 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensionality Reduction Considered Harmful (Some of the Time)
Dec 20, 2025Visual analytics now plays a central role in decision-making across diverse disciplines, but it can be unreliable: the knowledge or insights derived from the analysis may not accurately reflect the underlying data. In this dissertation, we improve the reliability of visual analytics with a focus on dimensionality reduction (DR). DR techniques enable visual analysis of high-dimensional data by reducing it to two or three dimensions, but they inherently introduce errors that can compromise the reliability of visual analytics. To this end, I investigate reliability challenges that practitioners face when using DR for visual analytics. Then, I propose technical solutions to address these challenges, including new evaluation metrics, optimization strategies, and interaction techniques. We conclude the thesis by discussing how our contributions lay the foundation for achieving more reliable visual analytics practices.
InFerActive: Towards Scalable Human Evaluation of Large Language Models through Interactive Inference
Dec 11, 2025Human evaluation remains the gold standard for evaluating outputs of Large Language Models (LLMs). The current evaluation paradigm reviews numerous individual responses, leading to significant scalability challenges. LLM outputs can be more efficiently represented as a tree structure, reflecting their autoregressive generation process and stochastic token selection. However, conventional tree visualization cannot scale to the exponentially large trees generated by modern sampling methods of LLMs. To address this problem, we present InFerActive, an interactive inference system for scalable human evaluation. InFerActive enables on-demand exploration through probability-based filtering and evaluation features, while bridging the semantic gap between computational tokens and human-readable text through adaptive visualization techniques. Through a technical evaluation and user study (N=12), we demonstrate that InFerActive significantly improves evaluation efficiency and enables more comprehensive assessment of model behavior. We further conduct expert case studies that demonstrate InFerActive's practical applicability and potential for transforming LLM evaluation workflows.
Understanding Bias in Perceiving Dimensionality Reduction Projections
Jul 28, 2025Selecting the dimensionality reduction technique that faithfully represents the structure is essential for reliable visual communication and analytics. In reality, however, practitioners favor projections for other attractions, such as aesthetics and visual saliency, over the projection's structural faithfulness, a bias we define as visual interestingness. In this research, we conduct a user study that (1) verifies the existence of such bias and (2) explains why the bias exists. Our study suggests that visual interestingness biases practitioners' preferences when selecting projections for analysis, and this bias intensifies with color-encoded labels and shorter exposure time. Based on our findings, we discuss strategies to mitigate bias in perceiving and interpreting DR projections.
Dataset-Adaptive Dimensionality Reduction
Jul 16, 2025
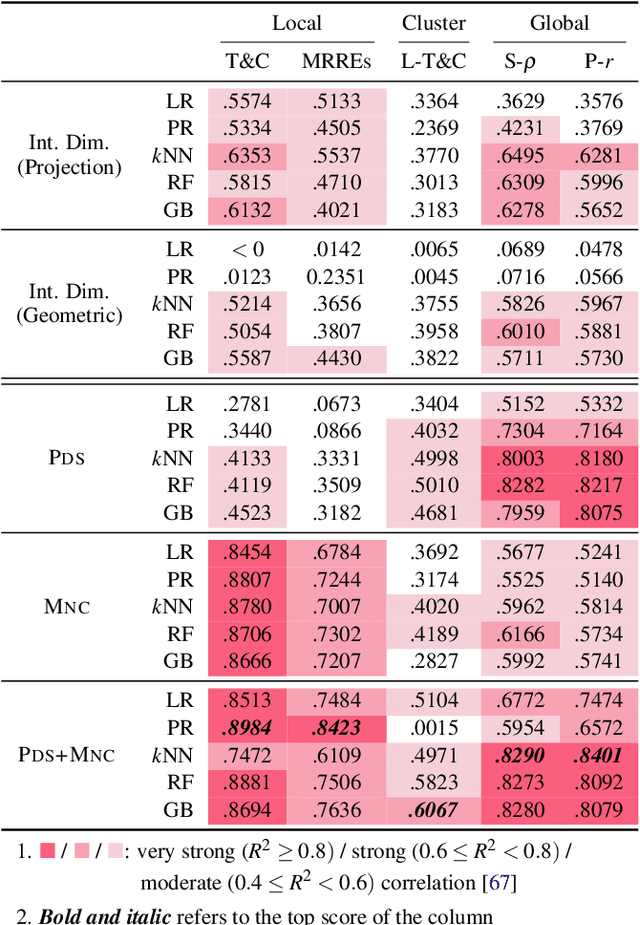


Selecting the appropriate dimensionality reduction (DR) technique and determining its optimal hyperparameter settings that maximize the accuracy of the output projections typically involves extensive trial and error, often resulting in unnecessary computational overhead. To address this challenge, we propose a dataset-adaptive approach to DR optimization guided by structural complexity metrics. These metrics quantify the intrinsic complexity of a dataset, predicting whether higher-dimensional spaces are necessary to represent it accurately. Since complex datasets are often inaccurately represented in two-dimensional projections, leveraging these metrics enables us to predict the maximum achievable accuracy of DR techniques for a given dataset, eliminating redundant trials in optimizing DR. We introduce the design and theoretical foundations of these structural complexity metrics. We quantitatively verify that our metrics effectively approximate the ground truth complexity of datasets and confirm their suitability for guiding dataset-adaptive DR workflow. Finally, we empirically show that our dataset-adaptive workflow significantly enhances the efficiency of DR optimization without compromising accuracy.
Metric Design != Metric Behavior: Improving Metric Selection for the Unbiased Evaluation of Dimensionality Reduction
Jul 03, 2025Evaluating the accuracy of dimensionality reduction (DR) projections in preserving the structure of high-dimensional data is crucial for reliable visual analytics. Diverse evaluation metrics targeting different structural characteristics have thus been developed. However, evaluations of DR projections can become biased if highly correlated metrics--those measuring similar structural characteristics--are inadvertently selected, favoring DR techniques that emphasize those characteristics. To address this issue, we propose a novel workflow that reduces bias in the selection of evaluation metrics by clustering metrics based on their empirical correlations rather than on their intended design characteristics alone. Our workflow works by computing metric similarity using pairwise correlations, clustering metrics to minimize overlap, and selecting a representative metric from each cluster. Quantitative experiments demonstrate that our approach improves the stability of DR evaluation, which indicates that our workflow contributes to mitigating evaluation bias.
Stop Misusing t-SNE and UMAP for Visual Analytics
Jun 10, 2025



Misuses of t-SNE and UMAP in visual analytics have become increasingly common. For example, although t-SNE and UMAP projections often do not faithfully reflect true distances between clusters, practitioners frequently use them to investigate inter-cluster relationships. In this paper, we bring this issue to the surface and comprehensively investigate why such misuse occurs and how to prevent it. We conduct a literature review of 114 papers to verify the prevalence of the misuse and analyze the reasonings behind it. We then execute an interview study to uncover practitioners' implicit motivations for using these techniques -- rationales often undisclosed in the literature. Our findings indicate that misuse of t-SNE and UMAP primarily stems from limited discourse on their appropriate use in visual analytics. We conclude by proposing future directions and concrete action items to promote more reasonable use of DR.
Data Therapist: Eliciting Domain Knowledge from Subject Matter Experts Using Large Language Models
May 01, 2025



Effective data visualization requires not only technical proficiency but also a deep understanding of the domain-specific context in which data exists. This context often includes tacit knowledge about data provenance, quality, and intended use, which is rarely explicit in the dataset itself. We present the Data Therapist, a web-based tool that helps domain experts externalize this implicit knowledge through a mixed-initiative process combining iterative Q&A with interactive annotation. Powered by a large language model, the system analyzes user-supplied datasets, prompts users with targeted questions, and allows annotation at varying levels of granularity. The resulting structured knowledge base can inform both human and automated visualization design. We evaluated the tool in a qualitative study involving expert pairs from Molecular Biology, Accounting, Political Science, and Usable Security. The study revealed recurring patterns in how experts reason about their data and highlights areas where AI support can improve visualization design.
Measuring the Validity of Clustering Validation Datasets
Mar 03, 2025



Clustering techniques are often validated using benchmark datasets where class labels are used as ground-truth clusters. However, depending on the datasets, class labels may not align with the actual data clusters, and such misalignment hampers accurate validation. Therefore, it is essential to evaluate and compare datasets regarding their cluster-label matching (CLM), i.e., how well their class labels match actual clusters. Internal validation measures (IVMs), like Silhouette, can compare CLM over different labeling of the same dataset, but are not designed to do so across different datasets. We thus introduce Adjusted IVMs as fast and reliable methods to evaluate and compare CLM across datasets. We establish four axioms that require validation measures to be independent of data properties not related to cluster structure (e.g., dimensionality, dataset size). Then, we develop standardized protocols to convert any IVM to satisfy these axioms, and use these protocols to adjust six widely used IVMs. Quantitative experiments (1) verify the necessity and effectiveness of our protocols and (2) show that adjusted IVMs outperform the competitors, including standard IVMs, in accurately evaluating CLM both within and across datasets. We also show that the datasets can be filtered or improved using our method to form more reliable benchmarks for clustering validation.
PhenoFlow: A Human-LLM Driven Visual Analytics System for Exploring Large and Complex Stroke Datasets
Jul 23, 2024

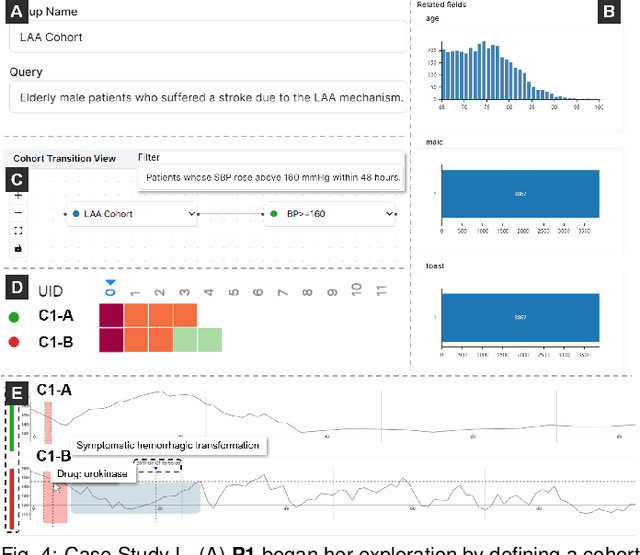
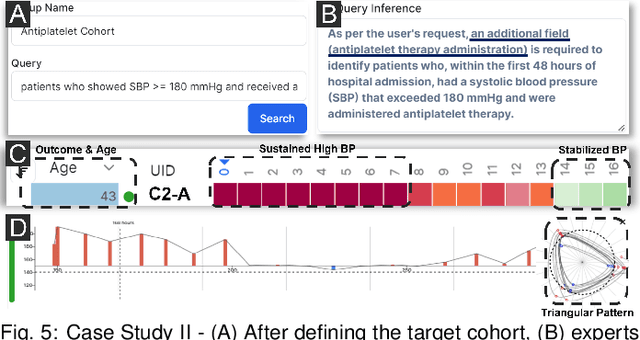
Acute stroke demands prompt diagnosis and treatment to achieve optimal patient outcomes. However, the intricate and irregular nature of clinical data associated with acute stroke, particularly blood pressure (BP) measurements, presents substantial obstacles to effective visual analytics and decision-making. Through a year-long collaboration with experienced neurologists, we developed PhenoFlow, a visual analytics system that leverages the collaboration between human and Large Language Models (LLMs) to analyze the extensive and complex data of acute ischemic stroke patients. PhenoFlow pioneers an innovative workflow, where the LLM serves as a data wrangler while neurologists explore and supervise the output using visualizations and natural language interactions. This approach enables neurologists to focus more on decision-making with reduced cognitive load. To protect sensitive patient information, PhenoFlow only utilizes metadata to make inferences and synthesize executable codes, without accessing raw patient data. This ensures that the results are both reproducible and interpretable while maintaining patient privacy. The system incorporates a slice-and-wrap design that employs temporal folding to create an overlaid circular visualization. Combined with a linear bar graph, this design aids in exploring meaningful patterns within irregularly measured BP data. Through case studies, PhenoFlow has demonstrated its capability to support iterative analysis of extensive clinical datasets, reducing cognitive load and enabling neurologists to make well-informed decisions. Grounded in long-term collaboration with domain experts, our research demonstrates the potential of utilizing LLMs to tackle current challenges in data-driven clinical decision-making for acute ischemic stroke patients.
Extracting Human Attention through Crowdsourced Patch Labeling
Mar 22, 2024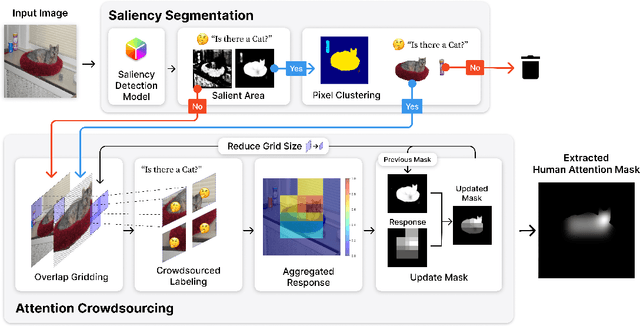


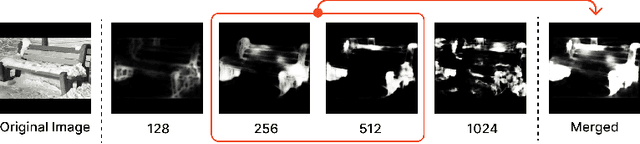
In image classification, a significant problem arises from bias in the datasets. When it contains only specific types of images, the classifier begins to rely on shortcuts - simplistic and erroneous rules for decision-making. This leads to high performance on the training dataset but inferior results on new, varied images, as the classifier's generalization capability is reduced. For example, if the images labeled as mustache consist solely of male figures, the model may inadvertently learn to classify images by gender rather than the presence of a mustache. One approach to mitigate such biases is to direct the model's attention toward the target object's location, usually marked using bounding boxes or polygons for annotation. However, collecting such annotations requires substantial time and human effort. Therefore, we propose a novel patch-labeling method that integrates AI assistance with crowdsourcing to capture human attention from images, which can be a viable solution for mitigating bias. Our method consists of two steps. First, we extract the approximate location of a target using a pre-trained saliency detection model supplemented by human verification for accuracy. Then, we determine the human-attentive area in the image by iteratively dividing the image into smaller patches and employing crowdsourcing to ascertain whether each patch can be classified as the target object. We demonstrated the effectiveness of our method in mitigating bias through improved classification accuracy and the refined focus of the model. Also, crowdsourced experiments validate that our method collects human annotation up to 3.4 times faster than annotating object locations with polygons, significantly reducing the need for human resources. We conclude the paper by discussing the advantages of our method in a crowdsourcing context, mainly focusing on aspects of human errors and accessibility.