 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Animation Transformer: Visual Correspondence via Segment Matching
Paper and Code
Sep 08, 2021

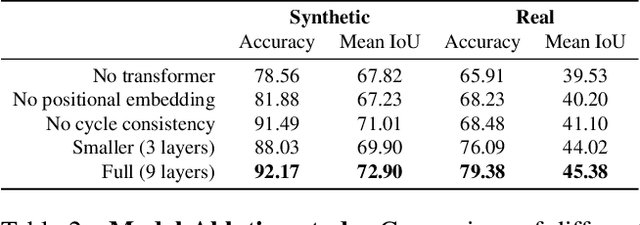
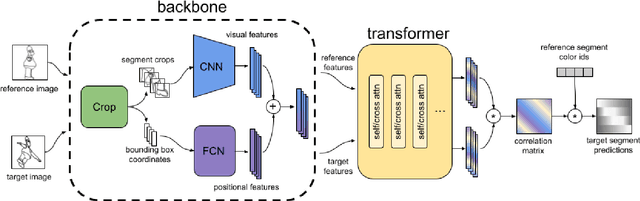
Visual correspondence is a fundamental building block on the way to building assistive tools for hand-drawn animation. However, while a large body of work has focused on learning visual correspondences at the pixel-level, few approaches have emerged to learn correspondence at the level of line enclosures (segments) that naturally occur in hand-drawn animation. Exploiting this structure in animation has numerous benefits: it avoids the intractable memory complexity of attending to individual pixels in high resolution images and enables the use of real-world animation datasets that contain correspondence information at the level of per-segment colors. To that end, we propose the Animation Transformer (AnT) which uses a transformer-based architecture to learn the spatial and visual relationships between segments across a sequence of images. AnT enables practical ML-assisted colorization for professional animation workflows and is publicly accessible as a creative tool in Cadmium.