 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteToken: Removing Intermediate Merge Residues From BPE Tokenizers
Feb 04, 2026Tokenization is fundamental to how language models represent and process text, yet the behavior of widely used BPE tokenizers has received far less study than model architectures and training. In this paper, we investigate intermediate merge residues in BPE vocabularies: tokens that are frequent during merge learning so that retained in the final vocabulary, but are mostly further merged and rarely emitted when tokenizing the corpus during tokenizer usage. Such low-frequency tokens not only waste vocabulary capacity but also increase vulnerability to adversarial or atypical inputs. We present a systematic empirical characterization of this phenomenon across commonly used tokenizers and introduce LiteToken, a simple method for removing residue tokens. Because the affected tokens are rarely used, pretrained models can often accommodate the modified tokenizer without additional fine-tuning. Experiments show that LiteToken reduces token fragmentation, reduces parameters, and improves robustness to noisy or misspelled inputs, while preserving overall performance.
Proof-RM: A Scalable and Generalizable Reward Model for Math Proof
Feb 02, 2026While Large Language Models (LLMs) have demonstrated strong math reasoning abilities through Reinforcement Learning with *Verifiable Rewards* (RLVR), many advanced mathematical problems are proof-based, with no guaranteed way to determine the authenticity of a proof by simple answer matching. To enable automatic verification, a Reward Model (RM) capable of reliably evaluating full proof processes is required. In this work, we design a *scalable* data-construction pipeline that, with minimal human effort, leverages LLMs to generate a large quantity of high-quality "**question-proof-check**" triplet data. By systematically varying problem sources, generation methods, and model configurations, we create diverse problem-proof pairs spanning multiple difficulty levels, linguistic styles, and error types, subsequently filtered through hierarchical human review for label alignment. Utilizing these data, we train a proof-checking RM, incorporating additional process reward and token weight balance to stabilize the RL process. Our experiments validate the model's scalability and strong performance from multiple perspectives, including reward accuracy, generalization ability and test-time guidance, providing important practical recipes and tools for strengthening LLM mathematical capabilities.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
VACT: A Video Automatic Causal Testing System and a Benchmark
Mar 08, 2025With the rapid advancement of text-conditioned Video Generation Models (VGMs), the quality of generated videos has significantly improved, bringing these models closer to functioning as ``*world simulators*'' and making real-world-level video generation more accessible and cost-effective. However, the generated videos often contain factual inaccuracies and lack understanding of fundamental physical laws. While some previous studies have highlighted this issue in limited domains through manual analysis, a comprehensive solution has not yet been established, primarily due to the absence of a generalized, automated approach for modeling and assessing the causal reasoning of these models across diverse scenarios. To address this gap, we propose VACT: an **automated** framework for modeling, evaluating, and measuring the causal understanding of VGMs in real-world scenarios. By combining causal analysis techniques with a carefully designed large language model assistant, our system can assess the causal behavior of models in various contexts without human annotation, which offers strong generalization and scalability. Additionally, we introduce multi-level causal evaluation metrics to provide a detailed analysis of the causal performance of VGMs. As a demonstration, we use our framework to benchmark several prevailing VGMs, offering insight into their causal reasoning capabilities. Our work lays the foundation for systematically addressing the causal understanding deficiencies in VGMs and contributes to advancing their reliability and real-world applicability.
LIFT: Improving Long Context Understanding of Large Language Models through Long Input Fine-Tuning
Feb 20, 2025Long context understanding remains challenging for large language models due to their limited context windows. This paper presents Long Input Fine-Tuning (LIFT), a novel framework for long-context modeling that can improve the long-context performance of arbitrary (short-context) LLMs by dynamically adapting model parameters based on the long input. Importantly, LIFT, rather than endlessly extending the context window size to accommodate increasingly longer inputs in context, chooses to store and absorb the long input in parameter. By fine-tuning the long input into model parameters, LIFT allows short-context LLMs to answer questions even when the required information is not provided in the context during inference. Furthermore, to enhance LIFT performance while maintaining the original in-context learning (ICL) capabilities, we introduce Gated Memory, a specialized attention adapter that automatically balances long input memorization and ICL. We provide a comprehensive analysis of the strengths and limitations of LIFT on long context understanding, offering valuable directions for future research.
Training Large Language Models to be Better Rule Followers
Feb 17, 2025Large language models (LLMs) have shown impressive performance across a wide range of tasks. However, they often exhibit unexpected failures in seemingly straightforward tasks, suggesting a reliance on case-based reasoning rather than rule-based reasoning. While the vast training corpus of LLMs contains numerous textual "rules", current training methods fail to leverage these rules effectively. Crucially, the relationships between these "rules" and their corresponding "instances" are not explicitly modeled. As a result, while LLMs can often recall rules with ease, they fail to apply these rules strictly and consistently in relevant reasoning scenarios. In this paper, we investigate the rule-following capabilities of LLMs and propose Meta Rule-Following Fine-Tuning (Meta-RFFT) to enhance the cross-task transferability of rule-following abilities. We first construct a dataset of 88 tasks requiring following rules, encompassing diverse reasoning domains. We demonstrate through extensive experiments that models trained on large-scale rule-following tasks are better rule followers, outperforming the baselines in both downstream fine-tuning and few-shot prompting scenarios. This highlights the cross-task transferability of models with the aid of Meta-RFFT. Furthermore, we examine the influence of factors such as dataset size, rule formulation, and in-context learning.
GL-Fusion: Rethinking the Combination of Graph Neural Network and Large Language model
Dec 08, 2024



Recent research on integrating Large Language Models (LLMs) with Graph Neural Networks (GNNs) typically follows two approaches: LLM-centered models, which convert graph data into tokens for LLM processing, and GNN-centered models, which use LLMs to encode text features into node and edge representations for GNN input. LLM-centered models often struggle to capture graph structures effectively, while GNN-centered models compress variable-length textual data into fixed-size vectors, limiting their ability to understand complex semantics. Additionally, GNN-centered approaches require converting tasks into a uniform, manually-designed format, restricting them to classification tasks and preventing language output. To address these limitations, we introduce a new architecture that deeply integrates GNN with LLM, featuring three key innovations: (1) Structure-Aware Transformers, which incorporate GNN's message-passing capabilities directly into LLM's transformer layers, allowing simultaneous processing of textual and structural information and generating outputs from both GNN and LLM; (2) Graph-Text Cross-Attention, which processes full, uncompressed text from graph nodes and edges, ensuring complete semantic integration; and (3) GNN-LLM Twin Predictor, enabling LLM's flexible autoregressive generation alongside GNN's scalable one-pass prediction. GL-Fusion achieves outstand performance on various tasks. Notably, it achieves state-of-the-art performance on OGBN-Arxiv and OGBG-Code2.
Number Cookbook: Number Understanding of Language Models and How to Improve It
Nov 06, 2024
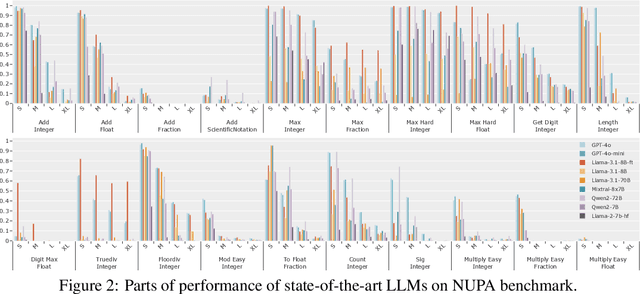
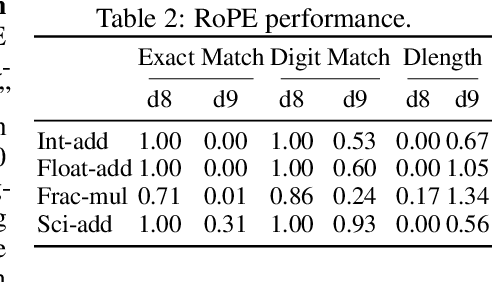
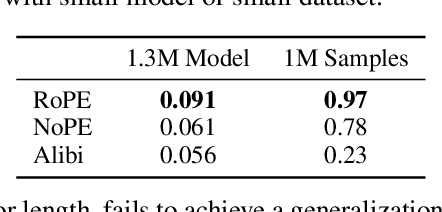
Large language models (LLMs) can solve an increasing number of complex reasoning tasks while making surprising mistakes in basic numerical understanding and processing (such as 9.11 > 9.9). The latter ability is essential for tackling complex arithmetic and mathematical problems and serves as a foundation for most reasoning tasks, but previous work paid little attention to it or only discussed several restricted tasks (like integer addition). In this paper, we comprehensively investigate the numerical understanding and processing ability (NUPA) of LLMs. Firstly, we introduce a benchmark covering four common numerical representations and 17 distinct numerical tasks in four major categories, resulting in 41 meaningful combinations in total. These tasks are derived from primary and secondary education curricula, encompassing nearly all everyday numerical understanding and processing scenarios, and the rules of these tasks are very simple and clear. Through the benchmark, we find that current LLMs fail frequently in many of the tasks. To study the problem, we train small models with existing and potential techniques for enhancing NUPA (such as special tokenizers, PEs, and number formats), comprehensively evaluating their effectiveness using our testbed. We also finetune practical-scale LLMs on our proposed NUPA tasks and find that 1) naive finetuning can improve NUPA a lot on many but not all tasks, and 2) surprisingly, techniques designed to enhance NUPA prove ineffective for finetuning pretrained models. We further explore the impact of chain-of-thought techniques on NUPA. Our work takes a preliminary step towards understanding and improving NUPA of LLMs. Our benchmark and code are released at https://github.com/GraphPKU/number_cookbook.
Case-Based or Rule-Based: How Do Transformers Do the Math?
Feb 27, 2024Despite the impressive performance in a variety of complex tasks, modern large language models (LLMs) still have trouble dealing with some math problems that are simple and intuitive for humans, such as addition. While we can easily learn basic rules of addition and apply them to new problems of any length, LLMs struggle to do the same. Instead, they may rely on similar "cases" seen in the training corpus for help. We define these two different reasoning mechanisms as "rule-based reasoning" and "case-based reasoning". Since rule-based reasoning is essential for acquiring the systematic generalization ability, we aim to explore exactly whether transformers use rule-based or case-based reasoning for math problems. Through carefully designed intervention experiments on five math tasks, we confirm that transformers are performing case-based reasoning, no matter whether scratchpad is used, which aligns with the previous observations that transformers use subgraph matching/shortcut learning to reason. To mitigate such problems, we propose a Rule-Following Fine-Tuning (RFFT) technique to teach transformers to perform rule-based reasoning. Specifically, we provide explicit rules in the input and then instruct transformers to recite and follow the rules step by step. Through RFFT, we successfully enable LLMs fine-tuned on 1-5 digit addition to generalize to up to 12-digit addition with over 95% accuracy, which is over 40% higher than scratchpad. The significant improvement demonstrates that teaching LLMs to explicitly use rules helps them learn rule-based reasoning and generalize better in length.
Chain of Images for Intuitively Reasoning
Nov 09, 2023The human brain is naturally equipped to comprehend and interpret visual information rapidly. When confronted with complex problems or concepts, we use flowcharts, sketches, and diagrams to aid our thought process. Leveraging this inherent ability can significantly enhance logical reasoning. However, current Large Language Models (LLMs) do not utilize such visual intuition to help their thinking. Even the most advanced version language models (e.g., GPT-4V and LLaVA) merely align images into textual space, which means their reasoning processes remain purely verbal. To mitigate such limitations, we present a Chain of Images (CoI) approach, which can convert complex language reasoning problems to simple pattern recognition by generating a series of images as intermediate representations. Furthermore, we have developed a CoI evaluation dataset encompassing 15 distinct domains where images can intuitively aid problem-solving. Based on this dataset, we aim to construct a benchmark to assess the capability of future multimodal large-scale models to leverage images for reasoning. In supporting our CoI reasoning, we introduce a symbolic multimodal large language model (SyMLLM) that generates images strictly based on language instructions and accepts both text and image as input. Experiments on Geometry, Chess and Common Sense tasks sourced from the CoI evaluation dataset show that CoI improves performance significantly over the pure-language Chain of Thoughts (CoT) baselines. The code is available at https://github.com/GraphPKU/CoI.