 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Aesthetic Layouts via Visual Guidance
Paper and Code
Jul 13, 2021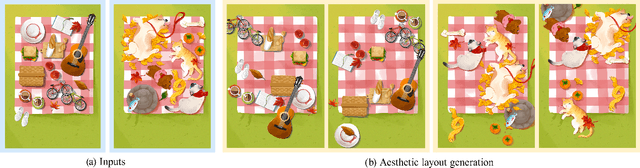


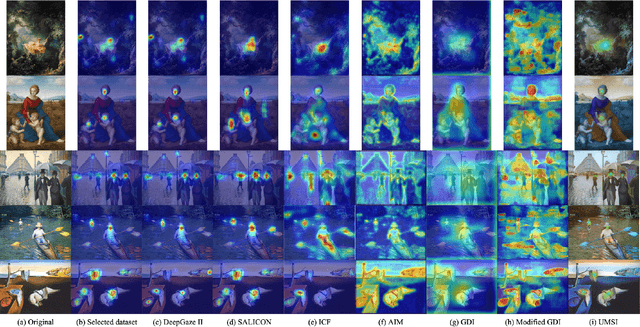
We explore computational approaches for visual guidance to aid in creating aesthetically pleasing art and graphic design. Our work complements and builds on previous work that developed models for how humans look at images. Our approach comprises three steps. First, we collected a dataset of art masterpieces and labeled the visual fixations with state-of-art vision models. Second, we clustered the visual guidance templates of the art masterpieces with unsupervised learning. Third, we developed a pipeline using generative adversarial networks to learn the principles of visual guidance and that can produce aesthetically pleasing layouts. We show that the aesthetic visual guidance principles can be learned and integrated into a high-dimensional model and can be queried by the features of graphic elements. We evaluate our approach by generating layouts on various drawings and graphic designs. Moreover, our model considers the color and structure of graphic elements when generating layouts. Consequently, we believe our tool, which generates multiple aesthetic layout options in seconds, can help artists create beautiful art and graphic designs.