 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperdimensional Cross-Modal Alignment of Frozen Language and Image Models for Efficient Image Captioning
Feb 27, 2026Large unimodal foundation models for vision and language encode rich semantic structures, yet aligning them typically requires computationally intensive multimodal fine-tuning. Such approaches depend on large-scale parameter updates, are resource intensive, and can perturb pretrained representations. Emerging evidence suggests, however, that independently trained foundation models may already exhibit latent semantic compatibility, reflecting shared structures in the data they model. This raises a fundamental question: can cross-modal alignment be achieved without modifying the models themselves? Here we introduce HDFLIM (HyperDimensional computing with Frozen Language and Image Models), a framework that establishes cross-modal mappings while keeping pretrained vision and language models fully frozen. HDFLIM projects unimodal embeddings into a shared hyperdimensional space and leverages lightweight symbolic operations -- binding, bundling, and similarity-based retrieval to construct associative cross-modal representations in a single pass over the data. Caption generation emerges from high-dimensional memory retrieval rather than iterative gradient-based optimization. We show that HDFLIM achieves performance comparable to end-to-end vision-language training methods and produces captions that are more semantically grounded than zero-shot baselines. By decoupling alignment from parameter tuning, our results suggest that semantic mapping across foundation models can be realized through symbolic operations on hyperdimensional encodings of the respective embeddings. More broadly, this work points toward an alternative paradigm for foundation model alignment in which frozen models are integrated through structured representational mappings rather than through large-scale retraining. The codebase for our implementation can be found at https://github.com/Abhishek-Dalvi410/HDFLIM.
CombiGraph-Vis: A Curated Multimodal Olympiad Benchmark for Discrete Mathematical Reasoning
Oct 31, 2025State-of-the-art (SOTA) LLMs have progressed from struggling on proof-based Olympiad problems to solving most of the IMO 2025 problems, with leading systems reportedly handling 5 of 6 problems. Given this progress, we assess how well these models can grade proofs: detecting errors, judging their severity, and assigning fair scores beyond binary correctness. We study proof-analysis capabilities using a corpus of 90 Gemini 2.5 Pro-generated solutions that we grade on a 1-4 scale with detailed error annotations, and on MathArena solution sets for IMO/USAMO 2025 scored on a 0-7 scale. Our analysis shows that models can reliably flag incorrect (including subtly incorrect) solutions but exhibit calibration gaps in how partial credit is assigned. To address this, we introduce agentic workflows that extract and analyze reference solutions and automatically derive problem-specific rubrics for a multi-step grading process. We instantiate and compare different design choices for the grading workflows, and evaluate their trade-offs. Across our annotated corpus and MathArena, our proposed workflows achieve higher agreement with human grades and more consistent handling of partial credit across metrics. We release all code, data, and prompts/logs to facilitate future research.
Simple Denoising Diffusion Language Models
Oct 27, 2025Diffusion models have recently been extended to language generation through Masked Diffusion Language Models (MDLMs), which achieve performance competitive with strong autoregressive models. However, MDLMs tend to degrade in the few-step regime and cannot directly adopt existing few-step distillation methods designed for continuous diffusion models, as they lack the intrinsic property of mapping from noise to data. Recent Uniform-state Diffusion Models (USDMs), initialized from a uniform prior, alleviate some limitations but still suffer from complex loss formulations that hinder scalability. In this work, we propose a simplified denoising-based loss for USDMs that optimizes only noise-replaced tokens, stabilizing training and matching ELBO-level performance. Furthermore, by framing denoising as self-supervised learning, we introduce a simple modification to our denoising loss with contrastive-inspired negative gradients, which is practical and yield additional improvements in generation quality.
Brains vs. Bytes: Evaluating LLM Proficiency in Olympiad Mathematics
Apr 01, 2025Recent advancements in large language models (LLMs) have shown impressive progress in mathematical reasoning tasks. However, current evaluation benchmarks predominantly focus on the accuracy of final answers, often overlooking the logical rigor crucial for mathematical problem-solving. The claim that state-of-the-art LLMs can solve Math Olympiad-level problems requires closer examination. To explore this, we conducted both qualitative and quantitative human evaluations of proofs generated by LLMs, and developed a schema for automatically assessing their reasoning capabilities. Our study reveals that current LLMs fall significantly short of solving challenging Olympiad-level problems and frequently fail to distinguish correct mathematical reasoning from clearly flawed solutions. We also found that occasional correct final answers provided by LLMs often result from pattern recognition or heuristic shortcuts rather than genuine mathematical reasoning. These findings underscore the substantial gap between LLM performance and human expertise in advanced mathematical reasoning and highlight the importance of developing benchmarks that prioritize the rigor and coherence of mathematical arguments rather than merely the correctness of final answers.
A practical guide to machine learning interatomic potentials -- Status and future
Mar 12, 2025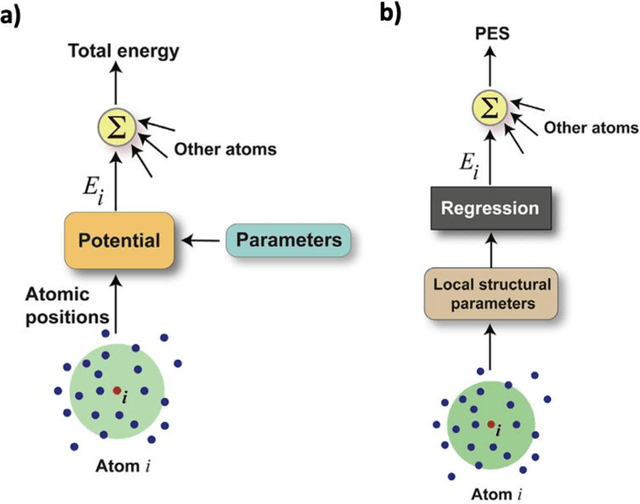

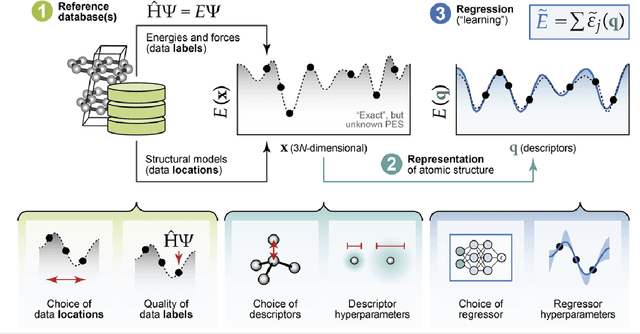
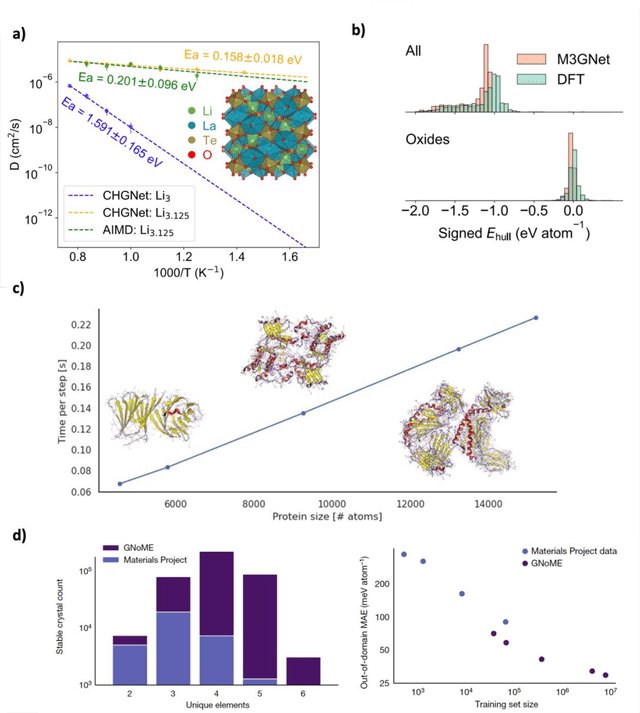
The rapid development and large body of literature on machine learning interatomic potentials (MLIPs) can make it difficult to know how to proceed for researchers who are not experts but wish to use these tools. The spirit of this review is to help such researchers by serving as a practical, accessible guide to the state-of-the-art in MLIPs. This review paper covers a broad range of topics related to MLIPs, including (i) central aspects of how and why MLIPs are enablers of many exciting advancements in molecular modeling, (ii) the main underpinnings of different types of MLIPs, including their basic structure and formalism, (iii) the potentially transformative impact of universal MLIPs for both organic and inorganic systems, including an overview of the most recent advances, capabilities, downsides, and potential applications of this nascent class of MLIPs, (iv) a practical guide for estimating and understanding the execution speed of MLIPs, including guidance for users based on hardware availability, type of MLIP used, and prospective simulation size and time, (v) a manual for what MLIP a user should choose for a given application by considering hardware resources, speed requirements, energy and force accuracy requirements, as well as guidance for choosing pre-trained potentials or fitting a new potential from scratch, (vi) discussion around MLIP infrastructure, including sources of training data, pre-trained potentials, and hardware resources for training, (vii) summary of some key limitations of present MLIPs and current approaches to mitigate such limitations, including methods of including long-range interactions, handling magnetic systems, and treatment of excited states, and finally (viii) we finish with some more speculative thoughts on what the future holds for the development and application of MLIPs over the next 3-10+ years.
C-HDNet: A Fast Hyperdimensional Computing Based Method for Causal Effect Estimation from Networked Observational Data
Jan 27, 2025We consider the problem of estimating causal effects from observational data in the presence of network confounding. In this context, an individual's treatment assignment and outcomes may be affected by their neighbors within the network. We propose a novel matching technique which leverages hyperdimensional computing to model network information and improve predictive performance. We present results of extensive experiments which show that the proposed method outperforms or is competitive with the state-of-the-art methods for causal effect estimation from network data, including advanced computationally demanding deep learning methods. Further, our technique benefits from simplicity and speed, with roughly an order of magnitude lower runtime compared to state-of-the-art methods, while offering similar causal effect estimation error rates.
Deep Learning within Tabular Data: Foundations, Challenges, Advances and Future Directions
Jan 07, 2025Tabular data remains one of the most prevalent data types across a wide range of real-world applications, yet effective representation learning for this domain poses unique challenges due to its irregular patterns, heterogeneous feature distributions, and complex inter-column dependencies. This survey provides a comprehensive review of state-of-the-art techniques in tabular data representation learning, structured around three foundational design elements: training data, neural architectures, and learning objectives. Unlike prior surveys that focus primarily on either architecture design or learning strategies, we adopt a holistic perspective that emphasizes the universality and robustness of representation learning methods across diverse downstream tasks. We examine recent advances in data augmentation and generation, specialized neural network architectures tailored to tabular data, and innovative learning objectives that enhance representation quality. Additionally, we highlight the growing influence of self-supervised learning and the adaptation of transformer-based foundation models for tabular data. Our review is based on a systematic literature search using rigorous inclusion criteria, encompassing 127 papers published since 2020 in top-tier conferences and journals. Through detailed analysis and comparison, we identify emerging trends, critical gaps, and promising directions for future research, aiming to guide the development of more generalizable and effective tabular data representation methods.
Regression with Large Language Models for Materials and Molecular Property Prediction
Sep 09, 2024



We demonstrate the ability of large language models (LLMs) to perform material and molecular property regression tasks, a significant deviation from the conventional LLM use case. We benchmark the Large Language Model Meta AI (LLaMA) 3 on several molecular properties in the QM9 dataset and 24 materials properties. Only composition-based input strings are used as the model input and we fine tune on only the generative loss. We broadly find that LLaMA 3, when fine-tuned using the SMILES representation of molecules, provides useful regression results which can rival standard materials property prediction models like random forest or fully connected neural networks on the QM9 dataset. Not surprisingly, LLaMA 3 errors are 5-10x higher than those of the state-of-the-art models that were trained using far more granular representation of molecules (e.g., atom types and their coordinates) for the same task. Interestingly, LLaMA 3 provides improved predictions compared to GPT-3.5 and GPT-4o. This work highlights the versatility of LLMs, suggesting that LLM-like generative models can potentially transcend their traditional applications to tackle complex physical phenomena, thus paving the way for future research and applications in chemistry, materials science and other scientific domains.
Causal Effect Estimation Using Random Hyperplane Tessellations
Apr 16, 2024



Matching is one of the simplest approaches for estimating causal effects from observational data. Matching techniques compare the observed outcomes across pairs of individuals with similar covariate values but different treatment statuses in order to estimate causal effects. However, traditional matching techniques are unreliable given high-dimensional covariates due to the infamous curse of dimensionality. To overcome this challenge, we propose a simple, fast, yet highly effective approach to matching using Random Hyperplane Tessellations (RHPT). First, we prove that the RHPT representation is an approximate balancing score -- thus maintaining the strong ignorability assumption -- and provide empirical evidence for this claim. Second, we report results of extensive experiments showing that matching using RHPT outperforms traditional matching techniques and is competitive with state-of-the-art deep learning methods for causal effect estimation. In addition, RHPT avoids the need for computationally expensive training of deep neural networks.
One-Shot Graph Representation Learning Using Hyperdimensional Computing
Feb 26, 2024



We present a novel, simple, fast, and efficient approach for semi-supervised learning on graphs. The proposed approach takes advantage of hyper-dimensional computing which encodes data samples using random projections into a high dimensional space (HD space for short). Specifically, we propose a Hyper-dimensional Graph Learning (HDGL) algorithm that leverages the injectivity property of the node representations of a family of graph neural networks. HDGL maps node features to the HD space and then uses HD operators such as bundling and binding to aggregate information from the local neighborhood of each node. Results of experiments with widely used benchmark data sets show that HDGL achieves predictive performance that is competitive with the state-of-the-art deep learning methods, without the need for computationally expensive training.