 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Constraint Generation with Design Intent in Parametric CAD
Apr 17, 2025



We adapt alignment techniques from reasoning LLMs to the task of generating engineering sketch constraints found in computer-aided design (CAD) models. Engineering sketches consist of geometric primitives (e.g. points, lines) connected by constraints (e.g. perpendicular, tangent) that define the relationships between them. For a design to be easily editable, the constraints must effectively capture design intent, ensuring the geometry updates predictably when parameters change. Although current approaches can generate CAD designs, an open challenge remains to align model outputs with design intent, we label this problem `design alignment'. A critical first step towards aligning generative CAD models is to generate constraints which fully-constrain all geometric primitives, without over-constraining or distorting sketch geometry. Using alignment techniques to train an existing constraint generation model with feedback from a constraint solver, we are able to fully-constrain 93% of sketches compared to 34% when using a na\"ive supervised fine-tuning (SFT) baseline and only 8.9% without alignment. Our approach can be applied to any existing constraint generation model and sets the stage for further research bridging alignment strategies between the language and design domains.
DeepAD: A Robust Deep Learning Model of Alzheimer's Disease Progression for Real-World Clinical Applications
Apr 08, 2022
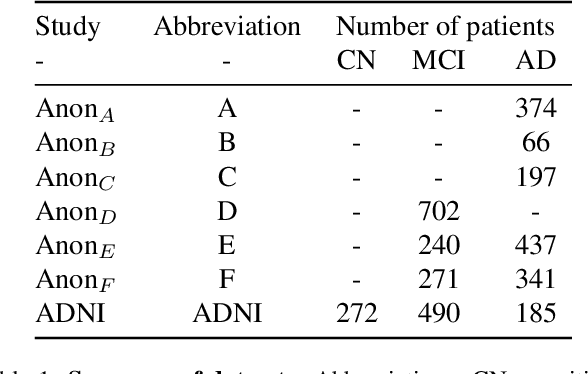
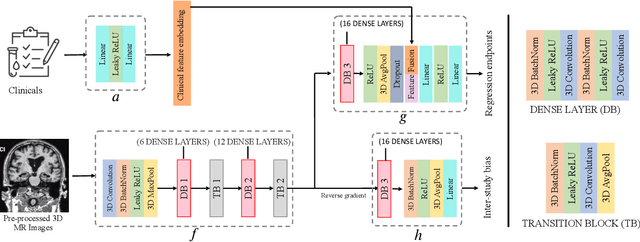
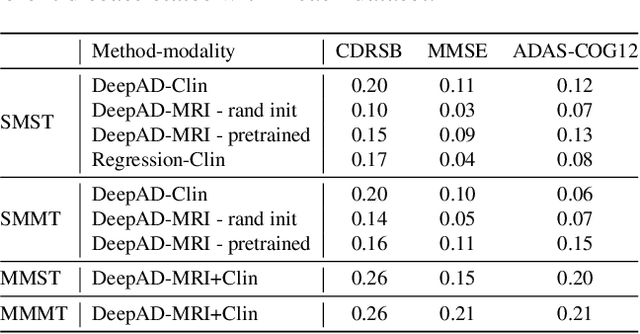
The ability to predict the future trajectory of a patient is a key step toward the development of therapeutics for complex diseases such as Alzheimer's disease (AD). However, most machine learning approaches developed for prediction of disease progression are either single-task or single-modality models, which can not be directly adopted to our setting involving multi-task learning with high dimensional images. Moreover, most of those approaches are trained on a single dataset (i.e. cohort), which can not be generalized to other cohorts. We propose a novel multimodal multi-task deep learning model to predict AD progression by analyzing longitudinal clinical and neuroimaging data from multiple cohorts. Our proposed model integrates high dimensional MRI features from a 3D convolutional neural network with other data modalities, including clinical and demographic information, to predict the future trajectory of patients. Our model employs an adversarial loss to alleviate the study-specific imaging bias, in particular the inter-study domain shifts. In addition, a Sharpness-Aware Minimization (SAM) optimization technique is applied to further improve model generalization. The proposed model is trained and tested on various datasets in order to evaluate and validate the results. Our results showed that 1) our model yields significant improvement over the baseline models, and 2) models using extracted neuroimaging features from 3D convolutional neural network outperform the same models when applied to MRI-derived volumetric features.
The Animation Transformer: Visual Correspondence via Segment Matching
Sep 08, 2021

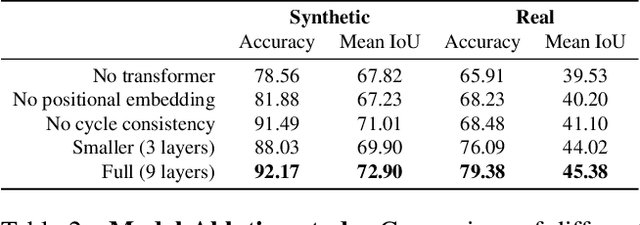
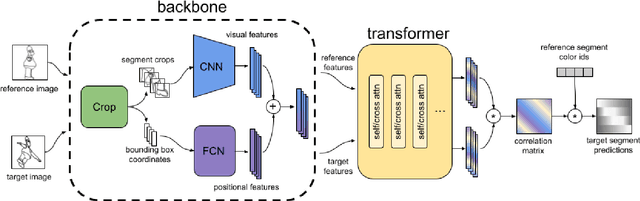
Visual correspondence is a fundamental building block on the way to building assistive tools for hand-drawn animation. However, while a large body of work has focused on learning visual correspondences at the pixel-level, few approaches have emerged to learn correspondence at the level of line enclosures (segments) that naturally occur in hand-drawn animation. Exploiting this structure in animation has numerous benefits: it avoids the intractable memory complexity of attending to individual pixels in high resolution images and enables the use of real-world animation datasets that contain correspondence information at the level of per-segment colors. To that end, we propose the Animation Transformer (AnT) which uses a transformer-based architecture to learn the spatial and visual relationships between segments across a sequence of images. AnT enables practical ML-assisted colorization for professional animation workflows and is publicly accessible as a creative tool in Cadmium.