 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbability-Conserving Flow Guidance
May 19, 2026Diffusion and flow-based generative models dominate visual synthesis, with guidance aligning samples to user input and improving perceptual quality. However, Classifier-Free Guidance (CFG) and extrapolation-based methods are heuristic linear combinations of velocities/scores that ignore the generative manifold geometry, breaking probability conservation and driving samples off the learned manifold under strong guidance. We analyse guidance through the continuity equation and show its effect decomposes into a divergence term and a score-parallel term defined invariantly across parameterisations. We prove the divergence term blows up structurally as sampling approaches the data manifold, motivating a time-dependent schedule alongside score-parallel attenuation. The resulting plug-and-play rule, Adaptive Manifold Guidance (AdaMaG), bounds both terms at no additional inference cost. Finally, we show that most empirical heuristics for reducing saturation or improving generation quality correspond directly to the two terms in our decomposition. Across image generation benchmarks, AdaMaG improves realism, reduces hallucinations, and induces controlled desaturation in high-guidance regimes.
Learning to See What You Need: Gaze Attention for Multimodal Large Language Models
May 13, 2026When humans describe a visual scene, they do not process the entire image uniformly; instead, they selectively fixate on regions relevant to their intended description. In contrast, current multimodal large language models (MLLMs) attend to all visual tokens at each generation step, leading to diluted focus and unnecessary computational overhead. In this work, we introduce Gaze Attention, a novel mechanism that enables MLLMs to selectively attend to task-relevant visual regions during generation. Specifically, we spatially group visual embeddings-stored as key-value caches-into compact gaze regions, each represented by a lightweight descriptor. At each decoding step, the model dynamically selects the most relevant regions and restricts attention to them, reducing redundant computation while enhancing focus. To mitigate the loss of global context caused by localized attention, we further propose learnable context tokens appended to each image or frame, allowing the model to maintain holistic visual awareness. Extensive experiments on image and video understanding benchmarks demonstrate that Gaze Attention matches or surpasses dense-attention baselines, while using up to 90% fewer visual KV entries in the attention computation.
FlashSAC: Fast and Stable Off-Policy Reinforcement Learning for High-Dimensional Robot Control
Apr 06, 2026Reinforcement learning (RL) is a core approach for robot control when expert demonstrations are unavailable. On-policy methods such as Proximal Policy Optimization (PPO) are widely used for their stability, but their reliance on narrowly distributed on-policy data limits accurate policy evaluation in high-dimensional state and action spaces. Off-policy methods can overcome this limitation by learning from a broader state-action distribution, yet suffer from slow convergence and instability, as fitting a value function over diverse data requires many gradient updates, causing critic errors to accumulate through bootstrapping. We present FlashSAC, a fast and stable off-policy RL algorithm built on Soft Actor-Critic. Motivated by scaling laws observed in supervised learning, FlashSAC sharply reduces gradient updates while compensating with larger models and higher data throughput. To maintain stability at increased scale, FlashSAC explicitly bounds weight, feature, and gradient norms, curbing critic error accumulation. Across over 60 tasks in 10 simulators, FlashSAC consistently outperforms PPO and strong off-policy baselines in both final performance and training efficiency, with the largest gains on high-dimensional tasks such as dexterous manipulation. In sim-to-real humanoid locomotion, FlashSAC reduces training time from hours to minutes, demonstrating the promise of off-policy RL for sim-to-real transfer.
OPRO: Orthogonal Panel-Relative Operators for Panel-Aware In-Context Image Generation
Mar 29, 2026We introduce a parameter-efficient adaptation method for panel-aware in-context image generation with pre-trained diffusion transformers. The key idea is to compose learnable, panel-specific orthogonal operators onto the backbone's frozen positional encodings. This design provides two desirable properties: (1) isometry, which preserves the geometry of internal features, and (2) same-panel invariance, which maintains the model's pre-trained intra-panel synthesis behavior. Through controlled experiments, we demonstrate that the effectiveness of our adaptation method is not tied to a specific positional encoding design but generalizes across diverse positional encoding regimes. By enabling effective panel-relative conditioning, the proposed method consistently improves in-context image-based instructional editing pipelines, including state-of-the-art approaches.
SNAP: Speaker Nulling for Artifact Projection in Speech Deepfake Detection
Mar 21, 2026Recent advancements in text-to-speech technologies enable generating high-fidelity synthetic speech nearly indistinguishable from real human voices. While recent studies show the efficacy of self-supervised learning-based speech encoders for deepfake detection, these models struggle to generalize across unseen speakers. Our quantitative analysis suggests these encoder representations are substantially influenced by speaker information, causing detectors to exploit speaker-specific correlations rather than artifact-related cues. We call this phenomenon speaker entanglement. To mitigate this reliance, we introduce SNAP, a speaker-nulling framework. We estimate a speaker subspace and apply orthogonal projection to suppress speaker-dependent components, isolating synthesis artifacts within the residual features. By reducing speaker entanglement, SNAP encourages detectors to focus on artifact-related patterns, leading to state-of-the-art performance.
Memory-Efficient Fine-Tuning Diffusion Transformers via Dynamic Patch Sampling and Block Skipping
Mar 21, 2026Diffusion Transformers (DiTs) have significantly enhanced text-to-image (T2I) generation quality, enabling high-quality personalized content creation. However, fine-tuning these models requires substantial computational complexity and memory, limiting practical deployment under resource constraints. To tackle these challenges, we propose a memory-efficient fine-tuning framework called DiT-BlockSkip, integrating timestep-aware dynamic patch sampling and block skipping by precomputing residual features. Our dynamic patch sampling strategy adjusts patch sizes based on the diffusion timestep, then resizes the cropped patches to a fixed lower resolution. This approach reduces forward & backward memory usage while allowing the model to capture global structures at higher timesteps and fine-grained details at lower timesteps. The block skipping mechanism selectively fine-tunes essential transformer blocks and precomputes residual features for the skipped blocks, significantly reducing training memory. To identify vital blocks for personalization, we introduce a block selection strategy based on cross-attention masking. Evaluations demonstrate that our approach achieves competitive personalization performance qualitatively and quantitatively, while reducing memory usage substantially, moving toward on-device feasibility (e.g., smartphones, IoT devices) for large-scale diffusion transformers.
LiveWeb-IE: A Benchmark For Online Web Information Extraction
Mar 14, 2026Web information extraction (WIE) is the task of automatically extracting data from web pages, offering high utility for various applications. The evaluation of WIE systems has traditionally relied on benchmarks built from HTML snapshots captured at a single point in time. However, this offline evaluation paradigm fails to account for the temporally evolving nature of the web; consequently, performance on these static benchmarks often fails to generalize to dynamic real-world scenarios. To bridge this gap, we introduce \dataset, a new benchmark designed for evaluating WIE systems directly against live websites. Based on trusted and permission-granted websites, we curate natural language queries that require information extraction of various data categories, such as text, images, and hyperlinks. We further design these queries to represent four levels of complexity, based on the number and cardinality of attributes to be extracted, enabling a granular assessment of WIE systems. In addition, we propose Visual Grounding Scraper (VGS), a novel multi-stage agentic framework that mimics human cognitive processes by visually narrowing down web page content to extract desired information. Extensive experiments across diverse backbone models demonstrate the effectiveness and robustness of VGS. We believe that this study lays the foundation for developing practical and robust WIE systems.
ExpGuard: LLM Content Moderation in Specialized Domains
Mar 03, 2026With the growing deployment of large language models (LLMs) in real-world applications, establishing robust safety guardrails to moderate their inputs and outputs has become essential to ensure adherence to safety policies. Current guardrail models predominantly address general human-LLM interactions, rendering LLMs vulnerable to harmful and adversarial content within domain-specific contexts, particularly those rich in technical jargon and specialized concepts. To address this limitation, we introduce ExpGuard, a robust and specialized guardrail model designed to protect against harmful prompts and responses across financial, medical, and legal domains. In addition, we present ExpGuardMix, a meticulously curated dataset comprising 58,928 labeled prompts paired with corresponding refusal and compliant responses, from these specific sectors. This dataset is divided into two subsets: ExpGuardTrain, for model training, and ExpGuardTest, a high-quality test set annotated by domain experts to evaluate model robustness against technical and domain-specific content. Comprehensive evaluations conducted on ExpGuardTest and eight established public benchmarks reveal that ExpGuard delivers competitive performance across the board while demonstrating exceptional resilience to domain-specific adversarial attacks, surpassing state-of-the-art models such as WildGuard by up to 8.9% in prompt classification and 15.3% in response classification. To encourage further research and development, we open-source our code, data, and model, enabling adaptation to additional domains and supporting the creation of increasingly robust guardrail models.
BankMathBench: A Benchmark for Numerical Reasoning in Banking Scenarios
Feb 19, 2026Large language models (LLMs)-based chatbots are increasingly being adopted in the financial domain, particularly in digital banking, to handle customer inquiries about products such as deposits, savings, and loans. However, these models still exhibit low accuracy in core banking computations-including total payout estimation, comparison of products with varying interest rates, and interest calculation under early repayment conditions. Such tasks require multi-step numerical reasoning and contextual understanding of banking products, yet existing LLMs often make systematic errors-misinterpreting product types, applying conditions incorrectly, or failing basic calculations involving exponents and geometric progressions. However, such errors have rarely been captured by existing benchmarks. Mathematical datasets focus on fundamental math problems, whereas financial benchmarks primarily target financial documents, leaving everyday banking scenarios underexplored. To address this limitation, we propose BankMathBench, a domain-specific dataset that reflects realistic banking tasks. BankMathBench is organized in three levels of difficulty-basic, intermediate, and advanced-corresponding to single-product reasoning, multi-product comparison, and multi-condition scenarios, respectively. When trained on BankMathBench, open-source LLMs exhibited notable improvements in both formula generation and numerical reasoning accuracy, demonstrating the dataset's effectiveness in enhancing domain-specific reasoning. With tool-augmented fine-tuning, the models achieved average accuracy increases of 57.6%p (basic), 75.1%p (intermediate), and 62.9%p (advanced), representing significant gains over zero-shot baselines. These findings highlight BankMathBench as a reliable benchmark for evaluating and advancing LLMs' numerical reasoning in real-world banking scenarios.
TexAvatars : Hybrid Texel-3D Representations for Stable Rigging of Photorealistic Gaussian Head Avatars
Dec 24, 2025
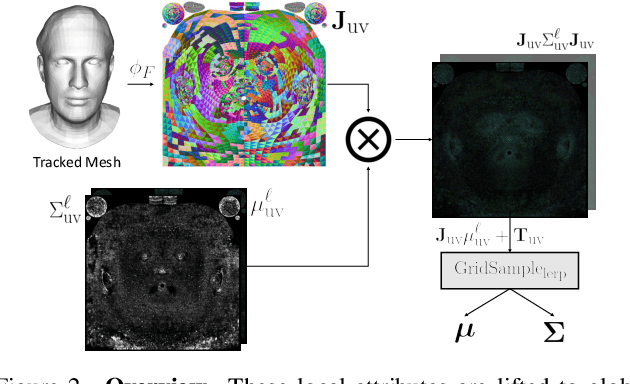


Constructing drivable and photorealistic 3D head avatars has become a central task in AR/XR, enabling immersive and expressive user experiences. With the emergence of high-fidelity and efficient representations such as 3D Gaussians, recent works have pushed toward ultra-detailed head avatars. Existing approaches typically fall into two categories: rule-based analytic rigging or neural network-based deformation fields. While effective in constrained settings, both approaches often fail to generalize to unseen expressions and poses, particularly in extreme reenactment scenarios. Other methods constrain Gaussians to the global texel space of 3DMMs to reduce rendering complexity. However, these texel-based avatars tend to underutilize the underlying mesh structure. They apply minimal analytic deformation and rely heavily on neural regressors and heuristic regularization in UV space, which weakens geometric consistency and limits extrapolation to complex, out-of-distribution deformations. To address these limitations, we introduce TexAvatars, a hybrid avatar representation that combines the explicit geometric grounding of analytic rigging with the spatial continuity of texel space. Our approach predicts local geometric attributes in UV space via CNNs, but drives 3D deformation through mesh-aware Jacobians, enabling smooth and semantically meaningful transitions across triangle boundaries. This hybrid design separates semantic modeling from geometric control, resulting in improved generalization, interpretability, and stability. Furthermore, TexAvatars captures fine-grained expression effects, including muscle-induced wrinkles, glabellar lines, and realistic mouth cavity geometry, with high fidelity. Our method achieves state-of-the-art performance under extreme pose and expression variations, demonstrating strong generalization in challenging head reenactment settings.