 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2S-Bench & Structure-of-Thought: Benchmarking and Prompting Comprehensive Text-to-Structure Reasoning
Mar 04, 2026Think about how human handles complex reading tasks: marking key points, inferring their relationships, and structuring information to guide understanding and responses. Likewise, can a large language model benefit from text structure to enhance text-processing performance? To explore it, in this work, we first introduce Structure of Thought (SoT), a prompting technique that explicitly guides models to construct intermediate text structures, consistently boosting performance across eight tasks and three model families. Building upon this insight, we present T2S-Bench, the first benchmark designed to evaluate and improve text-to-structure capabilities of models. T2S-Bench includes 1.8K samples across 6 scientific domains and 32 structural types, rigorously constructed to ensure accuracy, fairness, and quality. Evaluation on 45 mainstream models reveals substantial improvement potential: the average accuracy on the multi-hop reasoning task is only 52.1%, and even the most advanced model achieves 58.1% node accuracy in end-to-end extraction. Furthermore, on Qwen2.5-7B-Instruct, SoT alone yields an average +5.7% improvement across eight diverse text-processing tasks, and fine-tuning on T2S-Bench further increases this gain to +8.6%. These results highlight the value of explicit text structuring and the complementary contributions of SoT and T2S-Bench. Dataset and eval code have been released at https://t2s-bench.github.io/T2S-Bench-Page/.
MoBiQuant: Mixture-of-Bits Quantization for Token-Adaptive Elastic LLMs
Feb 21, 2026Changing runtime complexity on cloud and edge devices necessitates elastic large language model (LLM) deployment, where an LLM can be inferred with various quantization precisions based on available computational resources. However, it has been observed that the calibration parameters for quantization are typically linked to specific precisions, which presents challenges during elastic-precision calibration and precision switching at runtime. In this work, we attribute the source of varying calibration parameters to the varying token-level sensitivity caused by a precision-dependent outlier migration phenomenon.Motivated by this observation, we propose \texttt{MoBiQuant}, a novel Mixture-of-Bits quantization framework that adjusts weight precision for elastic LLM inference based on token sensitivity. Specifically, we propose the many-in-one recursive residual quantization that can iteratively reconstruct higher-precision weights and the token-aware router to dynamically select the number of residual bit slices. MoBiQuant enables smooth precision switching while improving generalization for the distribution of token outliers. Experimental results demonstrate that MoBiQuant exhibits strong elasticity, enabling it to match the performance of bit-specific calibrated PTQ on LLaMA3-8B without repeated calibration.
Efficient Multi-bit Quantization Network Training via Weight Bias Correction and Bit-wise Coreset Sampling
Oct 23, 2025Multi-bit quantization networks enable flexible deployment of deep neural networks by supporting multiple precision levels within a single model. However, existing approaches suffer from significant training overhead as full-dataset updates are repeated for each supported bit-width, resulting in a cost that scales linearly with the number of precisions. Additionally, extra fine-tuning stages are often required to support additional or intermediate precision options, further compounding the overall training burden. To address this issue, we propose two techniques that greatly reduce the training overhead without compromising model utility: (i) Weight bias correction enables shared batch normalization and eliminates the need for fine-tuning by neutralizing quantization-induced bias across bit-widths and aligning activation distributions; and (ii) Bit-wise coreset sampling strategy allows each child model to train on a compact, informative subset selected via gradient-based importance scores by exploiting the implicit knowledge transfer phenomenon. Experiments on CIFAR-10/100, TinyImageNet, and ImageNet-1K with both ResNet and ViT architectures demonstrate that our method achieves competitive or superior accuracy while reducing training time up to 7.88x. Our code is released at https://github.com/a2jinhee/EMQNet_jk.
MSQ: Memory-Efficient Bit Sparsification Quantization
Jul 30, 2025As deep neural networks (DNNs) see increased deployment on mobile and edge devices, optimizing model efficiency has become crucial. Mixed-precision quantization is widely favored, as it offers a superior balance between efficiency and accuracy compared to uniform quantization. However, finding the optimal precision for each layer is challenging. Recent studies utilizing bit-level sparsity have shown promise, yet they often introduce substantial training complexity and high GPU memory requirements. In this paper, we propose Memory-Efficient Bit Sparsification Quantization (MSQ), a novel approach that addresses these limitations. MSQ applies a round-clamp quantizer to enable differentiable computation of the least significant bits (LSBs) from model weights. It further employs regularization to induce sparsity in these LSBs, enabling effective precision reduction without explicit bit-level parameter splitting. Additionally, MSQ incorporates Hessian information, allowing the simultaneous pruning of multiple LSBs to further enhance training efficiency. Experimental results show that MSQ achieves up to 8.00x reduction in trainable parameters and up to 86% reduction in training time compared to previous bit-level quantization, while maintaining competitive accuracy and compression rates. This makes it a practical solution for training efficient DNNs on resource-constrained devices.
Attend-and-Refine: Interactive keypoint estimation and quantitative cervical vertebrae analysis for bone age assessment
Jul 10, 2025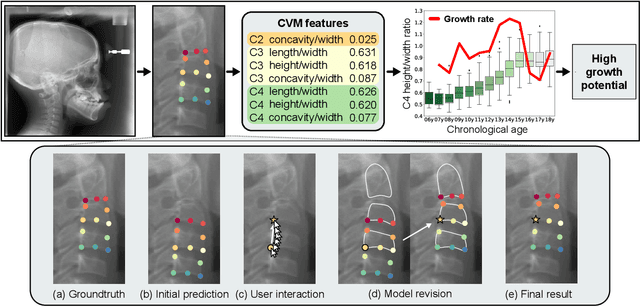
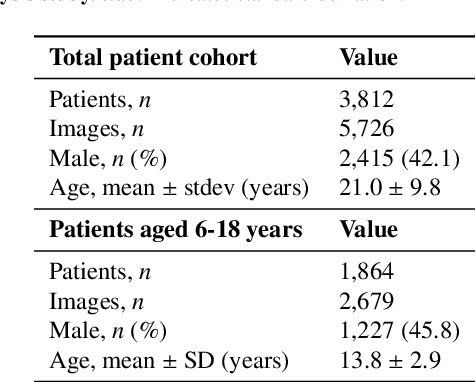
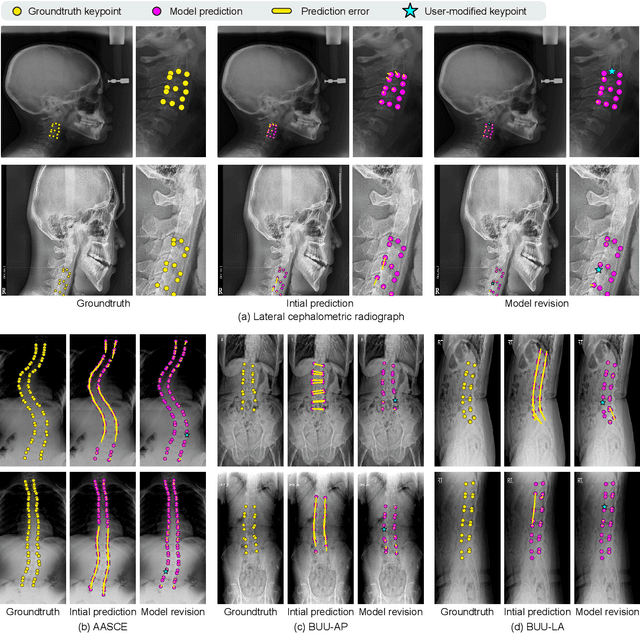
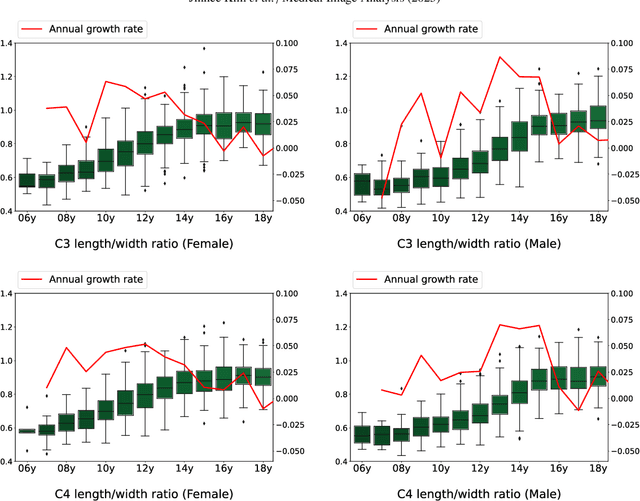
In pediatric orthodontics, accurate estimation of growth potential is essential for developing effective treatment strategies. Our research aims to predict this potential by identifying the growth peak and analyzing cervical vertebra morphology solely through lateral cephalometric radiographs. We accomplish this by comprehensively analyzing cervical vertebral maturation (CVM) features from these radiographs. This methodology provides clinicians with a reliable and efficient tool to determine the optimal timings for orthodontic interventions, ultimately enhancing patient outcomes. A crucial aspect of this approach is the meticulous annotation of keypoints on the cervical vertebrae, a task often challenged by its labor-intensive nature. To mitigate this, we introduce Attend-and-Refine Network (ARNet), a user-interactive, deep learning-based model designed to streamline the annotation process. ARNet features Interaction-guided recalibration network, which adaptively recalibrates image features in response to user feedback, coupled with a morphology-aware loss function that preserves the structural consistency of keypoints. This novel approach substantially reduces manual effort in keypoint identification, thereby enhancing the efficiency and accuracy of the process. Extensively validated across various datasets, ARNet demonstrates remarkable performance and exhibits wide-ranging applicability in medical imaging. In conclusion, our research offers an effective AI-assisted diagnostic tool for assessing growth potential in pediatric orthodontics, marking a significant advancement in the field.
Good Noise Makes Good Edits: A Training-Free Diffusion-Based Video Editing with Image and Text Prompts
Jun 14, 2025



We propose ImEdit, the first zero-shot, training-free video editing method conditioned on both images and text. The proposed method introduces $\rho$-start sampling and dilated dual masking to construct well-structured noise maps for coherent and accurate edits. We further present zero image guidance, a controllable negative prompt strategy, for visual fidelity. Both quantitative and qualitative evaluations show that our method outperforms state-of-the-art methods across all metrics.
TruncQuant: Truncation-Ready Quantization for DNNs with Flexible Weight Bit Precision
Jun 13, 2025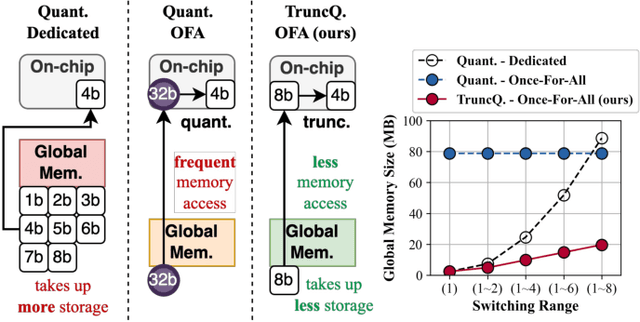
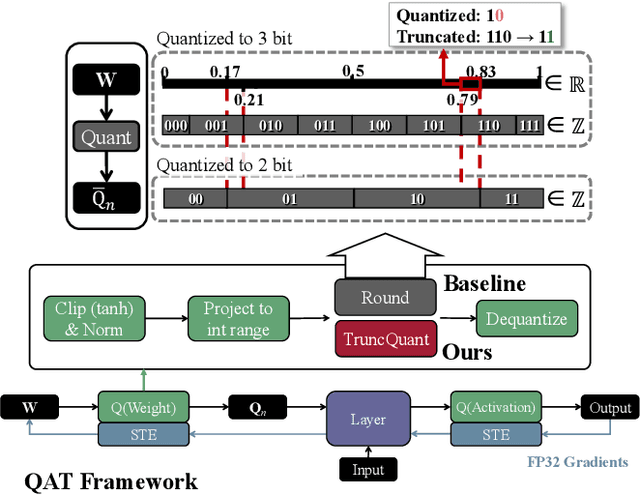
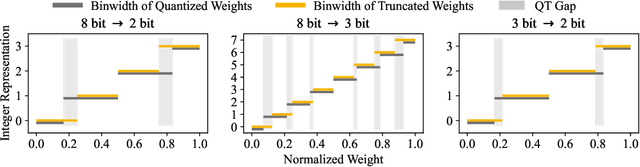
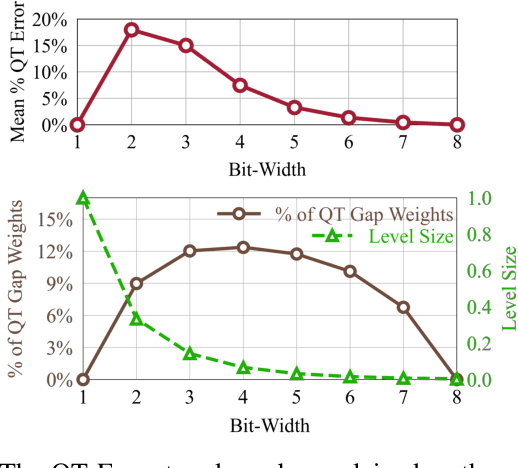
The deployment of deep neural networks on edge devices is a challenging task due to the increasing complexity of state-of-the-art models, requiring efforts to reduce model size and inference latency. Recent studies explore models operating at diverse quantization settings to find the optimal point that balances computational efficiency and accuracy. Truncation, an effective approach for achieving lower bit precision mapping, enables a single model to adapt to various hardware platforms with little to no cost. However, formulating a training scheme for deep neural networks to withstand the associated errors introduced by truncation remains a challenge, as the current quantization-aware training schemes are not designed for the truncation process. We propose TruncQuant, a novel truncation-ready training scheme allowing flexible bit precision through bit-shifting in runtime. We achieve this by aligning TruncQuant with the output of the truncation process, demonstrating strong robustness across bit-width settings, and offering an easily implementable training scheme within existing quantization-aware frameworks. Our code is released at https://github.com/a2jinhee/TruncQuant.
MEMHD: Memory-Efficient Multi-Centroid Hyperdimensional Computing for Fully-Utilized In-Memory Computing Architectures
Feb 11, 2025



The implementation of Hyperdimensional Computing (HDC) on In-Memory Computing (IMC) architectures faces significant challenges due to the mismatch between highdimensional vectors and IMC array sizes, leading to inefficient memory utilization and increased computation cycles. This paper presents MEMHD, a Memory-Efficient Multi-centroid HDC framework designed to address these challenges. MEMHD introduces a clustering-based initialization method and quantization aware iterative learning for multi-centroid associative memory. Through these approaches and its overall architecture, MEMHD achieves a significant reduction in memory requirements while maintaining or improving classification accuracy. Our approach achieves full utilization of IMC arrays and enables one-shot (or few-shot) associative search. Experimental results demonstrate that MEMHD outperforms state-of-the-art binary HDC models, achieving up to 13.69% higher accuracy with the same memory usage, or 13.25x more memory efficiency at the same accuracy level. Moreover, MEMHD reduces computation cycles by up to 80x and array usage by up to 71x compared to baseline IMC mapping methods when mapped to 128x128 IMC arrays, while significantly improving energy and computation cycle efficiency.
Bones Can't Be Triangles: Accurate and Efficient Vertebrae Keypoint Estimation through Collaborative Error Revision
Sep 05, 2024Recent advances in interactive keypoint estimation methods have enhanced accuracy while minimizing user intervention. However, these methods require user input for error correction, which can be costly in vertebrae keypoint estimation where inaccurate keypoints are densely clustered or overlap. We introduce a novel approach, KeyBot, specifically designed to identify and correct significant and typical errors in existing models, akin to user revision. By characterizing typical error types and using simulated errors for training, KeyBot effectively corrects these errors and significantly reduces user workload. Comprehensive quantitative and qualitative evaluations on three public datasets confirm that KeyBot significantly outperforms existing methods, achieving state-of-the-art performance in interactive vertebrae keypoint estimation. The source code and demo video are available at: https://ts-kim.github.io/KeyBot/
Group-wise Prompting for Synthetic Tabular Data Generation using Large Language Models
Apr 15, 2024



Generating realistic synthetic tabular data presents a critical challenge in machine learning. This study introduces a simple yet effective method employing Large Language Models (LLMs) tailored to generate synthetic data, specifically addressing data imbalance problems. We propose a novel group-wise prompting method in CSV-style formatting that leverages the in-context learning capabilities of LLMs to produce data that closely adheres to the specified requirements and characteristics of the target dataset. Moreover, our proposed random word replacement strategy significantly improves the handling of monotonous categorical values, enhancing the accuracy and representativeness of the synthetic data. The effectiveness of our method is extensively validated across eight real-world public datasets, achieving state-of-the-art performance in downstream classification and regression tasks while maintaining inter-feature correlations and improving token efficiency over existing approaches. This advancement significantly contributes to addressing the key challenges of machine learning applications, particularly in the context of tabular data generation and handling class imbalance. The source code for our work is available at: https://github.com/seharanul17/synthetic-tabular-LLM