 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHISA: Efficient Hierarchical Indexing for Fine-Grained Sparse Attention
Apr 01, 2026Token-level sparse attention mechanisms, exemplified by DeepSeek Sparse Attention (DSA), achieve fine-grained key selection by scoring every historical key for each query through a lightweight indexer, then computing attention only on the selected subset. While the downstream sparse attention itself scales favorably, the indexer must still scan the entire prefix for every query, introducing an per-layer bottleneck that grows prohibitively with context length. We propose HISA (Hierarchical Indexed Sparse Attention), a plug-and-play replacement for the indexer that rewrites the search path from a flat token scan into a two-stage hierarchical procedure: (1) a block-level coarse filtering stage that scores pooled block representations to discard irrelevant regions, followed by (2) a token-level refinement stage that applies the original indexer exclusively within the retained candidate blocks. HISA preserves the identical token-level top-sparse pattern consumed by the downstream Sparse MLA operator and requires no additional training. On kernel-level benchmarks, HISA achieves up to speedup at 64K context. On Needle-in-a-Haystack and LongBench, we directly replace the indexer in DeepSeek-V3.2 and GLM-5 with our HISA indexer, without any finetuning. HISA closely matches the original DSA in quality, while substantially outperforming block-sparse baselines.
Breaking the Blocks: Continuous Low-Rank Decomposed Scaling for Unified LLM Quantization and Adaptation
Jan 30, 2026Current quantization methods for LLMs predominantly rely on block-wise structures to maintain efficiency, often at the cost of representational flexibility. In this work, we demonstrate that element-wise quantization can be made as efficient as block-wise scaling while providing strictly superior expressive power by modeling the scaling manifold as continuous low-rank matrices ($S = BA$). We propose Low-Rank Decomposed Scaling (LoRDS), a unified framework that rethinks quantization granularity through this low-rank decomposition. By "breaking the blocks" of spatial constraints, LoRDS establishes a seamless efficiency lifecycle: it provides high-fidelity PTQ initialization refined via iterative optimization, enables joint QAT of weights and scaling factors, and facilitates high-rank multiplicative PEFT adaptation. Unlike additive PEFT approaches such as QLoRA, LoRDS enables high-rank weight updates within a low-rank budget while incurring no additional inference overhead. Supported by highly optimized Triton kernels, LoRDS consistently outperforms state-of-the-art baselines across various model families in both quantization and downstream fine-tuning tasks. Notably, on Llama3-8B, our method achieves up to a 27.0% accuracy improvement at 3 bits over NormalFloat quantization and delivers a 1.5x inference speedup on NVIDIA RTX 4090 while enhancing PEFT performance by 9.6% on downstream tasks over 4bit QLoRA, offering a robust and integrated solution for unified compression and adaptation of LLMs.
BioPIE: A Biomedical Protocol Information Extraction Dataset for High-Reasoning-Complexity Experiment Question Answer
Jan 08, 2026Question Answer (QA) systems for biomedical experiments facilitate cross-disciplinary communication, and serve as a foundation for downstream tasks, e.g., laboratory automation. High Information Density (HID) and Multi-Step Reasoning (MSR) pose unique challenges for biomedical experimental QA. While extracting structured knowledge, e.g., Knowledge Graphs (KGs), can substantially benefit biomedical experimental QA. Existing biomedical datasets focus on general or coarsegrained knowledge and thus fail to support the fine-grained experimental reasoning demanded by HID and MSR. To address this gap, we introduce Biomedical Protocol Information Extraction Dataset (BioPIE), a dataset that provides procedure-centric KGs of experimental entities, actions, and relations at a scale that supports reasoning over biomedical experiments across protocols. We evaluate information extraction methods on BioPIE, and implement a QA system that leverages BioPIE, showcasing performance gains on test, HID, and MSR question sets, showing that the structured experimental knowledge in BioPIE underpins both AI-assisted and more autonomous biomedical experimentation.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
Hierarchically Encapsulated Representation for Protocol Design in Self-Driving Labs
Apr 04, 2025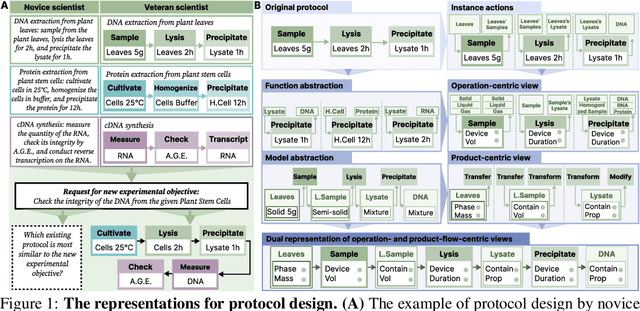

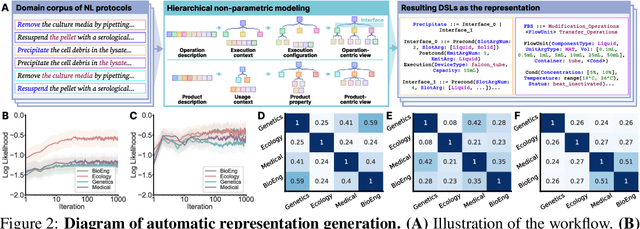
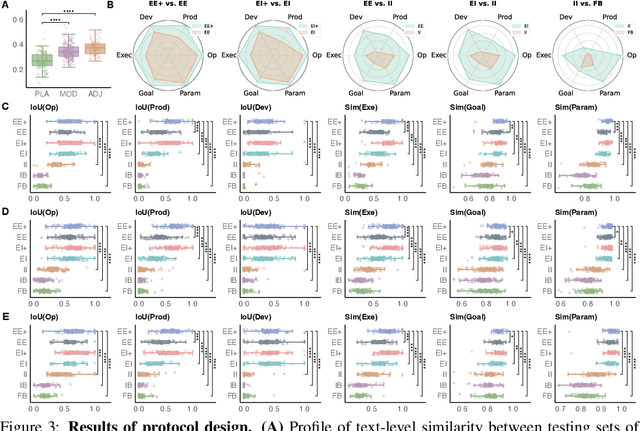
Self-driving laboratories have begun to replace human experimenters in performing single experimental skills or predetermined experimental protocols. However, as the pace of idea iteration in scientific research has been intensified by Artificial Intelligence, the demand for rapid design of new protocols for new discoveries become evident. Efforts to automate protocol design have been initiated, but the capabilities of knowledge-based machine designers, such as Large Language Models, have not been fully elicited, probably for the absence of a systematic representation of experimental knowledge, as opposed to isolated, flatten pieces of information. To tackle this issue, we propose a multi-faceted, multi-scale representation, where instance actions, generalized operations, and product flow models are hierarchically encapsulated using Domain-Specific Languages. We further develop a data-driven algorithm based on non-parametric modeling that autonomously customizes these representations for specific domains. The proposed representation is equipped with various machine designers to manage protocol design tasks, including planning, modification, and adjustment. The results demonstrate that the proposed method could effectively complement Large Language Models in the protocol design process, serving as an auxiliary module in the realm of machine-assisted scientific exploration.
LIFT: Improving Long Context Understanding of Large Language Models through Long Input Fine-Tuning
Feb 20, 2025Long context understanding remains challenging for large language models due to their limited context windows. This paper presents Long Input Fine-Tuning (LIFT), a novel framework for long-context modeling that can improve the long-context performance of arbitrary (short-context) LLMs by dynamically adapting model parameters based on the long input. Importantly, LIFT, rather than endlessly extending the context window size to accommodate increasingly longer inputs in context, chooses to store and absorb the long input in parameter. By fine-tuning the long input into model parameters, LIFT allows short-context LLMs to answer questions even when the required information is not provided in the context during inference. Furthermore, to enhance LIFT performance while maintaining the original in-context learning (ICL) capabilities, we introduce Gated Memory, a specialized attention adapter that automatically balances long input memorization and ICL. We provide a comprehensive analysis of the strengths and limitations of LIFT on long context understanding, offering valuable directions for future research.
TransMLA: Multi-head Latent Attention Is All You Need
Feb 11, 2025Modern large language models (LLMs) often encounter communication bottlenecks on current hardware, rather than purely computational constraints. Multi-head Latent Attention (MLA) tackles this challenge by using low-rank matrices in the key-value (KV) layers, thereby allowing compressed latent KV states to be cached. This approach significantly reduces the KV cache size relative to traditional multi-head attention, leading to faster inference. Moreover, MLA employs an up-projection matrix to increase expressiveness, trading additional computation for reduced communication overhead. Although MLA has demonstrated efficiency and effectiveness in Deepseek V2/V3/R1, many major model providers still rely on Group Query Attention (GQA) and have not announced any plans to adopt MLA. In this paper, we show that GQA can always be represented by MLA while maintaining the same KV cache overhead, but the converse does not hold. To encourage broader use of MLA, we introduce **TransMLA**, a post-training method that converts widely used GQA-based pre-trained models (e.g., LLaMA, Qwen, Mixtral) into MLA-based models. After conversion, the model can undergo additional training to boost expressiveness without increasing the KV cache size. Furthermore, we plan to develop MLA-specific inference acceleration techniques to preserve low latency in transformed models, thus enabling more efficient distillation of Deepseek R1.
LIFT: Improving Long Context Understanding Through Long Input Fine-Tuning
Dec 18, 2024Long context understanding remains challenging for large language models due to their limited context windows. This paper introduces Long Input Fine-Tuning (LIFT) for long context modeling, a novel framework that enhances LLM performance on long-context tasks by adapting model parameters to the context at test time. LIFT enables efficient processing of lengthy inputs without the computational burden of offline long-context adaptation, and can improve the long-context capabilities of arbitrary short-context models. The framework is further enhanced by integrating in-context learning and pre-LIFT supervised fine-tuning. The combination of in-context learning and LIFT enables short-context models like Llama 3 to handle arbitrarily long contexts and consistently improves their performance on popular long-context benchmarks like LooGLE and LongBench. We also provide a comprehensive analysis of the strengths and limitations of LIFT on long context understanding, offering valuable directions for future research.
CLOVER: Constrained Learning with Orthonormal Vectors for Eliminating Redundancy
Nov 26, 2024To adapt a well-trained large model to downstream tasks, we propose constraining learning within its original latent space by leveraging linear combinations of its basis vectors. This approach ensures stable training without compromising the model's capabilities. Traditionally, constructing orthonormal bases from a matrix requires a transfer matrix, which significantly increases storage and computational overhead for parameters and feature maps. In this paper, we introduce Absorb and Decompose for Q, K, V, and O matrices, enabling their orthogonalization without the need for transfer matrices. Furthermore, the Absorb-Decompose operation eliminates redundant vectors, reducing the encoder attention parameters of Whisper-large-v3 by 46.42% without requiring additional training. For parameter-efficient and stable fine-tuning, we orthonormalized Q, K, V, and O and fine-tuned only the singular values, allowing efficient adaptation while constraining changes to the original latent space. When fine-tuning LLaMA-2-7B on eight commonsense reasoning datasets, our method outperforms LoRA by 5.4% and DoRA by 4.4%.
Expert-level protocol translation for self-driving labs
Nov 01, 2024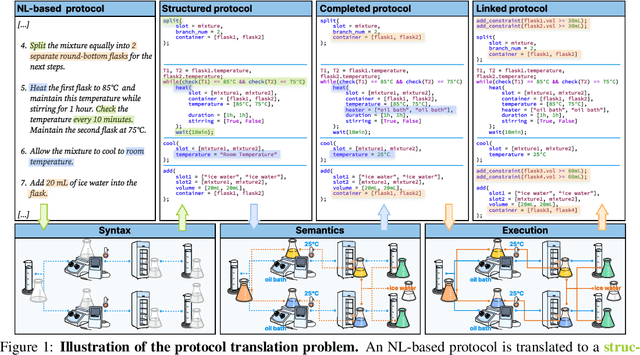
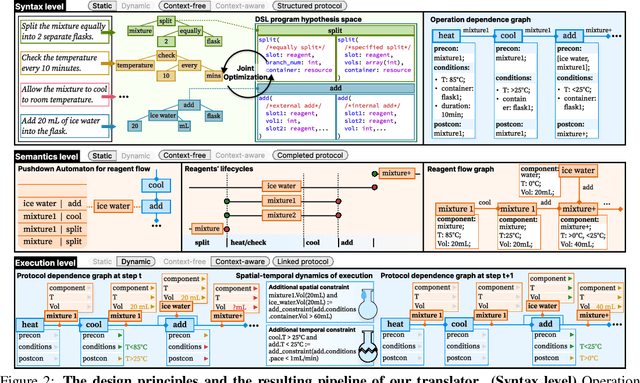
Recent development in Artificial Intelligence (AI) models has propelled their application in scientific discovery, but the validation and exploration of these discoveries require subsequent empirical experimentation. The concept of self-driving laboratories promises to automate and thus boost the experimental process following AI-driven discoveries. However, the transition of experimental protocols, originally crafted for human comprehension, into formats interpretable by machines presents significant challenges, which, within the context of specific expert domain, encompass the necessity for structured as opposed to natural language, the imperative for explicit rather than tacit knowledge, and the preservation of causality and consistency throughout protocol steps. Presently, the task of protocol translation predominantly requires the manual and labor-intensive involvement of domain experts and information technology specialists, rendering the process time-intensive. To address these issues, we propose a framework that automates the protocol translation process through a three-stage workflow, which incrementally constructs Protocol Dependence Graphs (PDGs) that approach structured on the syntax level, completed on the semantics level, and linked on the execution level. Quantitative and qualitative evaluations have demonstrated its performance at par with that of human experts, underscoring its potential to significantly expedite and democratize the process of scientific discovery by elevating the automation capabilities within self-driving laboratories.