 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVACT: A Video Automatic Causal Testing System and a Benchmark
Mar 08, 2025With the rapid advancement of text-conditioned Video Generation Models (VGMs), the quality of generated videos has significantly improved, bringing these models closer to functioning as ``*world simulators*'' and making real-world-level video generation more accessible and cost-effective. However, the generated videos often contain factual inaccuracies and lack understanding of fundamental physical laws. While some previous studies have highlighted this issue in limited domains through manual analysis, a comprehensive solution has not yet been established, primarily due to the absence of a generalized, automated approach for modeling and assessing the causal reasoning of these models across diverse scenarios. To address this gap, we propose VACT: an **automated** framework for modeling, evaluating, and measuring the causal understanding of VGMs in real-world scenarios. By combining causal analysis techniques with a carefully designed large language model assistant, our system can assess the causal behavior of models in various contexts without human annotation, which offers strong generalization and scalability. Additionally, we introduce multi-level causal evaluation metrics to provide a detailed analysis of the causal performance of VGMs. As a demonstration, we use our framework to benchmark several prevailing VGMs, offering insight into their causal reasoning capabilities. Our work lays the foundation for systematically addressing the causal understanding deficiencies in VGMs and contributes to advancing their reliability and real-world applicability.
Local Causal Discovery with Background Knowledge
Aug 15, 2024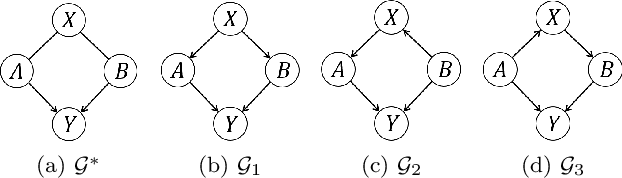
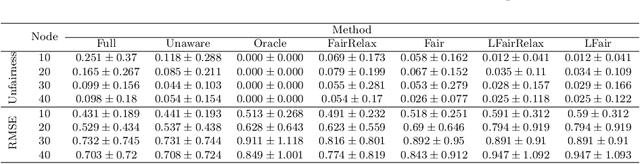
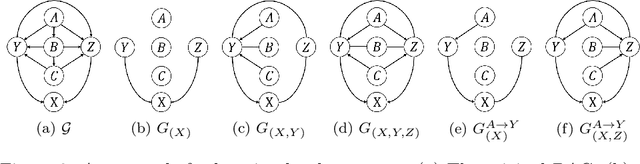
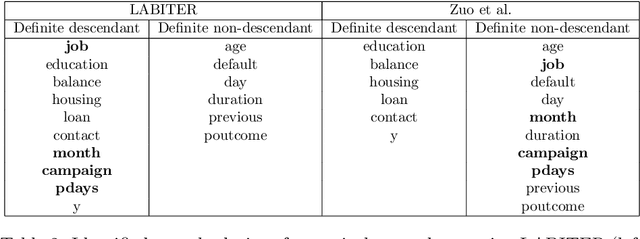
Causality plays a pivotal role in various fields of study. Based on the framework of causal graphical models, previous works have proposed identifying whether a variable is a cause or non-cause of a target in every Markov equivalent graph solely by learning a local structure. However, the presence of prior knowledge, often represented as a partially known causal graph, is common in many causal modeling applications. Leveraging this prior knowledge allows for the further identification of causal relationships. In this paper, we first propose a method for learning the local structure using all types of causal background knowledge, including direct causal information, non-ancestral information and ancestral information. Then we introduce criteria for identifying causal relationships based solely on the local structure in the presence of prior knowledge. We also apply out method to fair machine learning, and experiments involving local structure learning, causal relationship identification, and fair machine learning demonstrate that our method is both effective and efficient.
CAMS: CAnonicalized Manipulation Spaces for Category-Level Functional Hand-Object Manipulation Synthesis
Mar 25, 2023



In this work, we focus on a novel task of category-level functional hand-object manipulation synthesis covering both rigid and articulated object categories. Given an object geometry, an initial human hand pose as well as a sparse control sequence of object poses, our goal is to generate a physically reasonable hand-object manipulation sequence that performs like human beings. To address such a challenge, we first design CAnonicalized Manipulation Spaces (CAMS), a two-level space hierarchy that canonicalizes the hand poses in an object-centric and contact-centric view. Benefiting from the representation capability of CAMS, we then present a two-stage framework for synthesizing human-like manipulation animations. Our framework achieves state-of-the-art performance for both rigid and articulated categories with impressive visual effects. Codes and video results can be found at our project homepage: https://cams-hoi.github.io/
Learning Aesthetic Layouts via Visual Guidance
Jul 13, 2021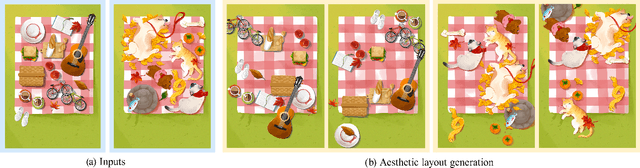


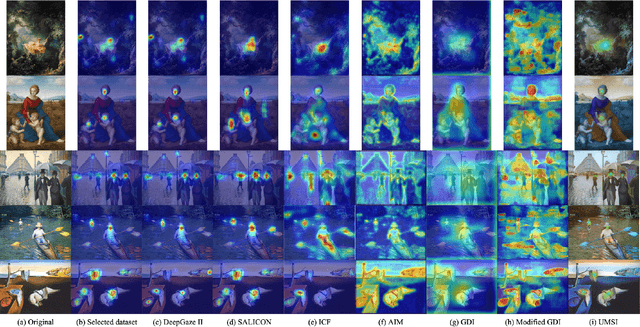
We explore computational approaches for visual guidance to aid in creating aesthetically pleasing art and graphic design. Our work complements and builds on previous work that developed models for how humans look at images. Our approach comprises three steps. First, we collected a dataset of art masterpieces and labeled the visual fixations with state-of-art vision models. Second, we clustered the visual guidance templates of the art masterpieces with unsupervised learning. Third, we developed a pipeline using generative adversarial networks to learn the principles of visual guidance and that can produce aesthetically pleasing layouts. We show that the aesthetic visual guidance principles can be learned and integrated into a high-dimensional model and can be queried by the features of graphic elements. We evaluate our approach by generating layouts on various drawings and graphic designs. Moreover, our model considers the color and structure of graphic elements when generating layouts. Consequently, we believe our tool, which generates multiple aesthetic layout options in seconds, can help artists create beautiful art and graphic designs.
Learning to Shade Hand-drawn Sketches
Feb 26, 2020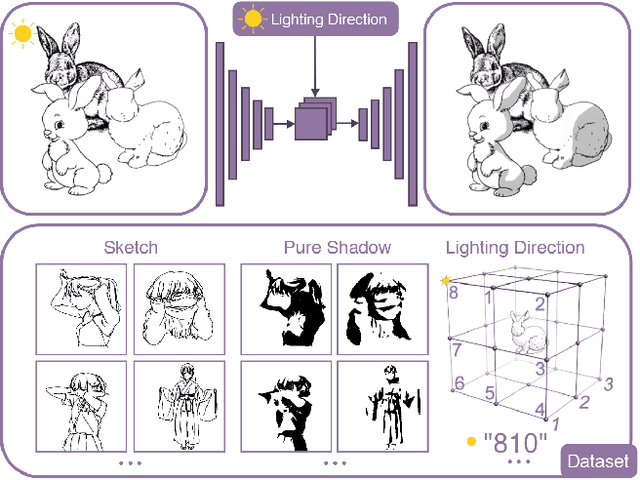
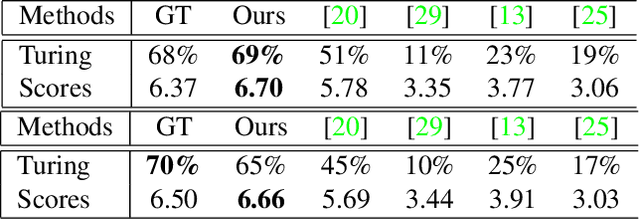
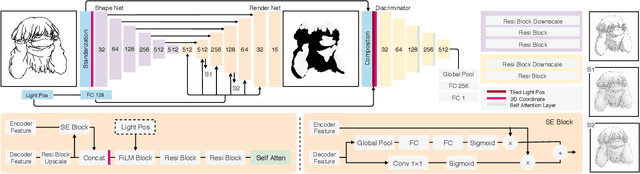

We present a fully automatic method to generate detailed and accurate artistic shadows from pairs of line drawing sketches and lighting directions. We also contribute a new dataset of one thousand examples of pairs of line drawings and shadows that are tagged with lighting directions. Remarkably, the generated shadows quickly communicate the underlying 3D structure of the sketched scene. Consequently, the shadows generated by our approach can be used directly or as an excellent starting point for artists. We demonstrate that the deep learning network we propose takes a hand-drawn sketch, builds a 3D model in latent space, and renders the resulting shadows. The generated shadows respect the hand-drawn lines and underlying 3D space and contain sophisticated and accurate details, such as self-shadowing effects. Moreover, the generated shadows contain artistic effects, such as rim lighting or halos appearing from back lighting, that would be achievable with traditional 3D rendering methods.