 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Gaussian Scene Reconstruction from Unsynchronized Videos
Nov 14, 2025Multi-view video reconstruction plays a vital role in computer vision, enabling applications in film production, virtual reality, and motion analysis. While recent advances such as 4D Gaussian Splatting (4DGS) have demonstrated impressive capabilities in dynamic scene reconstruction, they typically rely on the assumption that input video streams are temporally synchronized. However, in real-world scenarios, this assumption often fails due to factors like camera trigger delays or independent recording setups, leading to temporal misalignment across views and reduced reconstruction quality. To address this challenge, a novel temporal alignment strategy is proposed for high-quality 4DGS reconstruction from unsynchronized multi-view videos. Our method features a coarse-to-fine alignment module that estimates and compensates for each camera's time shift. The method first determines a coarse, frame-level offset and then refines it to achieve sub-frame accuracy. This strategy can be integrated as a readily integrable module into existing 4DGS frameworks, enhancing their robustness when handling asynchronous data. Experiments show that our approach effectively processes temporally misaligned videos and significantly enhances baseline methods.
Exploring 3D U-Net Training Configurations and Post-Processing Strategies for the MICCAI 2023 Kidney and Tumor Segmentation Challenge
Dec 09, 2023


In 2023, it is estimated that 81,800 kidney cancer cases will be newly diagnosed, and 14,890 people will die from this cancer in the United States. Preoperative dynamic contrast-enhanced abdominal computed tomography (CT) is often used for detecting lesions. However, there exists inter-observer variability due to subtle differences in the imaging features of kidney and kidney tumors. In this paper, we explore various 3D U-Net training configurations and effective post-processing strategies for accurate segmentation of kidneys, cysts, and kidney tumors in CT images. We validated our model on the dataset of the 2023 Kidney and Kidney Tumor Segmentation (KiTS23) challenge. Our method took second place in the final ranking of the KiTS23 challenge on unseen test data with an average Dice score of 0.820 and an average Surface Dice of 0.712.
Multi-frame-based Cross-domain Image Denoising for Low-dose Computed Tomography
Apr 27, 2023Computed tomography (CT) has been used worldwide for decades as one of the most important non-invasive tests in assisting diagnosis. However, the ionizing nature of X-ray exposure raises concerns about potential health risks such as cancer. The desire for lower radiation dose has driven researchers to improve the reconstruction quality, especially by removing noise and artifacts. Although previous studies on low-dose computed tomography (LDCT) denoising have demonstrated the potential of learning-based methods, most of them were developed on the simulated data collected using Radon transform. However, the real-world scenario significantly differs from the simulation domain, and the joint optimization of denoising with the modern CT image reconstruction pipeline is still missing. In this paper, for the commercially available third-generation multi-slice spiral CT scanners, we propose a two-stage method that better exploits the complete reconstruction pipeline for LDCT denoising across different domains. Our method makes good use of the high redundancy of both the multi-slice projections and the volumetric reconstructions while avoiding the collapse of information in conventional cascaded frameworks. The dedicated design also provides a clearer interpretation of the workflow. Through extensive evaluations, we demonstrate its superior performance against state-of-the-art methods.
Filter Grafting for Deep Neural Networks
Feb 26, 2020


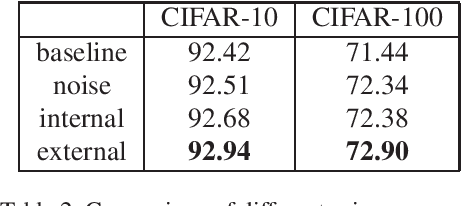
This paper proposes a new learning paradigm called filter grafting, which aims to improve the representation capability of Deep Neural Networks (DNNs). The motivation is that DNNs have unimportant (invalid) filters (e.g., l1 norm close to 0). These filters limit the potential of DNNs since they are identified as having little effect on the network. While filter pruning removes these invalid filters for efficiency consideration, filter grafting re-activates them from an accuracy boosting perspective. The activation is processed by grafting external information (weights) into invalid filters. To better perform the grafting process, we develop an entropy-based criterion to measure the information of filters and an adaptive weighting strategy for balancing the grafted information among networks. After the grafting operation, the network has very few invalid filters compared with its untouched state, enpowering the model with more representation capacity. We also perform extensive experiments on the classification and recognition tasks to show the superiority of our method. For example, the grafted MobileNetV2 outperforms the non-grafted MobileNetV2 by about 7 percent on CIFAR-100 dataset. Code is available at https://github.com/fxmeng/filter-grafting.git.