 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEHME: A Vision-Language Model For Evaluating Handwritten Mathematics Expressions
Oct 26, 2025Automatically assessing handwritten mathematical solutions is an important problem in educational technology with practical applications, but it remains a significant challenge due to the diverse formats, unstructured layouts, and symbolic complexity of student work. To address this challenge, we introduce VEHME-a Vision-Language Model for Evaluating Handwritten Mathematics Expressions-designed to assess open-form handwritten math responses with high accuracy and interpretable reasoning traces. VEHME integrates a two-phase training pipeline: (i) supervised fine-tuning using structured reasoning data, and (ii) reinforcement learning that aligns model outputs with multi-dimensional grading objectives, including correctness, reasoning depth, and error localization. To enhance spatial understanding, we propose an Expression-Aware Visual Prompting Module, trained on our synthesized multi-line math expressions dataset to robustly guide attention in visually heterogeneous inputs. Evaluated on AIHub and FERMAT datasets, VEHME achieves state-of-the-art performance among open-source models and approaches the accuracy of proprietary systems, demonstrating its potential as a scalable and accessible tool for automated math assessment. Our training and experiment code is publicly available at our GitHub repository.
From Patterns to Predictions: A Shapelet-Based Framework for Directional Forecasting in Noisy Financial Markets
Sep 18, 2025Directional forecasting in financial markets requires both accuracy and interpretability. Before the advent of deep learning, interpretable approaches based on human-defined patterns were prevalent, but their structural vagueness and scale ambiguity hindered generalization. In contrast, deep learning models can effectively capture complex dynamics, yet often offer limited transparency. To bridge this gap, we propose a two-stage framework that integrates unsupervised pattern extracion with interpretable forecasting. (i) SIMPC segments and clusters multivariate time series, extracting recurrent patterns that are invariant to amplitude scaling and temporal distortion, even under varying window sizes. (ii) JISC-Net is a shapelet-based classifier that uses the initial part of extracted patterns as input and forecasts subsequent partial sequences for short-term directional movement. Experiments on Bitcoin and three S&P 500 equities demonstrate that our method ranks first or second in 11 out of 12 metric--dataset combinations, consistently outperforming baselines. Unlike conventional deep learning models that output buy-or-sell signals without interpretable justification, our approach enables transparent decision-making by revealing the underlying pattern structures that drive predictive outcomes.
TESTAM: A Time-Enhanced Spatio-Temporal Attention Model with Mixture of Experts
Mar 05, 2024



Accurate traffic forecasting is challenging due to the complex dependency on road networks, various types of roads, and the abrupt speed change due to the events. Recent works mainly focus on dynamic spatial modeling with adaptive graph embedding or graph attention having less consideration for temporal characteristics and in-situ modeling. In this paper, we propose a novel deep learning model named TESTAM, which individually models recurring and non-recurring traffic patterns by a mixture-of-experts model with three experts on temporal modeling, spatio-temporal modeling with static graph, and dynamic spatio-temporal dependency modeling with dynamic graph. By introducing different experts and properly routing them, TESTAM could better model various circumstances, including spatially isolated nodes, highly related nodes, and recurring and non-recurring events. For the proper routing, we reformulate a gating problem into a classification problem with pseudo labels. Experimental results on three public traffic network datasets, METR-LA, PEMS-BAY, and EXPY-TKY, demonstrate that TESTAM achieves a better indication and modeling of recurring and non-recurring traffic. We published the official code at https://github.com/HyunWookL/TESTAM
* 19 pages, 7 figures, Accepted as poster to ICLR 2024. Code: https://github.com/HyunWookL/TESTAM
CLAMS: A Cluster Ambiguity Measure for Estimating Perceptual Variability in Visual Clustering
Aug 11, 2023Visual clustering is a common perceptual task in scatterplots that supports diverse analytics tasks (e.g., cluster identification). However, even with the same scatterplot, the ways of perceiving clusters (i.e., conducting visual clustering) can differ due to the differences among individuals and ambiguous cluster boundaries. Although such perceptual variability casts doubt on the reliability of data analysis based on visual clustering, we lack a systematic way to efficiently assess this variability. In this research, we study perceptual variability in conducting visual clustering, which we call Cluster Ambiguity. To this end, we introduce CLAMS, a data-driven visual quality measure for automatically predicting cluster ambiguity in monochrome scatterplots. We first conduct a qualitative study to identify key factors that affect the visual separation of clusters (e.g., proximity or size difference between clusters). Based on study findings, we deploy a regression module that estimates the human-judged separability of two clusters. Then, CLAMS predicts cluster ambiguity by analyzing the aggregated results of all pairwise separability between clusters that are generated by the module. CLAMS outperforms widely-used clustering techniques in predicting ground truth cluster ambiguity. Meanwhile, CLAMS exhibits performance on par with human annotators. We conclude our work by presenting two applications for optimizing and benchmarking data mining techniques using CLAMS. The interactive demo of CLAMS is available at clusterambiguity.dev.
TILDE-Q: A Transformation Invariant Loss Function for Time-Series Forecasting
Oct 26, 2022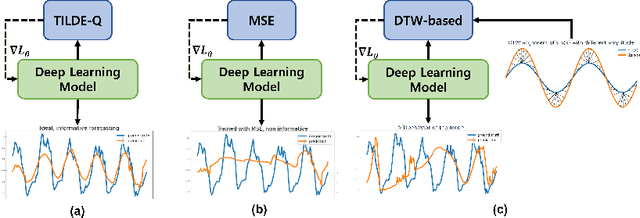

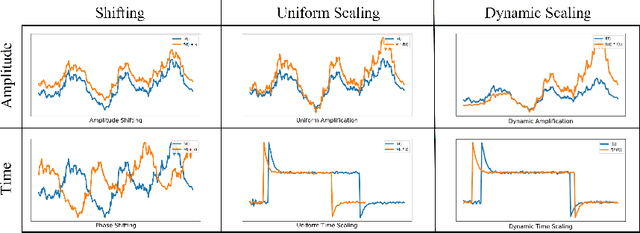
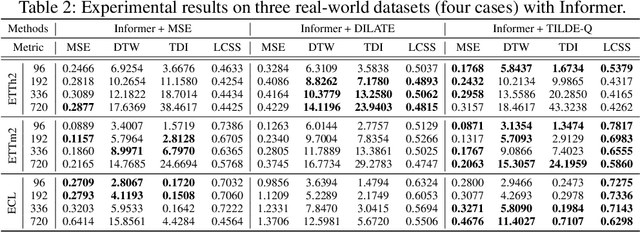
Time-series forecasting has caught increasing attention in the AI research field due to its importance in solving real-world problems across different domains, such as energy, weather, traffic, and economy. As shown in various types of data, it has been a must-see issue to deal with drastic changes, temporal patterns, and shapes in sequential data that previous models are weak in prediction. This is because most cases in time-series forecasting aim to minimize $L_p$ norm distances as loss functions, such as mean absolute error (MAE) or mean square error (MSE). These loss functions are vulnerable to not only considering temporal dynamics modeling but also capturing the shape of signals. In addition, these functions often make models misbehave and return uncorrelated results to the original time-series. To become an effective loss function, it has to be invariant to the set of distortions between two time-series data instead of just comparing exact values. In this paper, we propose a novel loss function, called TILDE-Q (Transformation Invariant Loss function with Distance EQuilibrium), that not only considers the distortions in amplitude and phase but also allows models to capture the shape of time-series sequences. In addition, TILDE-Q supports modeling periodic and non-periodic temporal dynamics at the same time. We evaluate the effectiveness of TILDE-Q by conducting extensive experiments with respect to periodic and non-periodic conditions of data, from naive models to state-of-the-art models. The experiment results indicate that the models trained with TILDE-Q outperform those trained with other training metrics (e.g., MSE, dynamic time warping (DTW), temporal distortion index (TDI), and longest common subsequence (LCSS)).
A Visual Analytics System for Improving Attention-based Traffic Forecasting Models
Aug 11, 2022
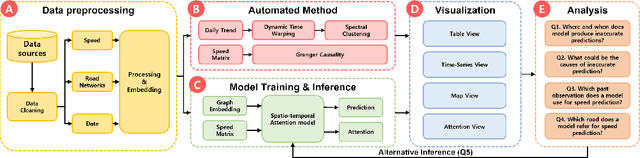
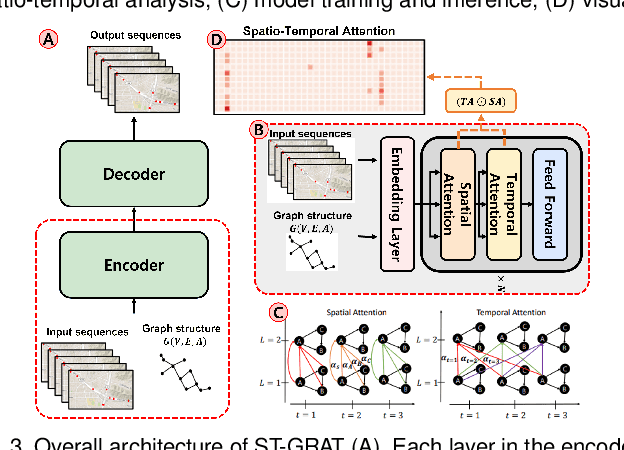
With deep learning (DL) outperforming conventional methods for different tasks, much effort has been devoted to utilizing DL in various domains. Researchers and developers in the traffic domain have also designed and improved DL models for forecasting tasks such as estimation of traffic speed and time of arrival. However, there exist many challenges in analyzing DL models due to the black-box property of DL models and complexity of traffic data (i.e., spatio-temporal dependencies). Collaborating with domain experts, we design a visual analytics system, AttnAnalyzer, that enables users to explore how DL models make predictions by allowing effective spatio-temporal dependency analysis. The system incorporates dynamic time warping (DTW) and Granger causality tests for computational spatio-temporal dependency analysis while providing map, table, line chart, and pixel views to assist user to perform dependency and model behavior analysis. For the evaluation, we present three case studies showing how AttnAnalyzer can effectively explore model behaviors and improve model performance in two different road networks. We also provide domain expert feedback.
Learning to Remember Patterns: Pattern Matching Memory Networks for Traffic Forecasting
Oct 20, 2021

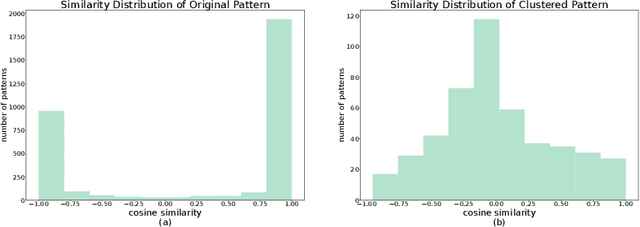

Traffic forecasting is a challenging problem due to complex road networks and sudden speed changes caused by various events on roads. A number of models have been proposed to solve this challenging problem with a focus on learning spatio-temporal dependencies of roads. In this work, we propose a new perspective of converting the forecasting problem into a pattern matching task, assuming that large data can be represented by a set of patterns. To evaluate the validness of the new perspective, we design a novel traffic forecasting model, called Pattern-Matching Memory Networks (PM-MemNet), which learns to match input data to the representative patterns with a key-value memory structure. We first extract and cluster representative traffic patterns, which serve as keys in the memory. Then via matching the extracted keys and inputs, PM-MemNet acquires necessary information of existing traffic patterns from the memory and uses it for forecasting. To model spatio-temporal correlation of traffic, we proposed novel memory architecture GCMem, which integrates attention and graph convolution for memory enhancement. The experiment results indicate that PM-MemNet is more accurate than state-of-the-art models, such as Graph WaveNet with higher responsiveness. We also present a qualitative analysis result, describing how PM-MemNet works and achieves its higher accuracy when road speed rapidly changes.
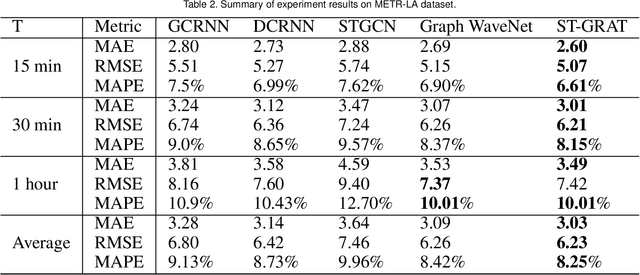
An Empirical Experiment on Deep Learning Models for Predicting Traffic Data
May 12, 2021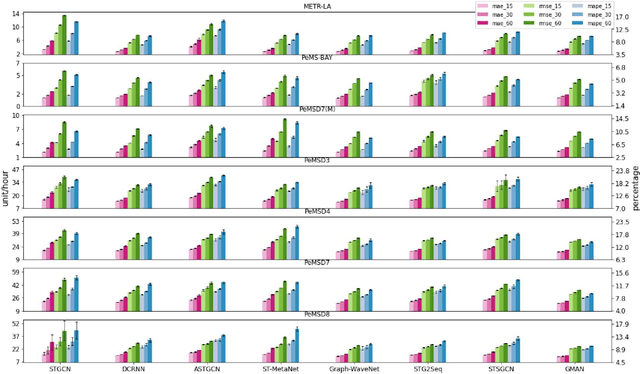

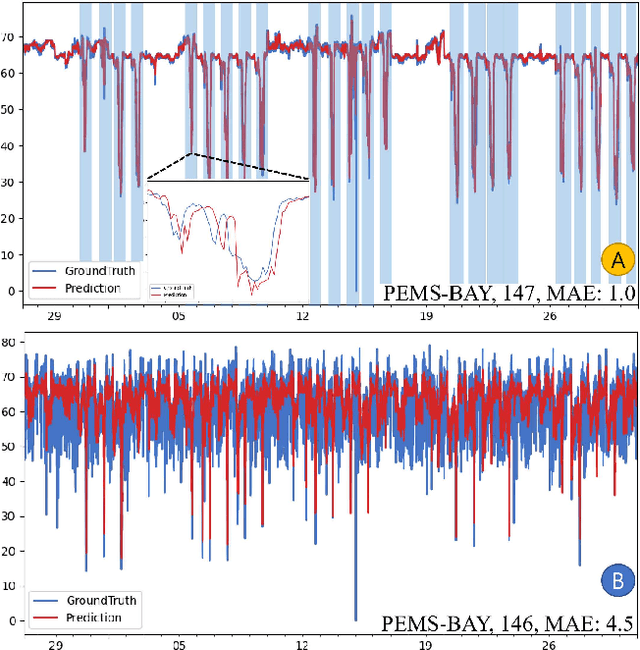
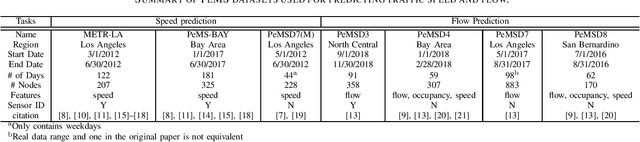
To tackle ever-increasing city traffic congestion problems, researchers have proposed deep learning models to aid decision-makers in the traffic control domain. Although the proposed models have been remarkably improved in recent years, there are still questions that need to be answered before deploying models. For example, it is difficult to figure out which models provide state-of-the-art performance, as recently proposed models have often been evaluated with different datasets and experiment environments. It is also difficult to determine which models would work when traffic conditions change abruptly (e.g., rush hour). In this work, we conduct two experiments to answer the two questions. In the first experiment, we conduct an experiment with the state-of-the-art models and the identical public datasets to compare model performance under a consistent experiment environment. We then extract a set of temporal regions in the datasets, whose speeds change abruptly and use these regions to explore model performance with difficult intervals. The experiment results indicate that Graph-WaveNet and GMAN show better performance in general. We also find that prediction models tend to have varying performances with data and intervals, which calls for in-depth analysis of models on difficult intervals for real-world deployment.