 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Referenced Sketch Colorization Based on Animation Creation Workflow
Feb 27, 2025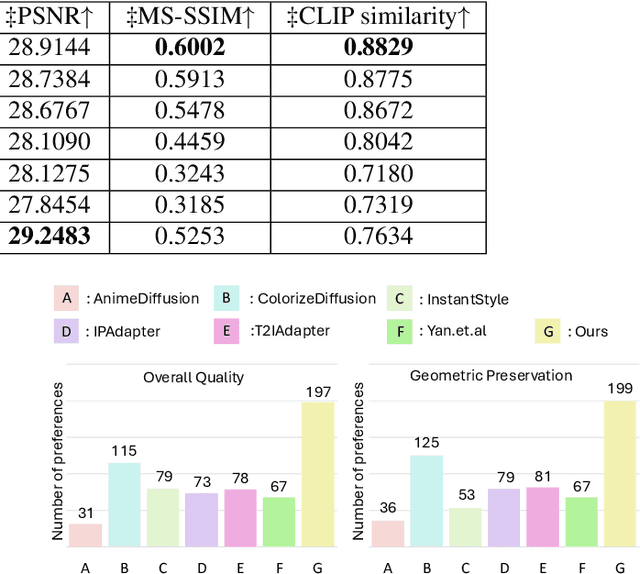
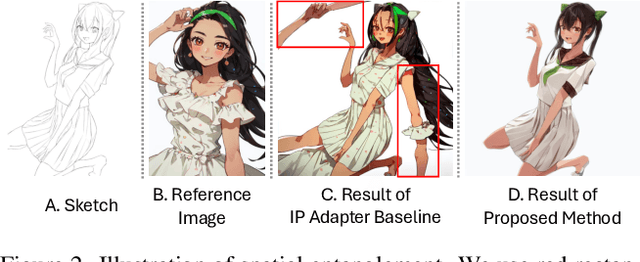

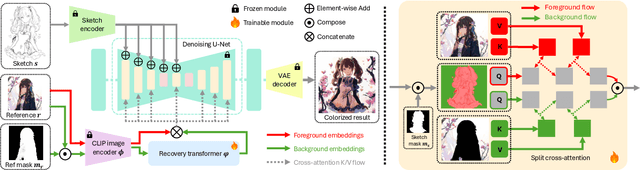
Sketch colorization plays an important role in animation and digital illustration production tasks. However, existing methods still meet problems in that text-guided methods fail to provide accurate color and style reference, hint-guided methods still involve manual operation, and image-referenced methods are prone to cause artifacts. To address these limitations, we propose a diffusion-based framework inspired by real-world animation production workflows. Our approach leverages the sketch as the spatial guidance and an RGB image as the color reference, and separately extracts foreground and background from the reference image with spatial masks. Particularly, we introduce a split cross-attention mechanism with LoRA (Low-Rank Adaptation) modules. They are trained separately with foreground and background regions to control the corresponding embeddings for keys and values in cross-attention. This design allows the diffusion model to integrate information from foreground and background independently, preventing interference and eliminating the spatial artifacts. During inference, we design switchable inference modes for diverse use scenarios by changing modules activated in the framework. Extensive qualitative and quantitative experiments, along with user studies, demonstrate our advantages over existing methods in generating high-qualigy artifact-free results with geometric mismatched references. Ablation studies further confirm the effectiveness of each component. Codes are available at https://github.com/ tellurion-kanata/colorizeDiffusion.
On Statistical Rates and Provably Efficient Criteria of Latent Diffusion Transformers (DiTs)
Jul 01, 2024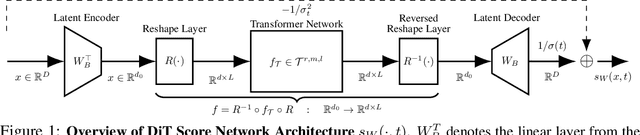
We investigate the statistical and computational limits of latent \textbf{Di}ffusion \textbf{T}ransformers (\textbf{DiT}s) under the low-dimensional linear latent space assumption. Statistically, we study the universal approximation and sample complexity of the DiTs score function, as well as the distribution recovery property of the initial data. Specifically, under mild data assumptions, we derive an approximation error bound for the score network of latent DiTs, which is sub-linear in the latent space dimension. Additionally, we derive the corresponding sample complexity bound and show that the data distribution generated from the estimated score function converges toward a proximate area of the original one. Computationally, we characterize the hardness of both forward inference and backward computation of latent DiTs, assuming the Strong Exponential Time Hypothesis (SETH). For forward inference, we identify efficient criteria for all possible latent DiTs inference algorithms and showcase our theory by pushing the efficiency toward almost-linear time inference. For backward computation, we leverage the low-rank structure within the gradient computation of DiTs training for possible algorithmic speedup. Specifically, we show that such speedup achieves almost-linear time latent DiTs training by casting the DiTs gradient as a series of chained low-rank approximations with bounded error. Under the low-dimensional assumption, we show that the convergence rate and the computational efficiency are both dominated by the dimension of the subspace, suggesting that latent DiTs have the potential to bypass the challenges associated with the high dimensionality of initial data.
Realtime Fewshot Portrait Stylization Based On Geometric Alignment
Nov 28, 2022



This paper presents a portrait stylization method designed for real-time mobile applications with limited style examples available. Previous learning based stylization methods suffer from the geometric and semantic gaps between portrait domain and style domain, which obstacles the style information to be correctly transferred to the portrait images, leading to poor stylization quality. Based on the geometric prior of human facial attributions, we propose to utilize geometric alignment to tackle this issue. Firstly, we apply Thin-Plate-Spline (TPS) on feature maps in the generator network and also directly to style images in pixel space, generating aligned portrait-style image pairs with identical landmarks, which closes the geometric gaps between two domains. Secondly, adversarial learning maps the textures and colors of portrait images to the style domain. Finally, geometric aware cycle consistency preserves the content and identity information unchanged, and deformation invariant constraint suppresses artifacts and distortions. Qualitative and quantitative comparison validate our method outperforms existing methods, and experiments proof our method could be trained with limited style examples (100 or less) in real-time (more than 40 FPS) on mobile devices. Ablation study demonstrates the effectiveness of each component in the framework.
The Animation Transformer: Visual Correspondence via Segment Matching
Sep 08, 2021

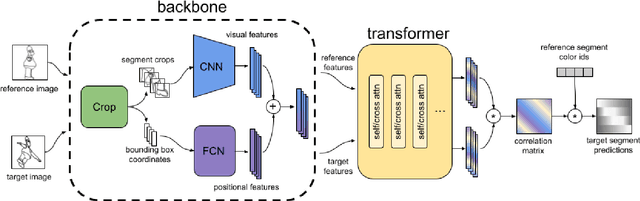
Visual correspondence is a fundamental building block on the way to building assistive tools for hand-drawn animation. However, while a large body of work has focused on learning visual correspondences at the pixel-level, few approaches have emerged to learn correspondence at the level of line enclosures (segments) that naturally occur in hand-drawn animation. Exploiting this structure in animation has numerous benefits: it avoids the intractable memory complexity of attending to individual pixels in high resolution images and enables the use of real-world animation datasets that contain correspondence information at the level of per-segment colors. To that end, we propose the Animation Transformer (AnT) which uses a transformer-based architecture to learn the spatial and visual relationships between segments across a sequence of images. AnT enables practical ML-assisted colorization for professional animation workflows and is publicly accessible as a creative tool in Cadmium.
Learning Aesthetic Layouts via Visual Guidance
Jul 13, 2021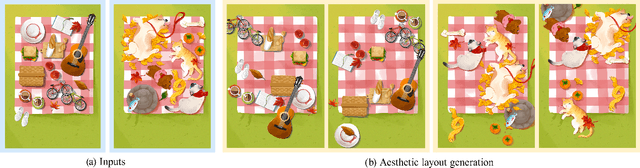


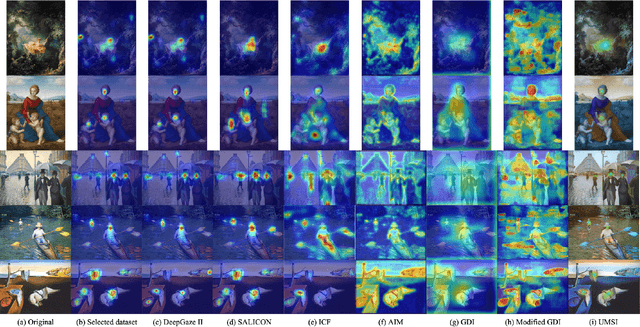
We explore computational approaches for visual guidance to aid in creating aesthetically pleasing art and graphic design. Our work complements and builds on previous work that developed models for how humans look at images. Our approach comprises three steps. First, we collected a dataset of art masterpieces and labeled the visual fixations with state-of-art vision models. Second, we clustered the visual guidance templates of the art masterpieces with unsupervised learning. Third, we developed a pipeline using generative adversarial networks to learn the principles of visual guidance and that can produce aesthetically pleasing layouts. We show that the aesthetic visual guidance principles can be learned and integrated into a high-dimensional model and can be queried by the features of graphic elements. We evaluate our approach by generating layouts on various drawings and graphic designs. Moreover, our model considers the color and structure of graphic elements when generating layouts. Consequently, we believe our tool, which generates multiple aesthetic layout options in seconds, can help artists create beautiful art and graphic designs.
Learning to Shade Hand-drawn Sketches
Feb 26, 2020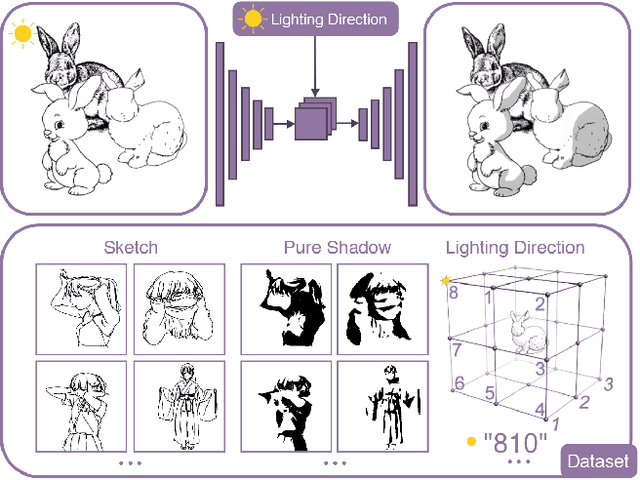
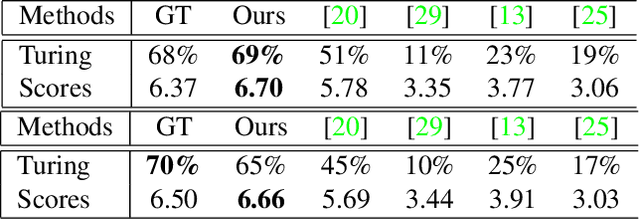
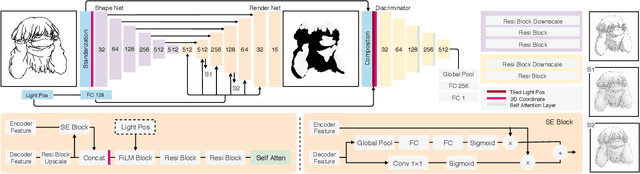

We present a fully automatic method to generate detailed and accurate artistic shadows from pairs of line drawing sketches and lighting directions. We also contribute a new dataset of one thousand examples of pairs of line drawings and shadows that are tagged with lighting directions. Remarkably, the generated shadows quickly communicate the underlying 3D structure of the sketched scene. Consequently, the shadows generated by our approach can be used directly or as an excellent starting point for artists. We demonstrate that the deep learning network we propose takes a hand-drawn sketch, builds a 3D model in latent space, and renders the resulting shadows. The generated shadows respect the hand-drawn lines and underlying 3D space and contain sophisticated and accurate details, such as self-shadowing effects. Moreover, the generated shadows contain artistic effects, such as rim lighting or halos appearing from back lighting, that would be achievable with traditional 3D rendering methods.