 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend-and-Refine: Interactive keypoint estimation and quantitative cervical vertebrae analysis for bone age assessment
Jul 10, 2025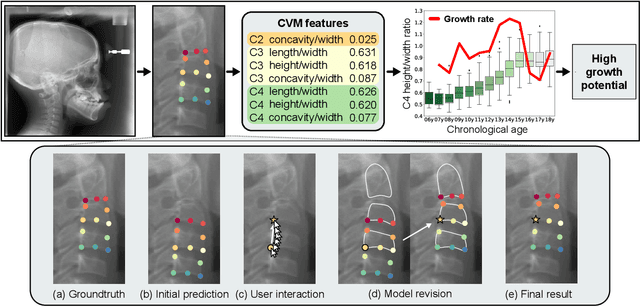
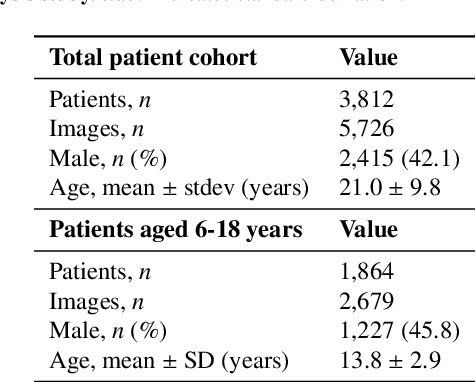
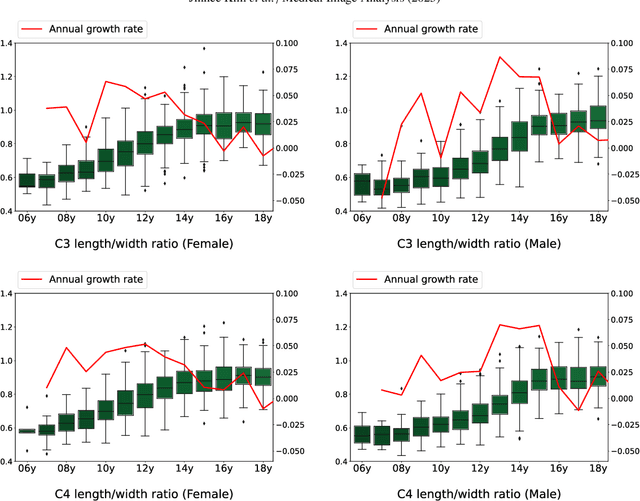
In pediatric orthodontics, accurate estimation of growth potential is essential for developing effective treatment strategies. Our research aims to predict this potential by identifying the growth peak and analyzing cervical vertebra morphology solely through lateral cephalometric radiographs. We accomplish this by comprehensively analyzing cervical vertebral maturation (CVM) features from these radiographs. This methodology provides clinicians with a reliable and efficient tool to determine the optimal timings for orthodontic interventions, ultimately enhancing patient outcomes. A crucial aspect of this approach is the meticulous annotation of keypoints on the cervical vertebrae, a task often challenged by its labor-intensive nature. To mitigate this, we introduce Attend-and-Refine Network (ARNet), a user-interactive, deep learning-based model designed to streamline the annotation process. ARNet features Interaction-guided recalibration network, which adaptively recalibrates image features in response to user feedback, coupled with a morphology-aware loss function that preserves the structural consistency of keypoints. This novel approach substantially reduces manual effort in keypoint identification, thereby enhancing the efficiency and accuracy of the process. Extensively validated across various datasets, ARNet demonstrates remarkable performance and exhibits wide-ranging applicability in medical imaging. In conclusion, our research offers an effective AI-assisted diagnostic tool for assessing growth potential in pediatric orthodontics, marking a significant advancement in the field.
Morphology-Aware Interactive Keypoint Estimation
Sep 15, 2022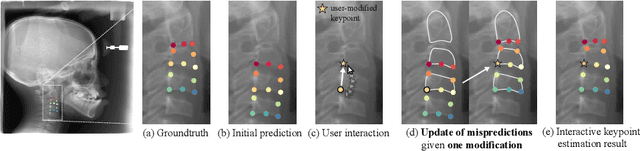
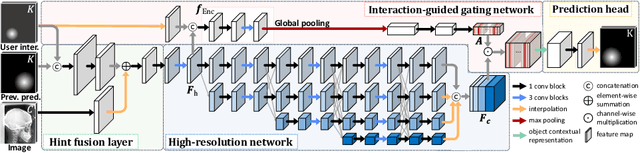
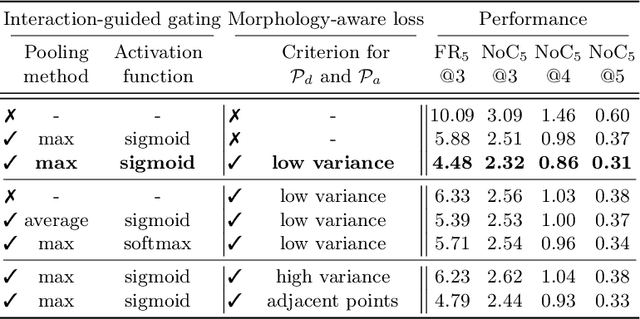

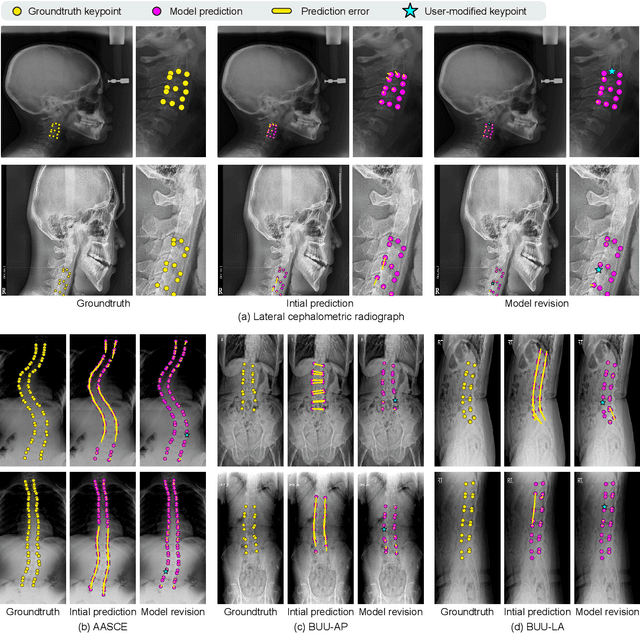
Diagnosis based on medical images, such as X-ray images, often involves manual annotation of anatomical keypoints. However, this process involves significant human efforts and can thus be a bottleneck in the diagnostic process. To fully automate this procedure, deep-learning-based methods have been widely proposed and have achieved high performance in detecting keypoints in medical images. However, these methods still have clinical limitations: accuracy cannot be guaranteed for all cases, and it is necessary for doctors to double-check all predictions of models. In response, we propose a novel deep neural network that, given an X-ray image, automatically detects and refines the anatomical keypoints through a user-interactive system in which doctors can fix mispredicted keypoints with fewer clicks than needed during manual revision. Using our own collected data and the publicly available AASCE dataset, we demonstrate the effectiveness of the proposed method in reducing the annotation costs via extensive quantitative and qualitative results. A demo video of our approach is available on our project webpage.
RZSR: Reference-based Zero-Shot Super-Resolution with Depth Guided Self-Exemplars
Aug 24, 2022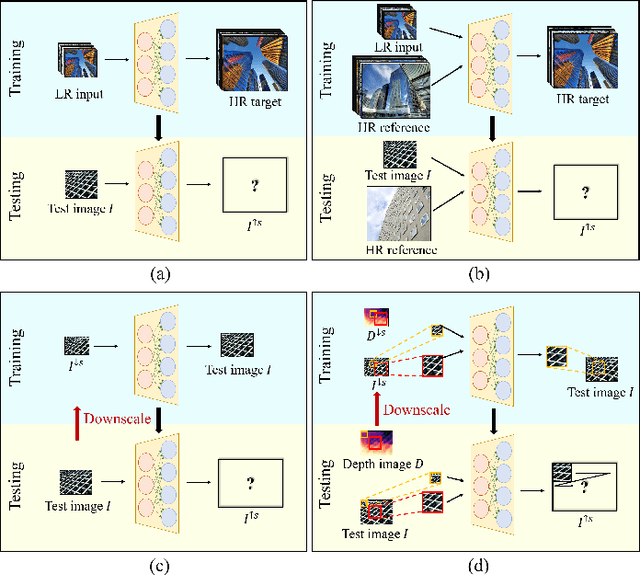
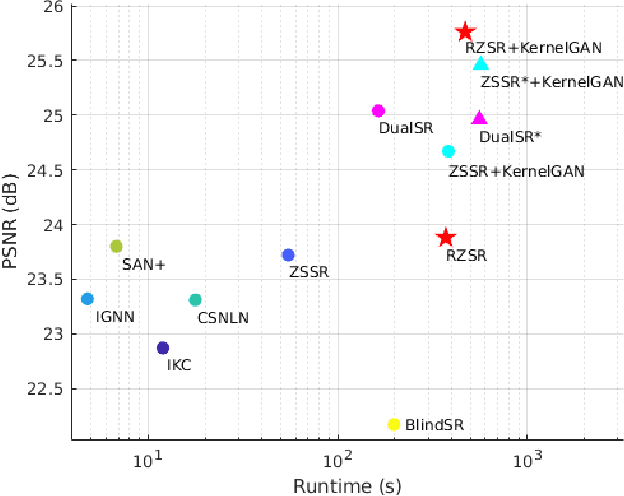
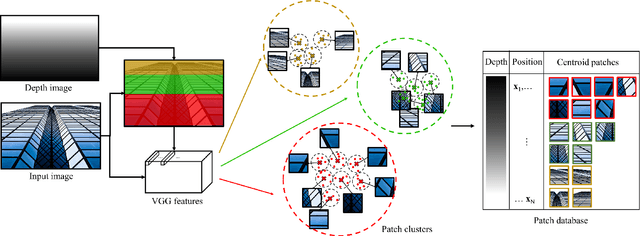
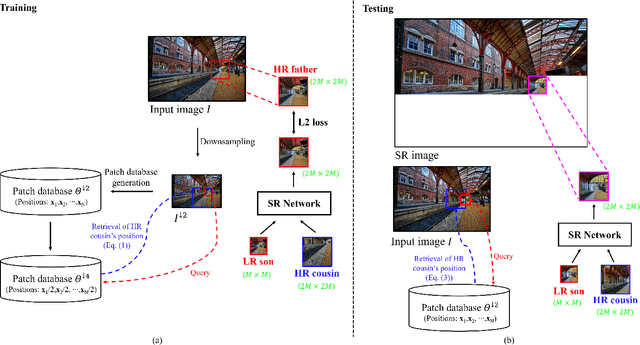
Recent methods for single image super-resolution (SISR) have demonstrated outstanding performance in generating high-resolution (HR) images from low-resolution (LR) images. However, most of these methods show their superiority using synthetically generated LR images, and their generalizability to real-world images is often not satisfactory. In this paper, we pay attention to two well-known strategies developed for robust super-resolution (SR), i.e., reference-based SR (RefSR) and zero-shot SR (ZSSR), and propose an integrated solution, called reference-based zero-shot SR (RZSR). Following the principle of ZSSR, we train an image-specific SR network at test time using training samples extracted only from the input image itself. To advance ZSSR, we obtain reference image patches with rich textures and high-frequency details which are also extracted only from the input image using cross-scale matching. To this end, we construct an internal reference dataset and retrieve reference image patches from the dataset using depth information. Using LR patches and their corresponding HR reference patches, we train a RefSR network that is embodied with a non-local attention module. Experimental results demonstrate the superiority of the proposed RZSR compared to the previous ZSSR methods and robustness to unseen images compared to other fully supervised SISR methods.
GRDN:Grouped Residual Dense Network for Real Image Denoising and GAN-based Real-world Noise Modeling
May 27, 2019
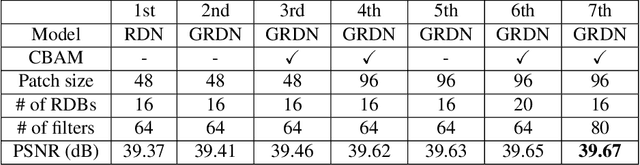
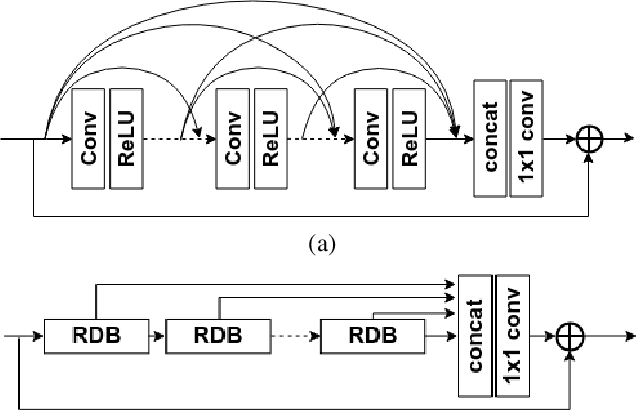
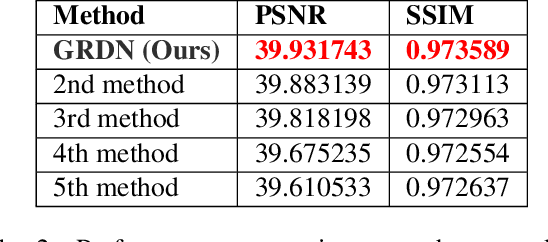
Recent research on image denoising has progressed with the development of deep learning architectures, especially convolutional neural networks. However, real-world image denoising is still very challenging because it is not possible to obtain ideal pairs of ground-truth images and real-world noisy images. Owing to the recent release of benchmark datasets, the interest of the image denoising community is now moving toward the real-world denoising problem. In this paper, we propose a grouped residual dense network (GRDN), which is an extended and generalized architecture of the state-of-the-art residual dense network (RDN). The core part of RDN is defined as grouped residual dense block (GRDB) and used as a building module of GRDN. We experimentally show that the image denoising performance can be significantly improved by cascading GRDBs. In addition to the network architecture design, we also develop a new generative adversarial network-based real-world noise modeling method. We demonstrate the superiority of the proposed methods by achieving the highest score in terms of both the peak signal-to-noise ratio and the structural similarity in the NTIRE2019 Real Image Denoising Challenge - Track 2:sRGB.