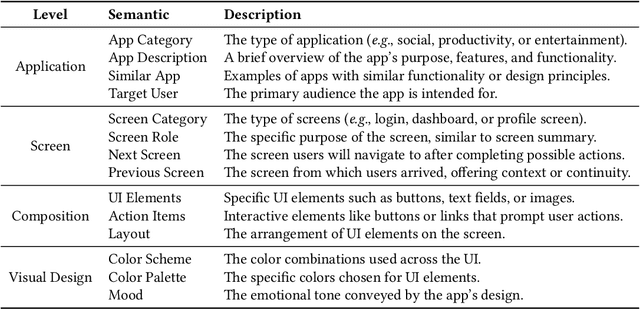

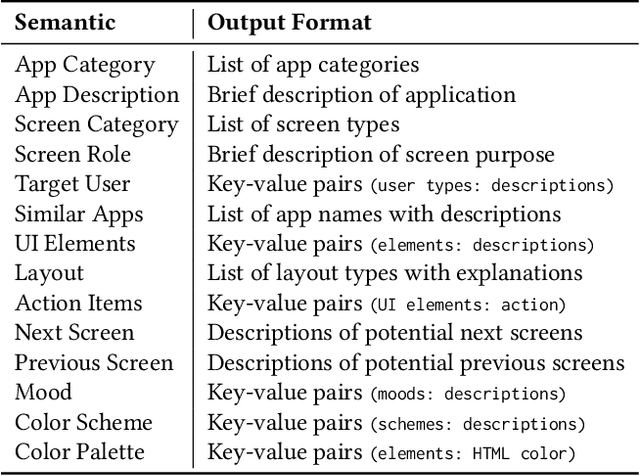
Inspirational search, the process of exploring designs to inform and inspire new creative work, is pivotal in mobile user interface (UI) design. However, exploring the vast space of UI references remains a challenge. Existing AI-based UI search methods often miss crucial semantics like target users or the mood of apps. Additionally, these models typically require metadata like view hierarchies, limiting their practical use. We used a multimodal large language model (MLLM) to extract and interpret semantics from mobile UI images. We identified key UI semantics through a formative study and developed a semantic-based UI search system. Through computational and human evaluations, we demonstrate that our approach significantly outperforms existing UI retrieval methods, offering UI designers a more enriched and contextually relevant search experience. We enhance the understanding of mobile UI design semantics and highlight MLLMs' potential in inspirational search, providing a rich dataset of UI semantics for future studies.
Multi-LLM Collaborative Caption Generation in Scientific Documents
Jan 05, 2025



Scientific figure captioning is a complex task that requires generating contextually appropriate descriptions of visual content. However, existing methods often fall short by utilizing incomplete information, treating the task solely as either an image-to-text or text summarization problem. This limitation hinders the generation of high-quality captions that fully capture the necessary details. Moreover, existing data sourced from arXiv papers contain low-quality captions, posing significant challenges for training large language models (LLMs). In this paper, we introduce a framework called Multi-LLM Collaborative Figure Caption Generation (MLBCAP) to address these challenges by leveraging specialized LLMs for distinct sub-tasks. Our approach unfolds in three key modules: (Quality Assessment) We utilize multimodal LLMs to assess the quality of training data, enabling the filtration of low-quality captions. (Diverse Caption Generation) We then employ a strategy of fine-tuning/prompting multiple LLMs on the captioning task to generate candidate captions. (Judgment) Lastly, we prompt a prominent LLM to select the highest quality caption from the candidates, followed by refining any remaining inaccuracies. Human evaluations demonstrate that informative captions produced by our approach rank better than human-written captions, highlighting its effectiveness. Our code is available at https://github.com/teamreboott/MLBCAP
DALDA: Data Augmentation Leveraging Diffusion Model and LLM with Adaptive Guidance Scaling
Sep 25, 2024



In this paper, we present an effective data augmentation framework leveraging the Large Language Model (LLM) and Diffusion Model (DM) to tackle the challenges inherent in data-scarce scenarios. Recently, DMs have opened up the possibility of generating synthetic images to complement a few training images. However, increasing the diversity of synthetic images also raises the risk of generating samples outside the target distribution. Our approach addresses this issue by embedding novel semantic information into text prompts via LLM and utilizing real images as visual prompts, thus generating semantically rich images. To ensure that the generated images remain within the target distribution, we dynamically adjust the guidance weight based on each image's CLIPScore to control the diversity. Experimental results show that our method produces synthetic images with enhanced diversity while maintaining adherence to the target distribution. Consequently, our approach proves to be more efficient in the few-shot setting on several benchmarks. Our code is available at https://github.com/kkyuhun94/dalda .
Clustering and Mining Accented Speech for Inclusive and Fair Speech Recognition
Aug 05, 2024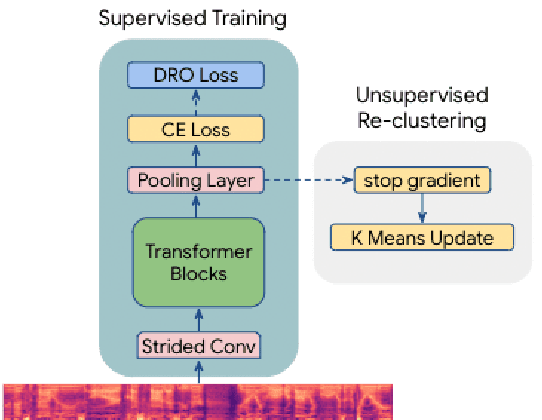
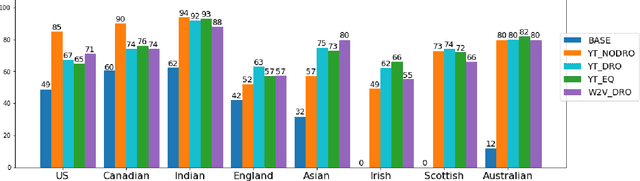

Modern automatic speech recognition (ASR) systems are typically trained on more than tens of thousands hours of speech data, which is one of the main factors for their great success. However, the distribution of such data is typically biased towards common accents or typical speech patterns. As a result, those systems often poorly perform on atypical accented speech. In this paper, we present accent clustering and mining schemes for fair speech recognition systems which can perform equally well on under-represented accented speech. For accent recognition, we applied three schemes to overcome limited size of supervised accent data: supervised or unsupervised pre-training, distributionally robust optimization (DRO) and unsupervised clustering. Three schemes can significantly improve the accent recognition model especially for unbalanced and small accented speech. Fine-tuning ASR on the mined Indian accent speech using the proposed supervised or unsupervised clustering schemes showed 10.0% and 5.3% relative improvements compared to fine-tuning on the randomly sampled speech, respectively.
PhenoFlow: A Human-LLM Driven Visual Analytics System for Exploring Large and Complex Stroke Datasets
Jul 23, 2024

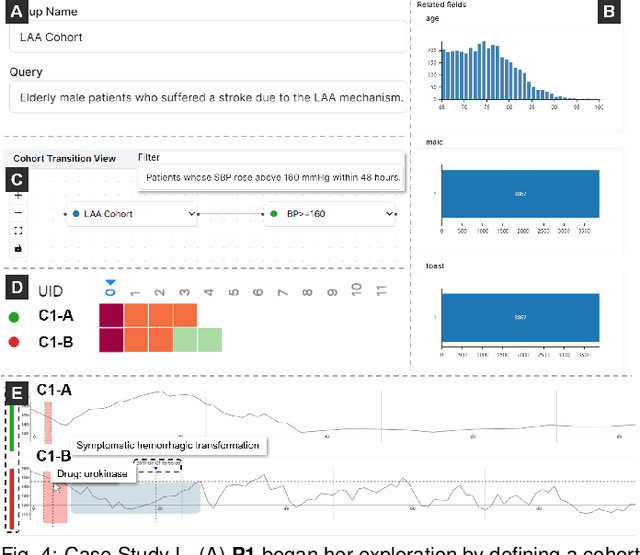
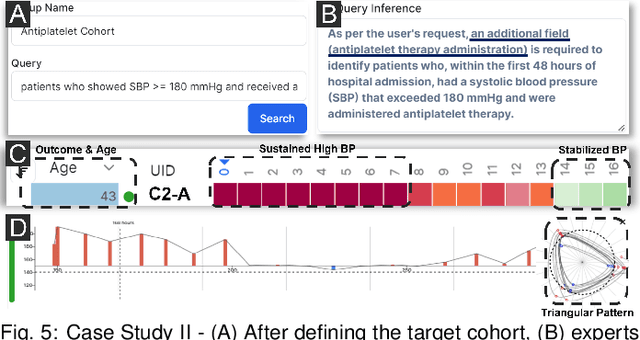
Acute stroke demands prompt diagnosis and treatment to achieve optimal patient outcomes. However, the intricate and irregular nature of clinical data associated with acute stroke, particularly blood pressure (BP) measurements, presents substantial obstacles to effective visual analytics and decision-making. Through a year-long collaboration with experienced neurologists, we developed PhenoFlow, a visual analytics system that leverages the collaboration between human and Large Language Models (LLMs) to analyze the extensive and complex data of acute ischemic stroke patients. PhenoFlow pioneers an innovative workflow, where the LLM serves as a data wrangler while neurologists explore and supervise the output using visualizations and natural language interactions. This approach enables neurologists to focus more on decision-making with reduced cognitive load. To protect sensitive patient information, PhenoFlow only utilizes metadata to make inferences and synthesize executable codes, without accessing raw patient data. This ensures that the results are both reproducible and interpretable while maintaining patient privacy. The system incorporates a slice-and-wrap design that employs temporal folding to create an overlaid circular visualization. Combined with a linear bar graph, this design aids in exploring meaningful patterns within irregularly measured BP data. Through case studies, PhenoFlow has demonstrated its capability to support iterative analysis of extensive clinical datasets, reducing cognitive load and enabling neurologists to make well-informed decisions. Grounded in long-term collaboration with domain experts, our research demonstrates the potential of utilizing LLMs to tackle current challenges in data-driven clinical decision-making for acute ischemic stroke patients.
Pseudo Outlier Exposure for Out-of-Distribution Detection using Pretrained Transformers
Jul 19, 2023For real-world language applications, detecting an out-of-distribution (OOD) sample is helpful to alert users or reject such unreliable samples. However, modern over-parameterized language models often produce overconfident predictions for both in-distribution (ID) and OOD samples. In particular, language models suffer from OOD samples with a similar semantic representation to ID samples since these OOD samples lie near the ID manifold. A rejection network can be trained with ID and diverse outlier samples to detect test OOD samples, but explicitly collecting auxiliary OOD datasets brings an additional burden for data collection. In this paper, we propose a simple but effective method called Pseudo Outlier Exposure (POE) that constructs a surrogate OOD dataset by sequentially masking tokens related to ID classes. The surrogate OOD sample introduced by POE shows a similar representation to ID data, which is most effective in training a rejection network. Our method does not require any external OOD data and can be easily implemented within off-the-shelf Transformers. A comprehensive comparison with state-of-the-art algorithms demonstrates POE's competitiveness on several text classification benchmarks.
* 12 pages, 2 figures
DRAC: Diabetic Retinopathy Analysis Challenge with Ultra-Wide Optical Coherence Tomography Angiography Images
Apr 05, 2023



Computer-assisted automatic analysis of diabetic retinopathy (DR) is of great importance in reducing the risks of vision loss and even blindness. Ultra-wide optical coherence tomography angiography (UW-OCTA) is a non-invasive and safe imaging modality in DR diagnosis system, but there is a lack of publicly available benchmarks for model development and evaluation. To promote further research and scientific benchmarking for diabetic retinopathy analysis using UW-OCTA images, we organized a challenge named "DRAC - Diabetic Retinopathy Analysis Challenge" in conjunction with the 25th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2022). The challenge consists of three tasks: segmentation of DR lesions, image quality assessment and DR grading. The scientific community responded positively to the challenge, with 11, 12, and 13 teams from geographically diverse institutes submitting different solutions in these three tasks, respectively. This paper presents a summary and analysis of the top-performing solutions and results for each task of the challenge. The obtained results from top algorithms indicate the importance of data augmentation, model architecture and ensemble of networks in improving the performance of deep learning models. These findings have the potential to enable new developments in diabetic retinopathy analysis. The challenge remains open for post-challenge registrations and submissions for benchmarking future methodology developments.
Bag of Tricks for In-Distribution Calibration of Pretrained Transformers
Feb 13, 2023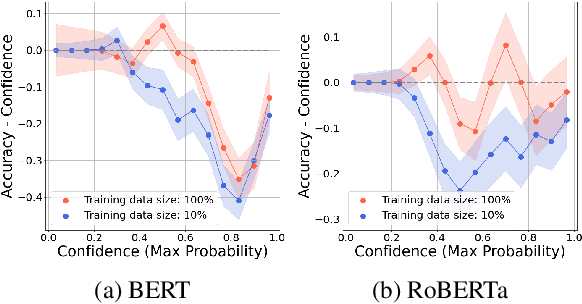
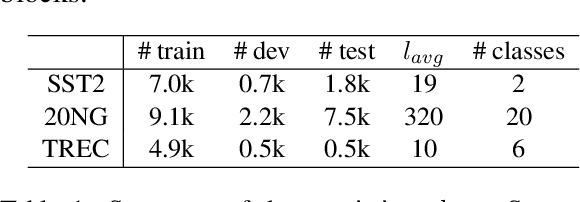
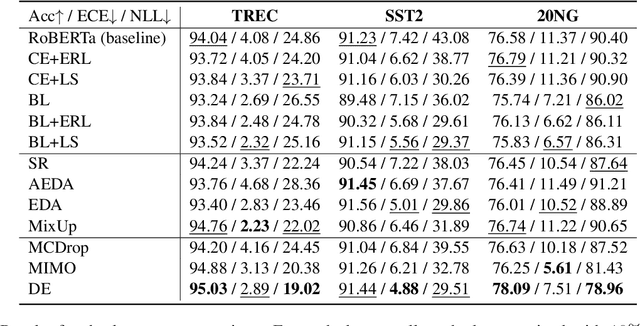
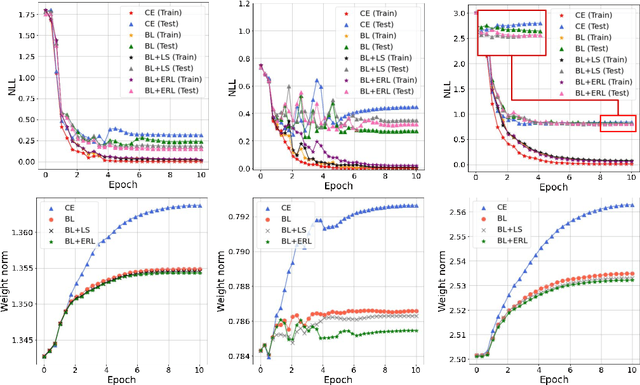
While pre-trained language models (PLMs) have become a de-facto standard promoting the accuracy of text classification tasks, recent studies find that PLMs often predict over-confidently. Although various calibration methods have been proposed, such as ensemble learning and data augmentation, most of the methods have been verified in computer vision benchmarks rather than in PLM-based text classification tasks. In this paper, we present an empirical study on confidence calibration for PLMs, addressing three categories, including confidence penalty losses, data augmentations, and ensemble methods. We find that the ensemble model overfitted to the training set shows sub-par calibration performance and also observe that PLMs trained with confidence penalty loss have a trade-off between calibration and accuracy. Building on these observations, we propose the Calibrated PLM (CALL), a combination of calibration techniques. The CALL complements the drawbacks that may occur when utilizing a calibration method individually and boosts both classification and calibration accuracy. Design choices in CALL's training procedures are extensively studied, and we provide a detailed analysis of how calibration techniques affect the calibration performance of PLMs.