 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel-wise Noise Scheduled Diffusion for Inverse Rendering in Indoor Scenes
Mar 13, 2025We propose a diffusion-based inverse rendering framework that decomposes a single RGB image into geometry, material, and lighting. Inverse rendering is inherently ill-posed, making it difficult to predict a single accurate solution. To address this challenge, recent generative model-based methods aim to present a range of possible solutions. However, finding a single accurate solution and generating diverse solutions can be conflicting. In this paper, we propose a channel-wise noise scheduling approach that allows a single diffusion model architecture to achieve two conflicting objectives. The resulting two diffusion models, trained with different channel-wise noise schedules, can predict a single highly accurate solution and present multiple possible solutions. The experimental results demonstrate the superiority of our two models in terms of both diversity and accuracy, which translates to enhanced performance in downstream applications such as object insertion and material editing.
MAIR++: Improving Multi-view Attention Inverse Rendering with Implicit Lighting Representation
Aug 13, 2024
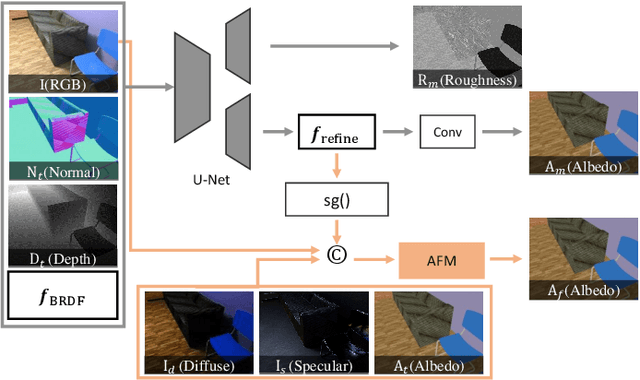


In this paper, we propose a scene-level inverse rendering framework that uses multi-view images to decompose the scene into geometry, SVBRDF, and 3D spatially-varying lighting. While multi-view images have been widely used for object-level inverse rendering, scene-level inverse rendering has primarily been studied using single-view images due to the lack of a dataset containing high dynamic range multi-view images with ground-truth geometry, material, and spatially-varying lighting. To improve the quality of scene-level inverse rendering, a novel framework called Multi-view Attention Inverse Rendering (MAIR) was recently introduced. MAIR performs scene-level multi-view inverse rendering by expanding the OpenRooms dataset, designing efficient pipelines to handle multi-view images, and splitting spatially-varying lighting. Although MAIR showed impressive results, its lighting representation is fixed to spherical Gaussians, which limits its ability to render images realistically. Consequently, MAIR cannot be directly used in applications such as material editing. Moreover, its multi-view aggregation networks have difficulties extracting rich features because they only focus on the mean and variance between multi-view features. In this paper, we propose its extended version, called MAIR++. MAIR++ addresses the aforementioned limitations by introducing an implicit lighting representation that accurately captures the lighting conditions of an image while facilitating realistic rendering. Furthermore, we design a directional attention-based multi-view aggregation network to infer more intricate relationships between views. Experimental results show that MAIR++ not only achieves better performance than MAIR and single-view-based methods, but also displays robust performance on unseen real-world scenes.
Lesion-Aware Cross-Phase Attention Network for Renal Tumor Subtype Classification on Multi-Phase CT Scans
Jun 24, 2024Multi-phase computed tomography (CT) has been widely used for the preoperative diagnosis of kidney cancer due to its non-invasive nature and ability to characterize renal lesions. However, since enhancement patterns of renal lesions across CT phases are different even for the same lesion type, the visual assessment by radiologists suffers from inter-observer variability in clinical practice. Although deep learning-based approaches have been recently explored for differential diagnosis of kidney cancer, they do not explicitly model the relationships between CT phases in the network design, limiting the diagnostic performance. In this paper, we propose a novel lesion-aware cross-phase attention network (LACPANet) that can effectively capture temporal dependencies of renal lesions across CT phases to accurately classify the lesions into five major pathological subtypes from time-series multi-phase CT images. We introduce a 3D inter-phase lesion-aware attention mechanism to learn effective 3D lesion features that are used to estimate attention weights describing the inter-phase relations of the enhancement patterns. We also present a multi-scale attention scheme to capture and aggregate temporal patterns of lesion features at different spatial scales for further improvement. Extensive experiments on multi-phase CT scans of kidney cancer patients from the collected dataset demonstrate that our LACPANet outperforms state-of-the-art approaches in diagnostic accuracy.
* This article has been accepted for publication in Computers in Biology and Medicine
RefQSR: Reference-based Quantization for Image Super-Resolution Networks
Apr 02, 2024Single image super-resolution (SISR) aims to reconstruct a high-resolution image from its low-resolution observation. Recent deep learning-based SISR models show high performance at the expense of increased computational costs, limiting their use in resource-constrained environments. As a promising solution for computationally efficient network design, network quantization has been extensively studied. However, existing quantization methods developed for SISR have yet to effectively exploit image self-similarity, which is a new direction for exploration in this study. We introduce a novel method called reference-based quantization for image super-resolution (RefQSR) that applies high-bit quantization to several representative patches and uses them as references for low-bit quantization of the rest of the patches in an image. To this end, we design dedicated patch clustering and reference-based quantization modules and integrate them into existing SISR network quantization methods. The experimental results demonstrate the effectiveness of RefQSR on various SISR networks and quantization methods.
Spectrum Translation for Refinement of Image Generation (STIG) Based on Contrastive Learning and Spectral Filter Profile
Mar 08, 2024



Currently, image generation and synthesis have remarkably progressed with generative models. Despite photo-realistic results, intrinsic discrepancies are still observed in the frequency domain. The spectral discrepancy appeared not only in generative adversarial networks but in diffusion models. In this study, we propose a framework to effectively mitigate the disparity in frequency domain of the generated images to improve generative performance of both GAN and diffusion models. This is realized by spectrum translation for the refinement of image generation (STIG) based on contrastive learning. We adopt theoretical logic of frequency components in various generative networks. The key idea, here, is to refine the spectrum of the generated image via the concept of image-to-image translation and contrastive learning in terms of digital signal processing. We evaluate our framework across eight fake image datasets and various cutting-edge models to demonstrate the effectiveness of STIG. Our framework outperforms other cutting-edges showing significant decreases in FID and log frequency distance of spectrum. We further emphasize that STIG improves image quality by decreasing the spectral anomaly. Additionally, validation results present that the frequency-based deepfake detector confuses more in the case where fake spectrums are manipulated by STIG.
A Unified Multi-Phase CT Synthesis and Classification Framework for Kidney Cancer Diagnosis with Incomplete Data
Dec 09, 2023Multi-phase CT is widely adopted for the diagnosis of kidney cancer due to the complementary information among phases. However, the complete set of multi-phase CT is often not available in practical clinical applications. In recent years, there have been some studies to generate the missing modality image from the available data. Nevertheless, the generated images are not guaranteed to be effective for the diagnosis task. In this paper, we propose a unified framework for kidney cancer diagnosis with incomplete multi-phase CT, which simultaneously recovers missing CT images and classifies cancer subtypes using the completed set of images. The advantage of our framework is that it encourages a synthesis model to explicitly learn to generate missing CT phases that are helpful for classifying cancer subtypes. We further incorporate lesion segmentation network into our framework to exploit lesion-level features for effective cancer classification in the whole CT volumes. The proposed framework is based on fully 3D convolutional neural networks to jointly optimize both synthesis and classification of 3D CT volumes. Extensive experiments on both in-house and external datasets demonstrate the effectiveness of our framework for the diagnosis with incomplete data compared with state-of-the-art baselines. In particular, cancer subtype classification using the completed CT data by our method achieves higher performance than the classification using the given incomplete data.
* This article has been accepted for publication in IEEE Journal of Biomedical and Health Informatics
Exploring 3D U-Net Training Configurations and Post-Processing Strategies for the MICCAI 2023 Kidney and Tumor Segmentation Challenge
Dec 09, 2023


In 2023, it is estimated that 81,800 kidney cancer cases will be newly diagnosed, and 14,890 people will die from this cancer in the United States. Preoperative dynamic contrast-enhanced abdominal computed tomography (CT) is often used for detecting lesions. However, there exists inter-observer variability due to subtle differences in the imaging features of kidney and kidney tumors. In this paper, we explore various 3D U-Net training configurations and effective post-processing strategies for accurate segmentation of kidneys, cysts, and kidney tumors in CT images. We validated our model on the dataset of the 2023 Kidney and Kidney Tumor Segmentation (KiTS23) challenge. Our method took second place in the final ranking of the KiTS23 challenge on unseen test data with an average Dice score of 0.820 and an average Surface Dice of 0.712.
Hierarchical Spatiotemporal Transformers for Video Object Segmentation
Jul 17, 2023



This paper presents a novel framework called HST for semi-supervised video object segmentation (VOS). HST extracts image and video features using the latest Swin Transformer and Video Swin Transformer to inherit their inductive bias for the spatiotemporal locality, which is essential for temporally coherent VOS. To take full advantage of the image and video features, HST casts image and video features as a query and memory, respectively. By applying efficient memory read operations at multiple scales, HST produces hierarchical features for the precise reconstruction of object masks. HST shows effectiveness and robustness in handling challenging scenarios with occluded and fast-moving objects under cluttered backgrounds. In particular, HST-B outperforms the state-of-the-art competitors on multiple popular benchmarks, i.e., YouTube-VOS (85.0%), DAVIS 2017 (85.9%), and DAVIS 2016 (94.0%).
Multi-frame-based Cross-domain Image Denoising for Low-dose Computed Tomography
Apr 27, 2023Computed tomography (CT) has been used worldwide for decades as one of the most important non-invasive tests in assisting diagnosis. However, the ionizing nature of X-ray exposure raises concerns about potential health risks such as cancer. The desire for lower radiation dose has driven researchers to improve the reconstruction quality, especially by removing noise and artifacts. Although previous studies on low-dose computed tomography (LDCT) denoising have demonstrated the potential of learning-based methods, most of them were developed on the simulated data collected using Radon transform. However, the real-world scenario significantly differs from the simulation domain, and the joint optimization of denoising with the modern CT image reconstruction pipeline is still missing. In this paper, for the commercially available third-generation multi-slice spiral CT scanners, we propose a two-stage method that better exploits the complete reconstruction pipeline for LDCT denoising across different domains. Our method makes good use of the high redundancy of both the multi-slice projections and the volumetric reconstructions while avoiding the collapse of information in conventional cascaded frameworks. The dedicated design also provides a clearer interpretation of the workflow. Through extensive evaluations, we demonstrate its superior performance against state-of-the-art methods.
MAIR: Multi-view Attention Inverse Rendering with 3D Spatially-Varying Lighting Estimation
Mar 27, 2023



We propose a scene-level inverse rendering framework that uses multi-view images to decompose the scene into geometry, a SVBRDF, and 3D spatially-varying lighting. Because multi-view images provide a variety of information about the scene, multi-view images in object-level inverse rendering have been taken for granted. However, owing to the absence of multi-view HDR synthetic dataset, scene-level inverse rendering has mainly been studied using single-view image. We were able to successfully perform scene-level inverse rendering using multi-view images by expanding OpenRooms dataset and designing efficient pipelines to handle multi-view images, and splitting spatially-varying lighting. Our experiments show that the proposed method not only achieves better performance than single-view-based methods, but also achieves robust performance on unseen real-world scene. Also, our sophisticated 3D spatially-varying lighting volume allows for photorealistic object insertion in any 3D location.