 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombiGraph-Vis: A Curated Multimodal Olympiad Benchmark for Discrete Mathematical Reasoning
Oct 31, 2025State-of-the-art (SOTA) LLMs have progressed from struggling on proof-based Olympiad problems to solving most of the IMO 2025 problems, with leading systems reportedly handling 5 of 6 problems. Given this progress, we assess how well these models can grade proofs: detecting errors, judging their severity, and assigning fair scores beyond binary correctness. We study proof-analysis capabilities using a corpus of 90 Gemini 2.5 Pro-generated solutions that we grade on a 1-4 scale with detailed error annotations, and on MathArena solution sets for IMO/USAMO 2025 scored on a 0-7 scale. Our analysis shows that models can reliably flag incorrect (including subtly incorrect) solutions but exhibit calibration gaps in how partial credit is assigned. To address this, we introduce agentic workflows that extract and analyze reference solutions and automatically derive problem-specific rubrics for a multi-step grading process. We instantiate and compare different design choices for the grading workflows, and evaluate their trade-offs. Across our annotated corpus and MathArena, our proposed workflows achieve higher agreement with human grades and more consistent handling of partial credit across metrics. We release all code, data, and prompts/logs to facilitate future research.
Aligning Constraint Generation with Design Intent in Parametric CAD
Apr 17, 2025



We adapt alignment techniques from reasoning LLMs to the task of generating engineering sketch constraints found in computer-aided design (CAD) models. Engineering sketches consist of geometric primitives (e.g. points, lines) connected by constraints (e.g. perpendicular, tangent) that define the relationships between them. For a design to be easily editable, the constraints must effectively capture design intent, ensuring the geometry updates predictably when parameters change. Although current approaches can generate CAD designs, an open challenge remains to align model outputs with design intent, we label this problem `design alignment'. A critical first step towards aligning generative CAD models is to generate constraints which fully-constrain all geometric primitives, without over-constraining or distorting sketch geometry. Using alignment techniques to train an existing constraint generation model with feedback from a constraint solver, we are able to fully-constrain 93% of sketches compared to 34% when using a na\"ive supervised fine-tuning (SFT) baseline and only 8.9% without alignment. Our approach can be applied to any existing constraint generation model and sets the stage for further research bridging alignment strategies between the language and design domains.
Brains vs. Bytes: Evaluating LLM Proficiency in Olympiad Mathematics
Apr 01, 2025Recent advancements in large language models (LLMs) have shown impressive progress in mathematical reasoning tasks. However, current evaluation benchmarks predominantly focus on the accuracy of final answers, often overlooking the logical rigor crucial for mathematical problem-solving. The claim that state-of-the-art LLMs can solve Math Olympiad-level problems requires closer examination. To explore this, we conducted both qualitative and quantitative human evaluations of proofs generated by LLMs, and developed a schema for automatically assessing their reasoning capabilities. Our study reveals that current LLMs fall significantly short of solving challenging Olympiad-level problems and frequently fail to distinguish correct mathematical reasoning from clearly flawed solutions. We also found that occasional correct final answers provided by LLMs often result from pattern recognition or heuristic shortcuts rather than genuine mathematical reasoning. These findings underscore the substantial gap between LLM performance and human expertise in advanced mathematical reasoning and highlight the importance of developing benchmarks that prioritize the rigor and coherence of mathematical arguments rather than merely the correctness of final answers.
CadVLM: Bridging Language and Vision in the Generation of Parametric CAD Sketches
Sep 26, 2024



Parametric Computer-Aided Design (CAD) is central to contemporary mechanical design. However, it encounters challenges in achieving precise parametric sketch modeling and lacks practical evaluation metrics suitable for mechanical design. We harness the capabilities of pre-trained foundation models, renowned for their successes in natural language processing and computer vision, to develop generative models specifically for CAD. These models are adept at understanding complex geometries and design reasoning, a crucial advancement in CAD technology. In this paper, we propose CadVLM, an end-to-end vision language model for CAD generation. Our approach involves adapting pre-trained foundation models to manipulate engineering sketches effectively, integrating both sketch primitive sequences and sketch images. Extensive experiments demonstrate superior performance on multiple CAD sketch generation tasks such as CAD autocompletion, CAD autoconstraint, and image conditional generation. To our knowledge, this is the first instance of a multimodal Large Language Model (LLM) being successfully applied to parametric CAD generation, representing a pioneering step in the field of computer-aided mechanical design.
MMLU-Pro+: Evaluating Higher-Order Reasoning and Shortcut Learning in LLMs
Sep 03, 2024Existing benchmarks for large language models (LLMs) increasingly struggle to differentiate between top-performing models, underscoring the need for more challenging evaluation frameworks. We introduce MMLU-Pro+, an enhanced benchmark building upon MMLU-Pro to assess shortcut learning and higher-order reasoning in LLMs. By incorporating questions with multiple correct answers across diverse domains, MMLU-Pro+ tests LLMs' ability to engage in complex reasoning and resist simplistic problem-solving strategies. Our results show that MMLU-Pro+ maintains MMLU-Pro's difficulty while providing a more rigorous test of model discrimination, particularly in multi-correct answer scenarios. We introduce novel metrics like shortcut selection ratio and correct pair identification ratio, offering deeper insights into model behavior and anchoring bias. Evaluations of five state-of-the-art LLMs reveal significant performance gaps, highlighting variations in reasoning abilities and bias susceptibility. We release the dataset and evaluation codes at \url{https://github.com/asgsaeid/mmlu-pro-plus}.
Learned Visual Features to Textual Explanations
Sep 01, 2023Interpreting the learned features of vision models has posed a longstanding challenge in the field of machine learning. To address this issue, we propose a novel method that leverages the capabilities of large language models (LLMs) to interpret the learned features of pre-trained image classifiers. Our method, called TExplain, tackles this task by training a neural network to establish a connection between the feature space of image classifiers and LLMs. Then, during inference, our approach generates a vast number of sentences to explain the features learned by the classifier for a given image. These sentences are then used to extract the most frequent words, providing a comprehensive understanding of the learned features and patterns within the classifier. Our method, for the first time, utilizes these frequent words corresponding to a visual representation to provide insights into the decision-making process of the independently trained classifier, enabling the detection of spurious correlations, biases, and a deeper comprehension of its behavior. To validate the effectiveness of our approach, we conduct experiments on diverse datasets, including ImageNet-9L and Waterbirds. The results demonstrate the potential of our method to enhance the interpretability and robustness of image classifiers.
Robust Representation Learning via Perceptual Similarity Metrics
Jun 11, 2021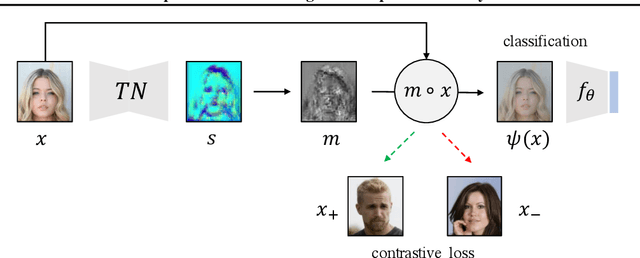
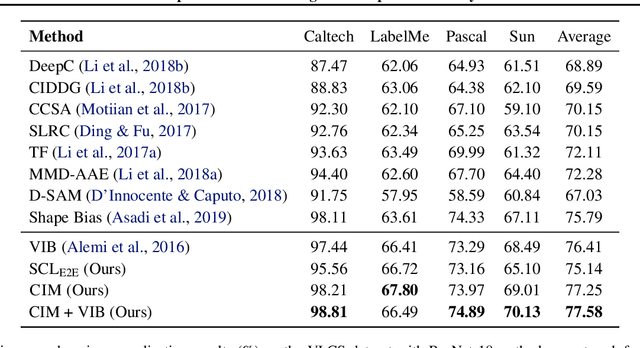
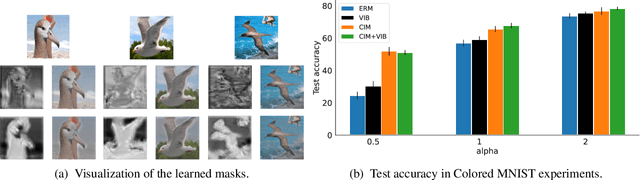
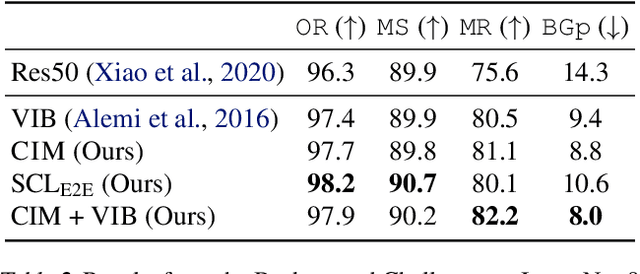
A fundamental challenge in artificial intelligence is learning useful representations of data that yield good performance on a downstream task, without overfitting to spurious input features. Extracting such task-relevant predictive information is particularly difficult for real-world datasets. In this work, we propose Contrastive Input Morphing (CIM), a representation learning framework that learns input-space transformations of the data to mitigate the effect of irrelevant input features on downstream performance. Our method leverages a perceptual similarity metric via a triplet loss to ensure that the transformation preserves task-relevant information.Empirically, we demonstrate the efficacy of our approach on tasks which typically suffer from the presence of spurious correlations: classification with nuisance information, out-of-distribution generalization, and preservation of subgroup accuracies. We additionally show that CIM is complementary to other mutual information-based representation learning techniques, and demonstrate that it improves the performance of variational information bottleneck (VIB) when used together.
UVStyle-Net: Unsupervised Few-shot Learning of 3D Style Similarity Measure for B-Reps
Apr 28, 2021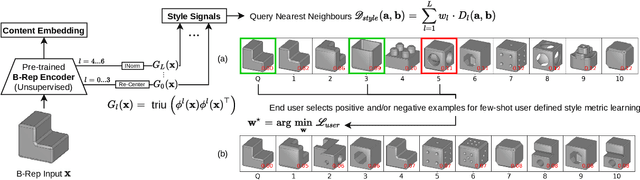
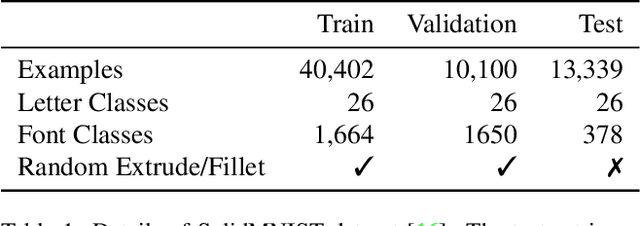

Boundary Representations (B-Reps) are the industry standard in 3D Computer Aided Design/Manufacturing (CAD/CAM) and industrial design due to their fidelity in representing stylistic details. However, they have been ignored in the 3D style research. Existing 3D style metrics typically operate on meshes or pointclouds, and fail to account for end-user subjectivity by adopting fixed definitions of style, either through crowd-sourcing for style labels or hand-crafted features. We propose UVStyle-Net, a style similarity measure for B-Reps that leverages the style signals in the second order statistics of the activations in a pre-trained (unsupervised) 3D encoder, and learns their relative importance to a subjective end-user through few-shot learning. Our approach differs from all existing data-driven 3D style methods since it may be used in completely unsupervised settings, which is desirable given the lack of publicly available labelled B-Rep datasets. More importantly, the few-shot learning accounts for the inherent subjectivity associated with style. We show quantitatively that our proposed method with B-Reps is able to capture stronger style signals than alternative methods on meshes and pointclouds despite its significantly greater computational efficiency. We also show it is able to generate meaningful style gradients with respect to the input shape, and that few-shot learning with as few as two positive examples selected by an end-user is sufficient to significantly improve the style measure. Finally, we demonstrate its efficacy on a large unlabeled public dataset of CAD models. Source code and data will be released in the future.